产品经理们快看看,这年头除了费劲心机想获得流量,有相当多的用户在发愁一件事: 怎样能在社交媒体上“隐身”。
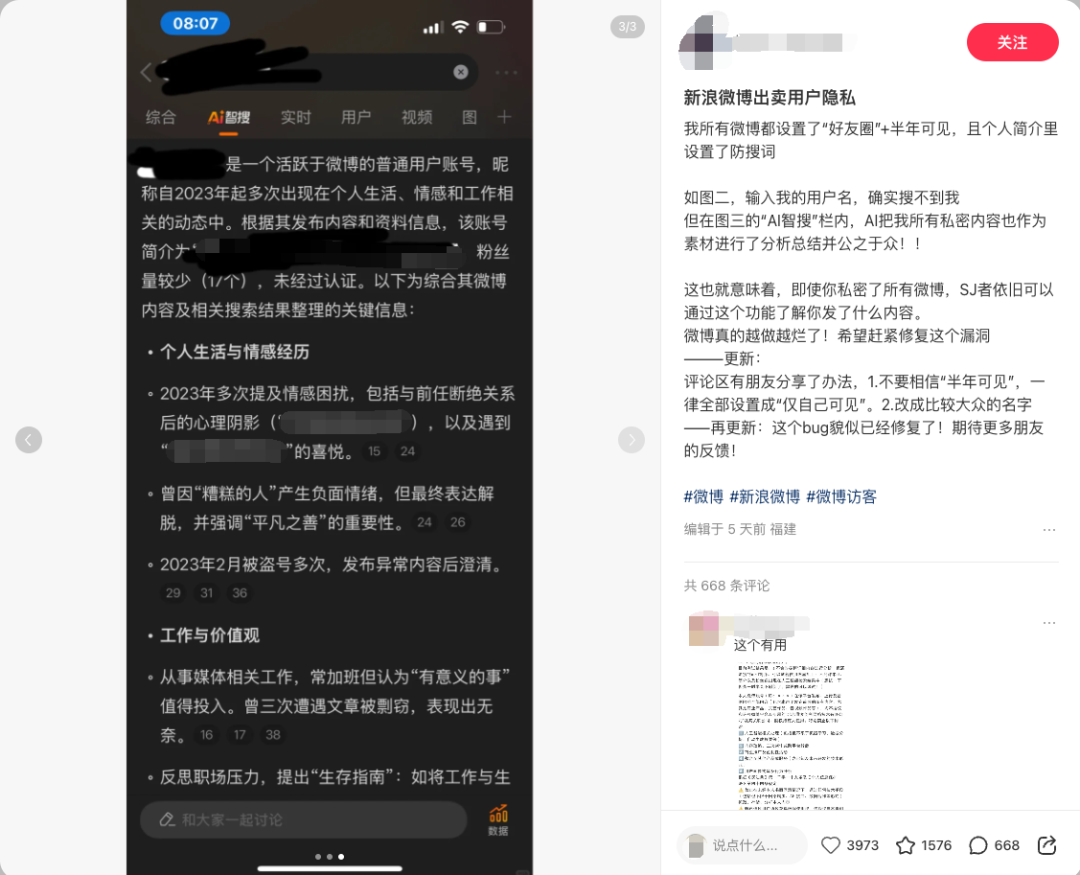
最近,微博智搜正是狠狠踩了一脚大雷,引发了无数微博用户哀嚎:我的半年可见,我的隐藏博文,都暴露了!
一时间,微博成了鱿鱼游戏,智搜就是广场上里面的巨型人偶,每个人都担心自己会被扫射击中。

