
今年 3 月,英伟达 2025 春季 GTC 大会,理想汽车自动驾驶技术研发负责人贾鹏在台上介绍了他们的最新成果:MindVLA 大模型。
这是一个拥有 22 亿参数的视觉-语言-动作(Vision-Language-Action Model,VLA)模型,贾鹏进一步介绍称,他们已经成功将该模型部署于车端。在理想看来,VLA 模型是解决 AI 与物理世界交互难题最有效的方法。
在过去的一年里,端到端架构成为智能驾驶领域的技术热点,推动车企从传统的分模块规则设计转向一体化系统。曾凭借规则算法领先的车企面临转型阵痛,而后发者则抓住了弯道超车的机会。
理想便是其中的代表。
理想去年在智能驾驶上的进步可谓飞快,7 月份就率先实现了全国无图 NOA(导航辅助驾驶),还推出了独特的“端到端(快系统)+VLM(慢系统)”架构,受到行业广泛关注。

今晚,随着理想 AI Talk 第二季进行,我们对李想口中的“人工智能公司”有了更深的了解。
是“司机大模型”,也是你的司机
理想汽车 CEO 李想第一次提到 VLA,是在去年 12 月的与腾讯新闻科技主笔张小珺对谈的 AI Talk 第一季上。当时他说:
我们在做的理想同学和自动驾驶,按照行业的标准其实是分割开的,处于早期阶段。我们做的 Mind GPT,其实是大语言模型;我们在做的自动驾驶,我们自己内部叫行为智能,但是像李飞飞(斯坦福终身教授、前 Google 首席科学家)的定义,叫空间智能。只有你真正大规模去做的时候,你才知道,这两个之间,有一天一定会连在一起,我们自己内部叫 VLA(Vision Language Action Model,视觉语言行动模型)。
