
编辑:Aeneas 好困
绝了,刚刚曝出大瓜:去年MIT博士生一篇轰动一时的论文,很大可能是造假,目前已被MIT要求撤稿!他的造假水平高到什么程度?连诺贝尔经济学奖得主大牛导师都被骗过了。现在,导师已正式割席,大义灭亲。
去年,一篇MIT二年级博士的论文一经发表,立马惊艳了学术圈。
这篇论文通过调查一个研究材料科学的大型实验室,用详实的数据展示出,使用AI工具的科学家,如何获得了大幅的生产力提升。
甚至作者还发现,使用AI进行科学研究,产生了有趣的二级效应。

论文地址(发稿时还在):https://arxiv.org/abs/2412.17866
当时,这项研究不仅登上了各大媒体的头版,更是得到了圈内人的大量好评——“这是迄今为止关于AI对科学发现影响的最佳论文”。
|
|


甚至,作者还将论文提交给了全球最顶级的经济学期刊之一——“The Quarterly Journal of Economics”。并且表示,自己已经收到了“修改并重新提交”的通知。
这意味着,文章很可能即将发表。
结果,就在刚刚,这篇论文的导师——诺贝尔经济学奖得主Daron Acemoglu以及David Autor教授突然“大义灭亲”,公开请求撤稿。
原因是,其中的宝贵数据,很可能是作者伪造的!

现在,MIT Economics官网上已经发布正式公告,请求arXiv正式撤稿。
网友们也调侃起论文作者的导师:我们不要盲目相信高被引诺奖经济得主的判断。

MIT请求撤稿,导师大义灭亲
MIT官网表示,24年11月的这篇预印本论文发布于arXiv之后,可信性引起了质疑。
MIT已经展开了内部保密审查,得出结论——论文必须撤回。因此,MIT正式联系了arXiv和经济学顶刊,要求撤回该论文。

此前,MIT就已经让这名学生去申请撤稿了,但学生并没有听话。
甚至,学校着重强调,论文作者目前已经离校,不属于MIT。
其实,这篇论文在去年底发表后,立刻声名大噪,随即就引起不少质疑。
随着质疑声越来越大,论文作者的导师也开始发现不对劲了。
他们选择将此事上报,于是学校开始了内部审查。

David Autor和Daron Acemoglu
最终,学生在论文中致谢的这两位教授,联合发表了声明——
MIT经济系一名前二年级博士生的论文“Artificial Intelligence, Scientific Discovery and Product Innovation”,尽管尚未在任何经同行评审的期刊上发表,但已在AI与科学领域广为人知并被广泛讨论。
虽然学生隐私法和麻省理工学院的政策禁止披露保密审查的结果,但我们希望明确指出,我们对这些数据的来源、可靠性或有效性,以及该研究的真实性,均缺乏信心。
我们希望借此澄清事实,并表明我们的观点:在现阶段,学术界或公众在讨论这些议题时,不应采信该论文所报告的研究结果。
全文如下:

上下滑动查看
AI让新材料发现暴增44%?编的
要知道,在去年年底,这篇文章发表时,可是引起了不小的轰动。
作者提出的许多观点,实在是振奋人心:
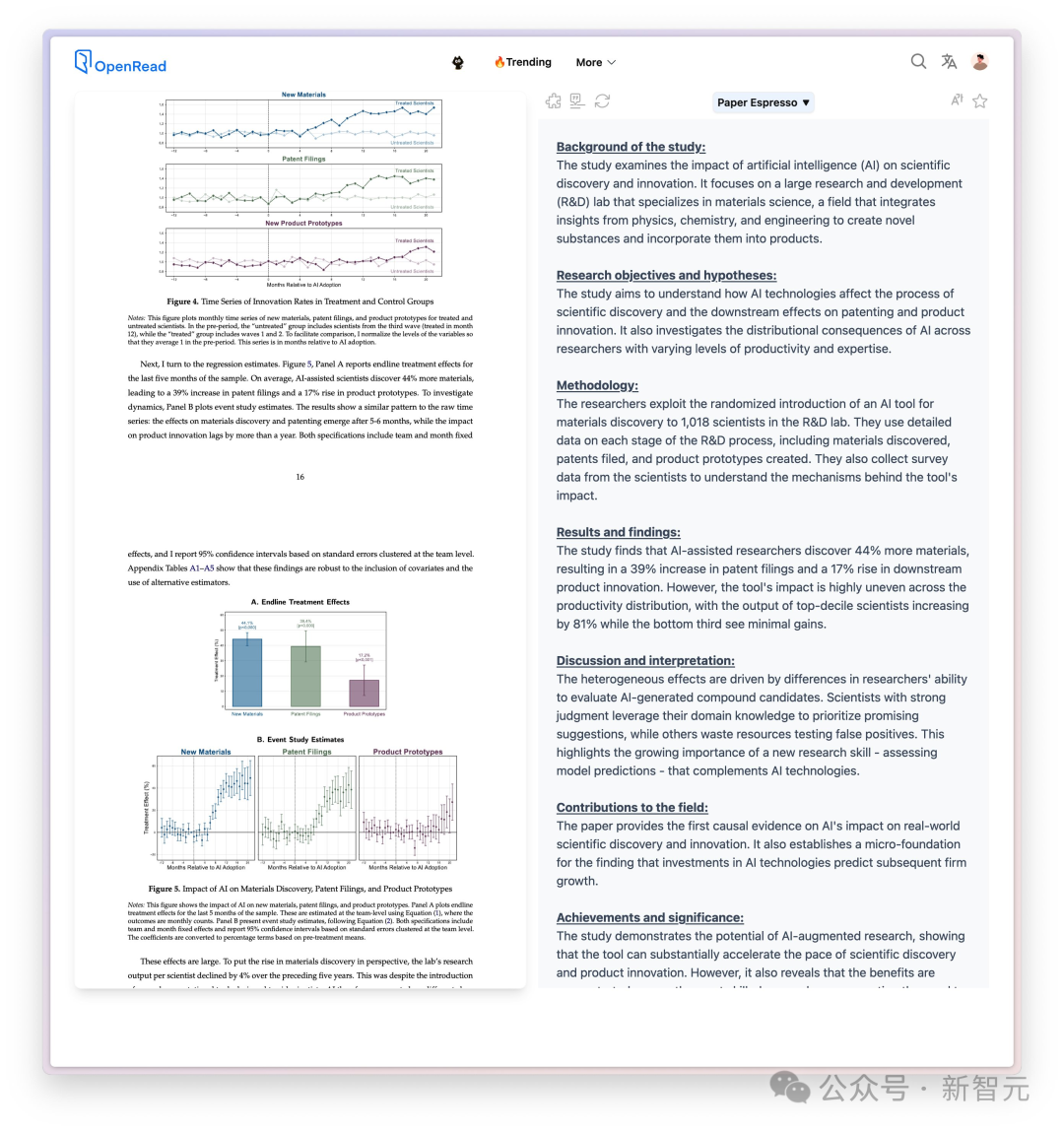
· AI正以惊人的速度推动新发现,直接让研究人员发现的材料数量增加了44%,专利申请量增加了39%,下游产品创新量增加了17%。
· AI对生产力分布的影响极不均衡,排名前1/10的科学家的产出增长了81%,而排名后1/3的科学家的产出增长却微乎其微。
· 对于表现最佳的人,AI充当了共同智能,放大了他们的创造力和产出。

论文作者Aidan Toner-Rodgers
沃顿商学院教授Ethan Mollick也转发了这篇论文。
读者们表示,这项研究太棒了!非常欢迎这种研究大模型对于科研影响的论文。
可是如今却要告诉大家,这篇论文竟是靠数据造假得来的?
事情闹得这么大,曾以题为“The Scientist vs. the Machine”的文章对此事进行报道的大西洋周刊撰稿人,也在线吃起了瓜。