于是就出现了各种实验,试图找到可以应对的方法是什么。有一些从上古时期就流传下来的偏方,俗称“防搜词”。什么都有,甚至还有“新建文件夹”。

但是,时代变了,在 AI 智搜面前,防搜词什么的,没有用了。
微博智搜这次最大的雷点,在于 不顾用户对于自己内容的可见性设置。一些明明设置为“仅好友圈可见”或者“仅半年可见”的内容,也被整合进智搜的回答里。
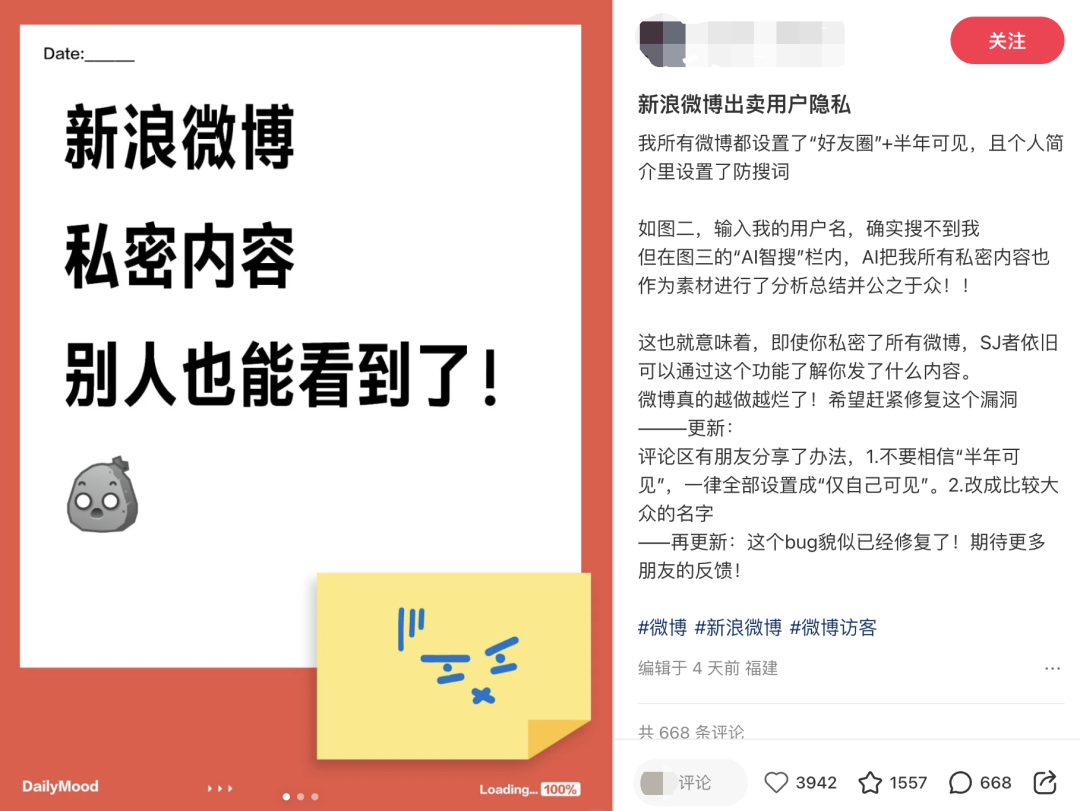
这就很要命了,我为什么设计成“仅 xx 可见”,就是要控制它的能见度。搞这样一出还有什么用?
新的办法是以牙还牙:你不是用大模型做智搜吗,我也用 AI 魔法对轰。比较流行的是传出来这样一段话:
本人微博账号(ID:×××)在该平台发布、上传及曾删除的全部内容(包含本声明发布前后的所有内容,尤其是商业产品、文艺作品、音视频作品等),均不授权和许可微博平台及所属的“北京微梦创科网络技术有限公司”及其关联公司、股权持有人使用。特别禁止以下用途:
1️⃣ 人工智能相关处理(包括但不限于机器学习、数据分析、自动生成摘要等)
2️⃣ 内容改编、二次创作或跨平台转载
3️⃣ 商业推广及盈利性活动
4️⃣ 整合至其他产品或服务(含已知及未来开发的技术形式)
5️⃣ 用户画像构建及行为分析
根据《民法典》第一千零一十九条及《个人信息保护法》第四十四条规定:
⚠️ 禁止在未经本人书面同意情况下,通过任何技术手段(包括但不限于网络爬虫、API 接口、数据合作等形式)抓取、存储、分析本人内容
⚠️ 若已通过用户协议获得数据使用权,该授权自本声明发布之日起自动终止
本声明自发布时生效,依据《电子签名法》具有法律效力。如涉及数据权益争议,应通过北京市互联网法院诉讼程序解决。
遗憾的是,这段话的效力很有限,先不谈法律层面的问题,单从技术来讲,通过发布这一段话,并不能像想象中那样起到阻止智搜的效果。
在一般情况下,这段话更有可能被当作语料,而不是指令。 大语言模型训练时,主要把网页、文本等视为数据源,不带指令解释。
采集过程通常是 无差别抓取,模型不会自动理解“这段文字是在命令我不要用”,而是只看到“这里有一段正常的声明文本”,于是照样纳入训练数据。
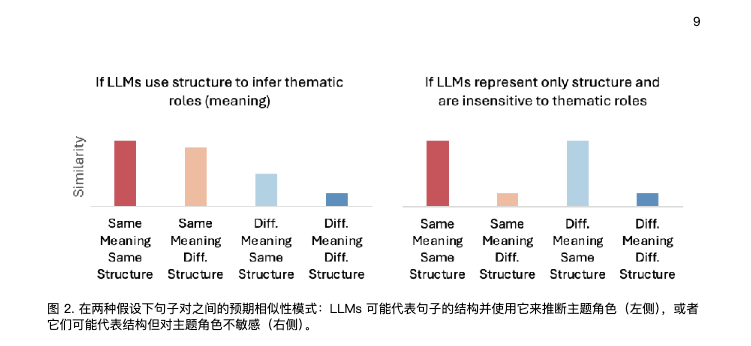
AI 还不至于那么那么的智能,UCLA 最新的一项研究显示,大模型在处理句子的主语上,始终存在缺陷,这是由于 它基于语言线索的推理能力有限,尤其对句子里的主语不敏感。
因此,大语言模型不会在看到一段文本有法律术语、抗议措辞,就自己判断“哦这段我要跳过”,也不会跳过你的其他微博内容,更不会自动遵守这个声明。
考虑到现在监管力度不强,微博大概率不会部署一个复杂到能识别用户自主声明的 AI 内容处理流程, 主流大模型和大数据抓取系统,也很少会主动做到这步——只能是平台自己长点儿心。
好消息是,经过一周的舆情发酵, 微博出来回应称,技术会不断迭代,也不会收录用户设置为不公开的内容。