李想认为,基座模型到一定时刻一定会变成 VLA。原因在于,语言模型只能通过语言和认知去理解三维的世界,这是显然不够的。“它需要真正向量的,用 Diffusion(扩散模型)的方式,用生成的方式(去认识世界)”。
可以说,VLA 的诞生,既是对语言智能和空间智能深度结合的一次大胆尝试,也是理想汽车对“智能汽车”概念的一次重新诠释。

李想在今晚的 AI Talk 中进一步定义:“VLA 是一个司机大模型,像人类的司机一样去工作。”它不仅是一项技术,更是一个能与用户自然沟通、自主决策的智能伙伴。
那么,VLA 究竟是什么?核心其实非常直白:通过整合视觉感知、自然语言理解和动作生成能力,让车辆变成一个能与人沟通、能自己做决定的“司机 Agent”。

▲ 导航走 ETC 时,驾驶员可以直接命令系统走人工通道(辅助驾驶开启状态)
想象一下,你坐在车里,随口说一句“今天有点累,开慢点吧”,车辆不仅能听懂你的意思,还会调整速度,甚至选择一条更平稳的路线。这种自然流畅的交互,正是 VLA 想要实现的。李想透露,所有的短指令,都有由车端直接处理,复杂指令则交由云端 32 亿参数模型解析,确保高效与智能兼得。

实现这样的目标并不容易。VLA 的特别之处在于,它把视觉、语言和动作三个维度打通了。用户的一个简单指令背后,可能涉及到对周围环境的实时感知、对语言意图的精准理解,以及对驾驶行为的快速调整,三者缺一不可。
而 VLA 的厉害之处就在于,它能让这三者无缝协作。
从愿景到现实,VLA 的研发是一片无人区。李想坦言:“视觉和动作数据的获取最为困难,没有公司能替代。”
要理解 VLA 的技术底色,还得看看理想汽车在智能驾驶上的演进脉络。
李想表示,早期的系统是“昆虫级别”智能,仅有百万参数,靠规则和高精地图驱动,遇到复杂路况就束手无策。后来,端到端架构和视觉-语言模型让技术跃升至“哺乳动物级别”,摆脱地图依赖,全国无图 NOA 成为现实。
实际上,这一步已经让理想汽车走在了行业前列,但他们显然不满足于此。在李想看来,VLA 的出现,标志着理想汽车的智能驾驶技术迈入了“人类智能”的新阶段。

相比之前的系统,VLA 不仅能感知 3D 物理世界,还能进行逻辑推理,甚至生成接近人类水平的驾驶行为。
举个简单的例子,假设你在一条拥堵的街道上说“找个地方掉头”,VLA 不会机械地执行指令,而是会综合路况、车流和交通规则,找到一个最合理的时间和位置完成掉头。
李想表示,VLA 能通过生成数据快速适应新场景,哪怕初次遇到复杂修路,三天内也能优化应对。这种灵活性和判断力,正是 VLA 的核心优势。
理想的老师,是 DeepSeek
支撑 VLA 的,是理想汽车自研的一套复杂而精妙的技术体系。这套体系让汽车不仅能“看懂”世界,还能像人类司机一样思考和行动。
首先是 3D 高斯表征技术,即用很多个“高斯点”来拼出一个 3D 物体,每个点都含有自己的位置、颜色和大小等信息。这项技术通过自监督学习,利用海量真实数据训练出一个强大的 3D 空间理解模型。有了它,VLA 就能像人一样“看懂”周围的世界,知道哪里是障碍物,哪里是可通行区域。

▲当记忆车位被占,系统会自动寻找其他车位。还能听懂驾驶员指令,通过墙上的指示牌找到“C3 区”
接着是混合专家架构(MoE),该架构由专家网络、门控网络和组合器组成。当模型参数超过千亿级别时,传统方法会让所有神经元参与每个计算,比较浪费资源,MoE 架构中的门控网络会根据任务的不同调用不同的专家,保证激活参数不会大幅增加。