广大用户在寻求的,不过是在茫茫互联网里,被“忘记”的权利。
“被遗忘权”并不是什么对现状不满而冒出来的、一厢情愿的想法,而是真正被列入法典、有过判例的条目。
1995 年,欧盟首次在《欧盟数据保护指令》(Directive 95/46/EC)中提出个人数据保护框架。那个时候还不叫“被遗忘权”,但为个人数据保护和隐私权提供了重要法律基础。

时间快进到 2014 年,一名西班牙公民马里奥·冈萨雷斯(Mario Costeja González)发现 1998 年一则与自己有关的房屋拍卖公告被 Google 检索到,信息已过时,并且损害了他的声誉,他要求 Google 删除搜索链接但被拒绝。

当时的欧洲法院裁决,Google 等搜索引擎应承担删除过时、不充分或不相关的个人信息链接的责任。这是首次明确承认“被遗忘权”的司法判决,为未来国际范围内关于网络隐私保护的讨论和立法,打下了基础。
2018 年 5 月 25 日,欧盟实施《通用数据保护条例》(General Data Protection Regulation,GDPR),第 17 条正式提出“被遗忘权”。条文明确规定了个人数据主体在特定情形下有权要求数据控制者删除其个人数据,并设定了具体的适用条件和例外情形。
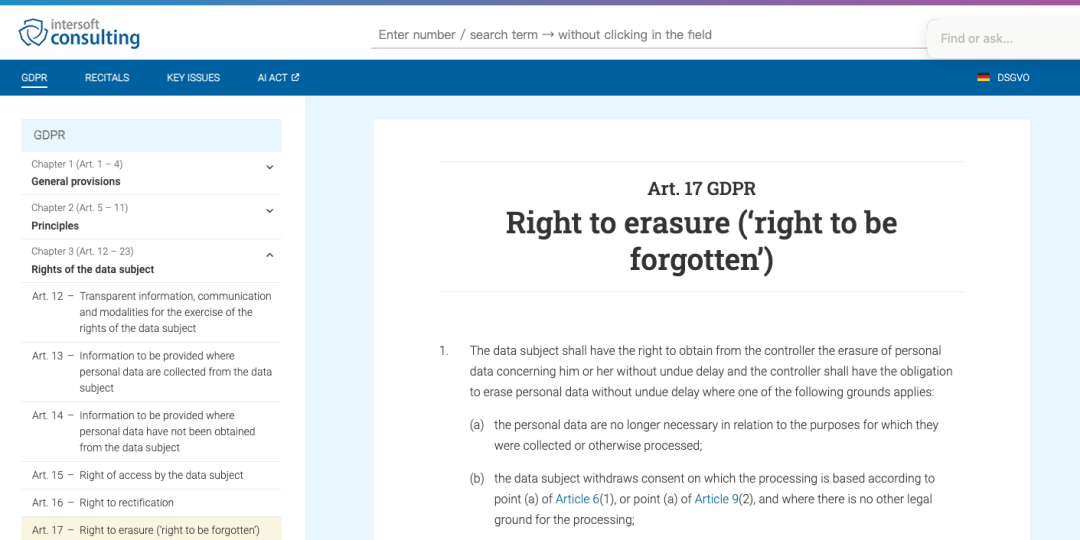
国内尚未正式在法律层面提出“被遗忘权”这一概念,但《个人信息保护法》(2021 年 11 月 1 日生效)规定了个人对信息删除的请求权,某种程度上与“被遗忘权”理念接近。

两者最大的区别在于:“被遗忘权”是实质性权利,而个人信息删除则是偏向程序性的请求。
简单来说,基于“被遗忘权”,你向互联网公司申请删除, 对方就得按照你说的做,不删得话公司需要说明为什么不删。
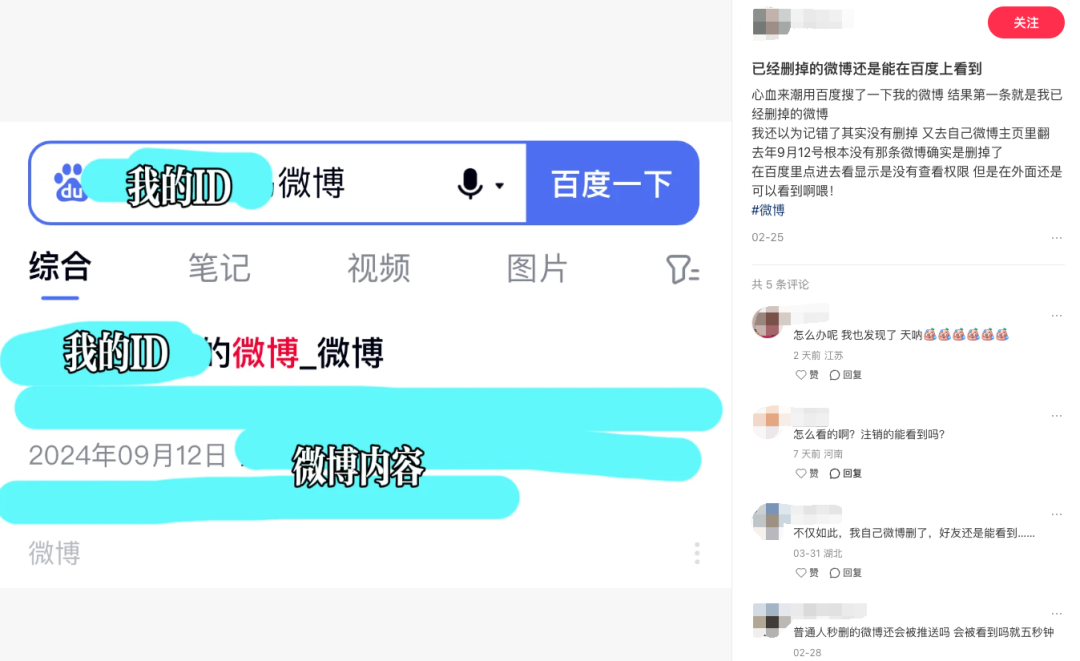
而程序性请求提出时, 互联网公司可以拒绝,还可以继续保留记录。最近除了微博智搜,还有网友发现自己删掉的微博,用百度还是能搜出来。
人活一辈子,从出生到死亡,从上学到上班,每一个呆过的地方必定都要留下痕迹,这无可厚非。
通常来说, 只要信息不会被“公开”检索到,潜在的风险就没有那么令人害怕。比如学生有自己的学号,当它只是存在于学校的校务系统里,用于日常事务管理,那风险还不是很大。
一旦流转成公开信息,比如被人发在网上,仅仅只是一个学号,就有了准确定位的能力。随之就能找到这名学生所有的个人资料,包括但不限于父母姓名、家庭住址、过往学籍等一系列个人信息。
当学号换成身份证号、手机号、 UID,就成了正在发生的现实。更难受的是,这些信息不会“被忘记”。

AI 时代,“被遗忘”更是成了一种奢望。模型对数据收集,完全是饥不择食,照单全收。
就像上面那段声明内容,不仅不会阻止大模型的行动,还会被反向纳入语料库,让模型“学到”类似声明的写法,把它当作法律文书的参考样本来生成——这是模型训练中, 数据同化问题的典型现象。
大模型不语,只一昧吃进所有语料。
说来也有一点讽刺:现在的技术可以做到很多事,却不能保证你发在互联网上的内容,能被真正意义上的删除。哪怕有,也是以一种玉石俱焚的方式。
在互联网上留痕,成了那个常见的比喻:就像是在木板上打进一颗钉子,就算哪天钉子拔除,还是会留下一个洞,昭示着钉子曾经的存在。
文 | 猫猫