聊到这里,李想还顺带夸了一下 DeepSeek:
DeepSeek 运用了人类的最佳实践…… 他们在做 DeepSeek V3 的时候,其实 V3 也是一个 MoE 的,671B 的一个模型。我觉得 MoE 是个非常好的架构。它相当于把一堆专家组合在一起,然后每一个是一个专家能力。
最后,理想为 VLA 引入了稀疏注意力机制(Sparse Attention) ,说人话就是 VLA 会自动调整关键区域的注意力权重,从而提升端侧的推理效率。
李想表示,在这个新的基座模型训练过程中,理想的工程师们花了很多时间去找到最佳的数据配比,融入了大量 3D 数据和自动驾驶相关的图文数据,并减少了文史类数据的比例。
从感知到决策,VLA 借鉴了人类思维的快慢结合模式。它既能快速输出简单的动作决策,比如紧急避让,也能通过短思维链进行“慢思考”,应对更复杂的场景,比如临时规划一条绕开施工区域的路线。为了进一步提升实时性,VLA 还引入了投机推理和并行解码技术,充分利用车端芯片的算力,确保决策过程快而不乱。
在生成驾驶行为时,VLA 用到了 Diffusion 模型和基于人类反馈的强化学习(RLHF)。Diffusion 模型负责生成优化的驾驶轨迹,而 RLHF 则让这些轨迹更贴近人类习惯,既安全又舒适。比如,VLA 会在转弯时自动减速,或者在并线时留出足够的安全距离,这些细节都体现了对人类驾驶行为的深度学习。

世界模型是另一关键技术,理想通过场景重建和生成,为强化学习提供了高质量的虚拟环境。李想透露,世界模型将验证成本从每万公里 17-18 万元降至 4000 元。它让 VLA 在模拟中不断优化,应对复杂场景如履平地。
说到训练,VLA 的成长过程也颇有章法。整个流程分为三个阶段:预训练、后训练和强化学习。“预训练像学习知识,后训练像驾校学车,强化学习像社会实践。”李想说。
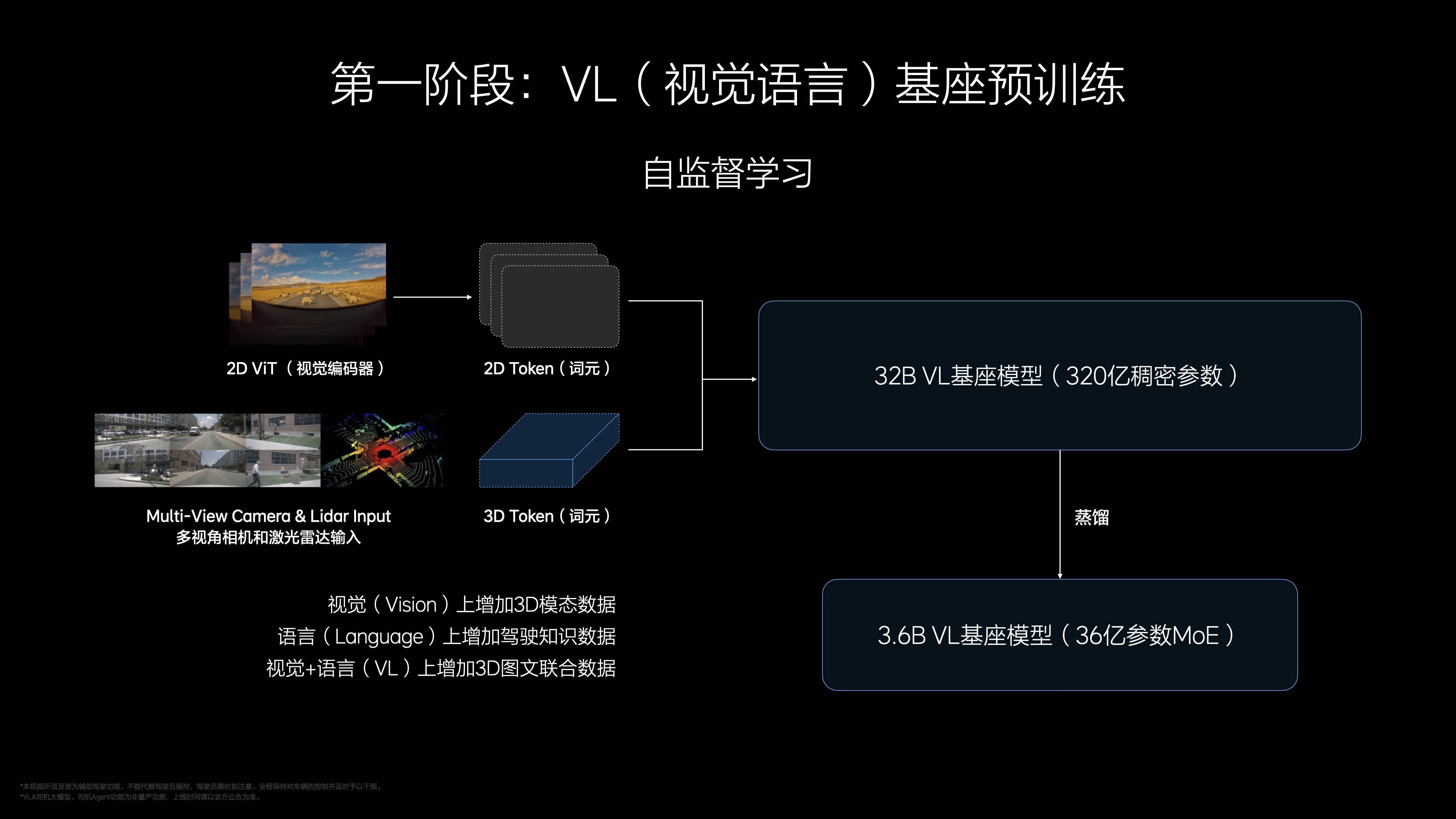
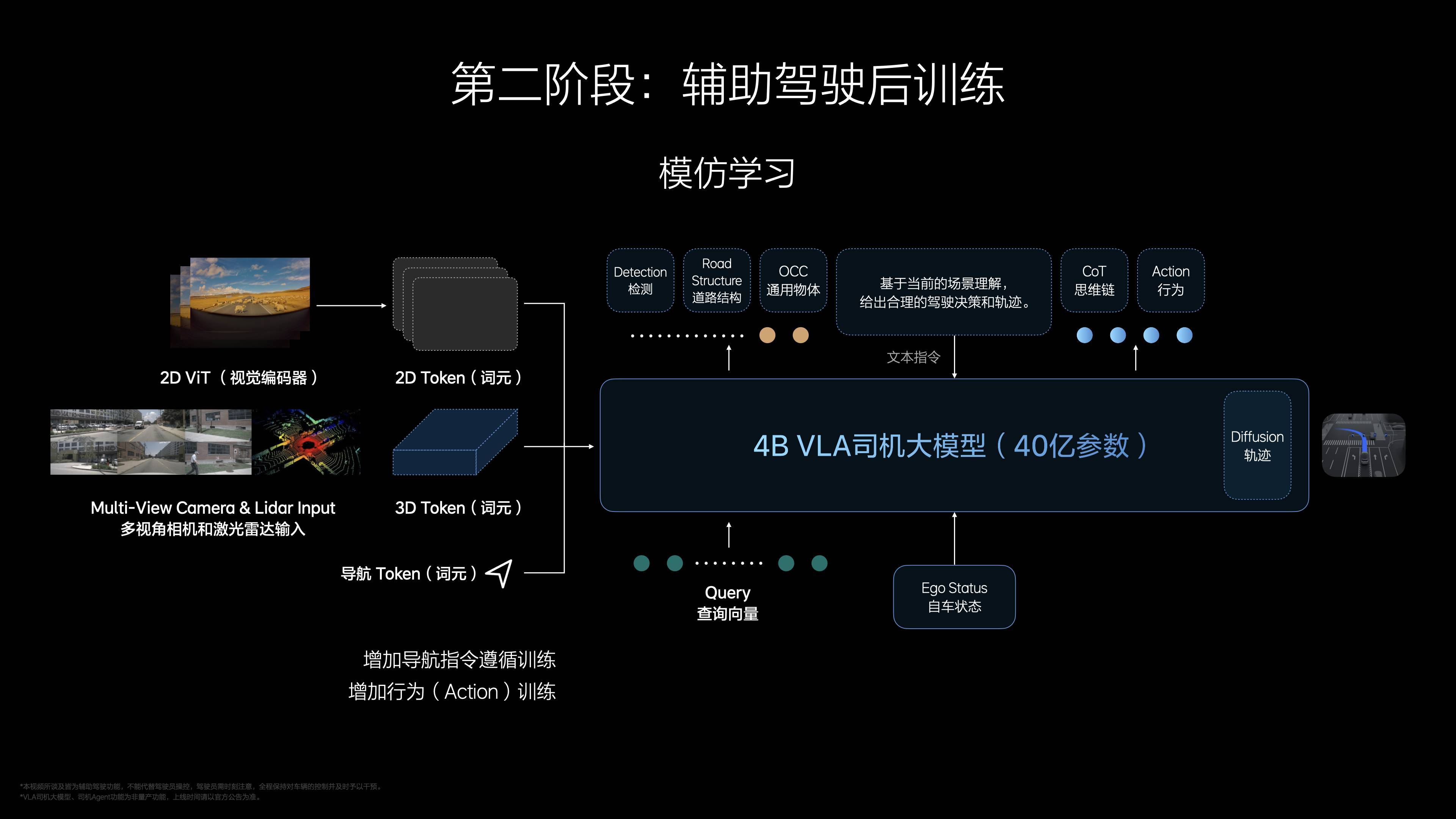
预训练阶段,理想汽车为 VLA 打造了一个视觉-语言基座模型,塞进了丰富的 3D 视觉数据、2D 高清影像和驾驶相关的语料,让它先学会“看”和“听”;后训练加入动作模块,生成 4-8 秒驾驶轨迹,模型从 3.2 亿参数蒸馏到 4 亿。
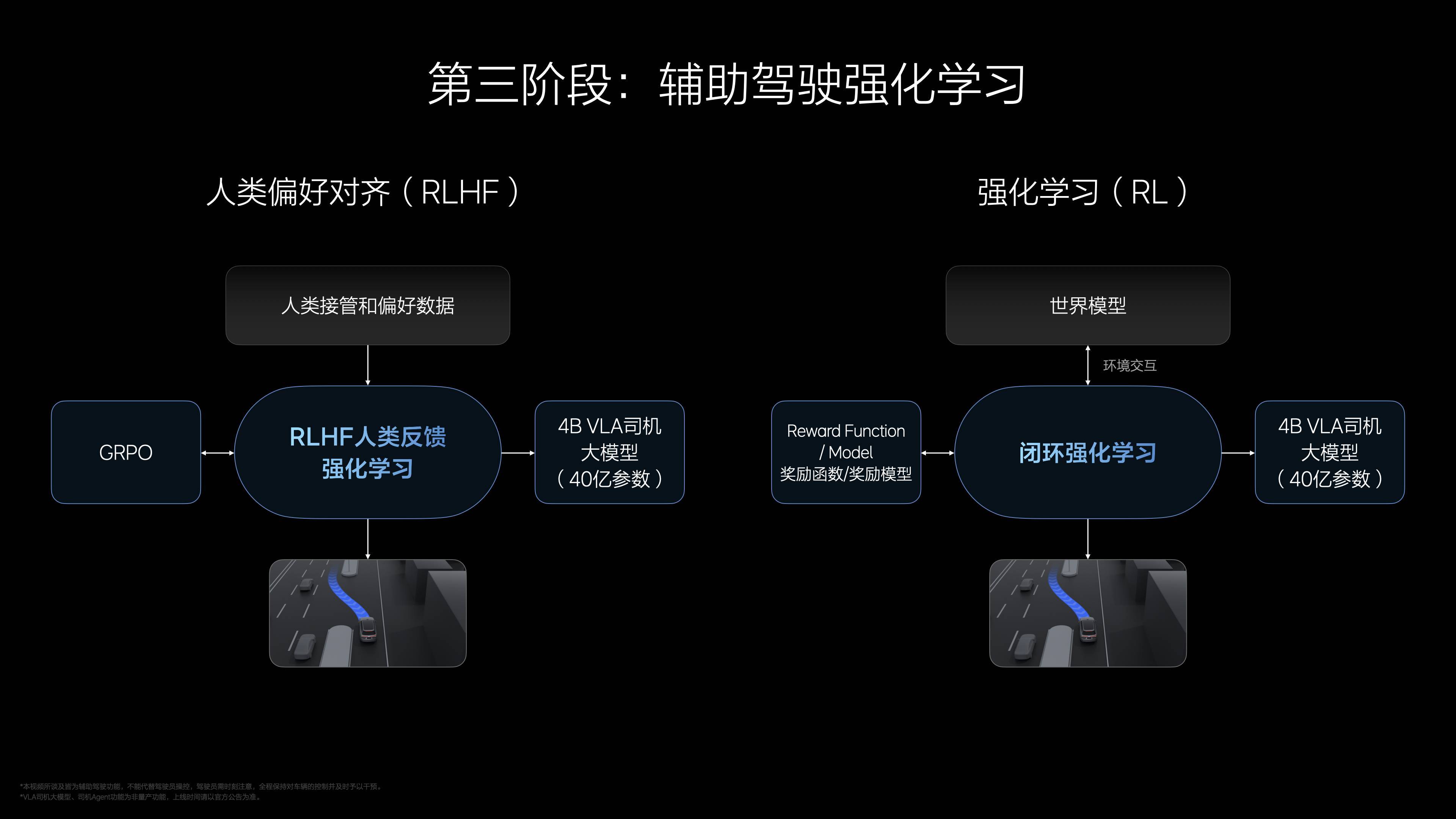
强化学习分为两步:先用 RLHF 对齐人类习惯,分析接管数据,确保安全舒适;再用纯强化学习优化,基于 G 值(舒适性)、碰撞和交通规则反馈,让 VLA“开得比人类更好”。李想提到,这一阶段在世界模型中完成,模拟真实交通场景,效率远超传统验证。
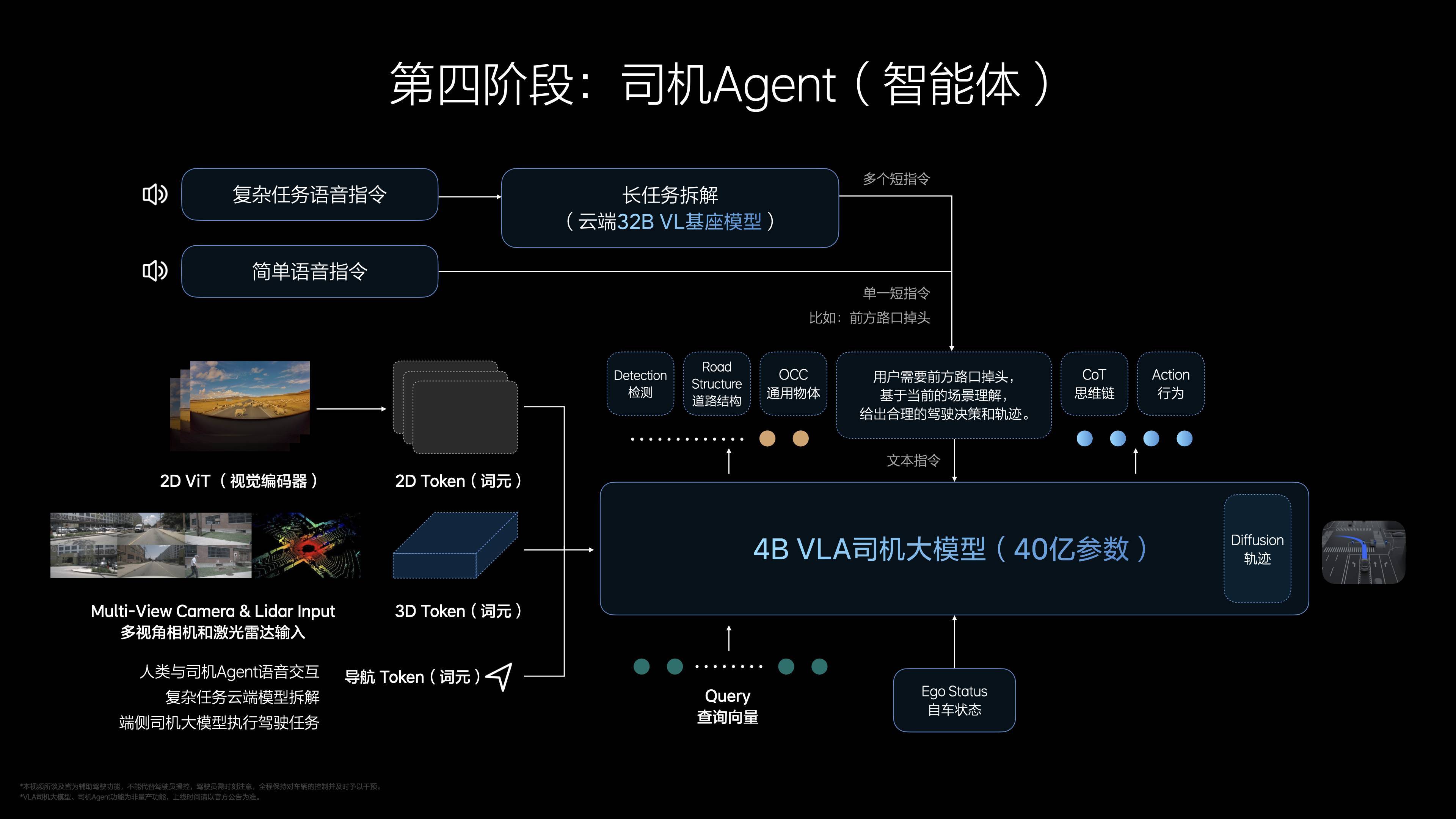
这样的训练方式,既保证了技术上的先进性,也让 VLA 在实际应用中足够可靠。
李想坦言,VLA 的成功离不开行业标杆的启发。DeepSeek 的 MoE 架构不仅提升了训练效率,还为理想提供了宝贵经验。他感慨:“我们站在巨人的肩膀上,加速了 VLA 的研发。”这种开放学习的态度,让理想在无人区中走得更远。
从“信息工具”到“生产工具”
当下,AI 行业正经历一场从“信息工具”到“生产工具”的深刻变革。随着大模型技术的成熟,AI 不再局限于处理数据和提供建议,而是开始具备自主决策和执行任务的能力。
李想在 AI Talk 第二季中提出,AI 可分为信息工具(如搜索)、辅助工具(如语音导航)和生产工具。他强调:“人工智能变成生产工具,才是真正爆发的时刻。”随着大模型技术成熟,AI 不再局限于处理数据,而是开始具备自主决策和执行任务的能力。
这种趋势,在“具身智能”概念中体现得尤为明显——AI 系统被赋予物理实体,能够感知、理解并与环境互动。

理想汽车的 VLA 模型正是这一趋势的生动实践。它通过整合视觉、语言和动作智能,将汽车打造成一个能够自主驾驶、与用户自然交互的智能体,完美诠释了“具身智能”的核心理念。
只要人类会雇佣专业司机,人工智能就能成为生产工具。当 AI 成为生产工具时,人工智能才会真正爆发。
李想的这段话,点明了 VLA 的核心价值——它不再是简单的辅助工具,而是能够独立执行任务、承担责任的“司机 Agent”。这种转变,不仅提升了汽车的实用价值,也为 AI 在其他领域的应用打开了想象空间。
李想对 AI 的思考,总是带着一种跳出框框的视角。他还提到:“VLA 不是突变的过程,是进化的过程。”这句话精准概括了理想汽车的技术路径——
从早期的规则驱动,到端到端的突破,再到如今 VLA 的“人类智能”水平。这种进化思维,不仅让 VLA 在技术上更具可行性,也为行业提供了可借鉴的范式。相比一些一味追求颠覆的尝试,理想的务实路径或许更适合复杂的中国市场。
从技术到信念,理想的 AI 探索并非坦途。李想坦言:“我们在 AI 领域经历了很多挑战,就像黎明前的黑暗,但我们相信,坚持下去就会看到光。”VLA 的研发面临算力瓶颈、数据伦理等难题,但理想通过自研基座模型和世界模型,逐步迎来了属于他们的技术曙光。
李想在采访中还提到,VLA 的成功离不开中国 AI 的崛起。
他表示,DeepSeek、通义千问等模型的出现让中国 AI 水平迅速接近美国。其中,DeepSeek 所秉持的开源精神尤为令人振奋,它直接直接促使理想开源星环 OS。李想称:“这不是出于公司战略考量,DeepSeek 给我们那么大帮助,我们应该为社会贡献点什么。”

在追求技术突破的同时,理想汽车并未忽视 AI 技术的安全性和伦理问题。VLA 引入的“超级对齐”技术,通过基于人类反馈的强化学习(RLHF),让模型的行为更贴近人类习惯。数据显示,VLA 的应用使高速 MPI(平均干预里程)从 240km 提升至 300km。
更重要的是,理想汽车强调打造“有人类价值观的 AI”,将道德和信任视为技术发展的基石。从更宏观的视角看,VLA 的意义还在于,它重新定义了车企这一角色。
过去,汽车是工业时代的交通工具;如今,它正在演变为人工智能时代的“空间机器人”。李想在 AI Talk 中提到:“理想以前走的是汽车的无人区,以后走的是人工智能的无人区。”理想的这种转变,为汽车行业的商业模式带来了新的想象空间。
当然,VLA 的发展并非没有挑战。算力的持续投入、数据伦理以及消费者对自动驾驶的信任建立,都是理想汽车需要面对的课题。此外,AI 行业的竞争日趋激烈,国内外巨头如特斯拉、Waymo 和 OpenAI 都在加速布局多模态模型,理想需要在技术迭代和市场推广上保持领先。“我们没有捷径,只能深耕。”李想说。
毫无疑问,VLA 的落地将是关键节点。
理想汽车计划在 2025 年 7 月与纯电 SUV 理想 i8 同步发布 VLA,并在 2026 年实现量产。这不仅是对技术的一次全面检验,更是市场的一块重要试金石。