UCL教授去年就曾提出质疑
其实,去年11月这篇论文一经发表,就已经有专业人士感觉到不对了。
这篇论文的造假嫌疑很大,很多人怀疑,为何此人的导师竟然让这篇论文通过。
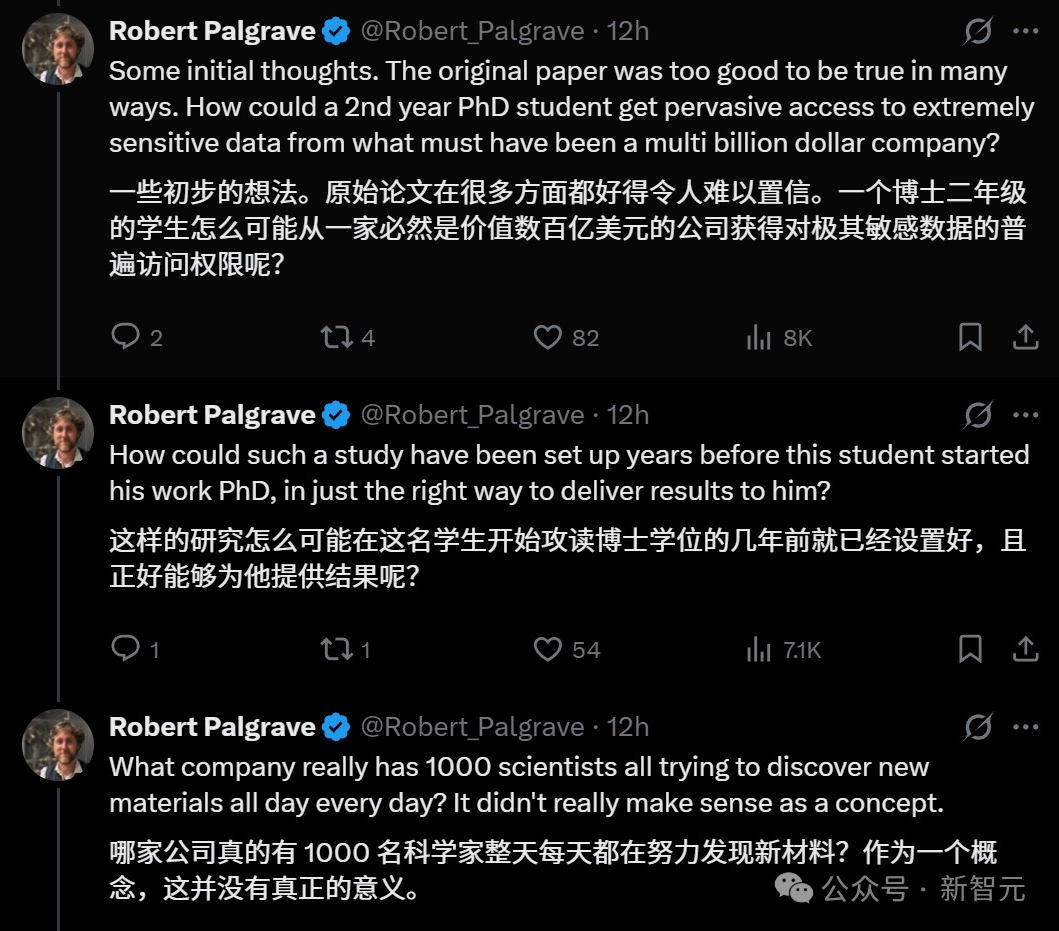
伦敦大学学院无机与材料化学教授Robert Palgrave,当时就公开怀疑:论文中的观点,很多根本就站不住脚,极其不严谨!

随后,他展开抽丝剥茧的分析。
这篇论文研究的是一家匿名的美国大公司在无机材料发现上的工作。在这家公司中,有超过1000名科学家在寻找新材料,尤其是医疗保健、光学和工业制造领域。
但是论文中,有重重疑点。
比如作者提到,该实验室从2022年就开始使用AI了。他们是多有前瞻性,才能在22年就设立一个多年的、有1000多名被试的随机对照实验?
而且,作者竟然能查阅实验室员工的记录本,这有多大的可能?
而且论文的具体细节,也有很多可疑之处。
第一个问题,实验室究竟在研究什么类型的材料?
文中没有详细说明,但提到说无机材料是重点,包括生物材料、陶瓷和玻璃、金属和合金以及聚合物。
这就奇怪了。
比如教授表示,自己不认为论文中的方法,可以将生物材料进行原子化的模拟。
陶瓷和玻璃可能包含大量的无序结构,这种结构也很难以高通量的方式进行建模,这是谷歌Deepmind的首篇材料学论文失败的原因。
金属和合金也是同理,它们是大量无序的,很难建模。
聚合物倒是有可能以这种方式建模,但如果要获得晶体结构,也是很难的一件事。
第二个问题,论文是用SOAP方法,来评估新材料是否出现在了已有数据库中,作者使用的数据库是Materials Project和Alexandra。
然而,他们却并不包括实验结构,所以作者并没有跟真实的材料进行比较,只是在跟之前的计算结果进行比较。
在这里,作者使用的判断方法并不严谨。
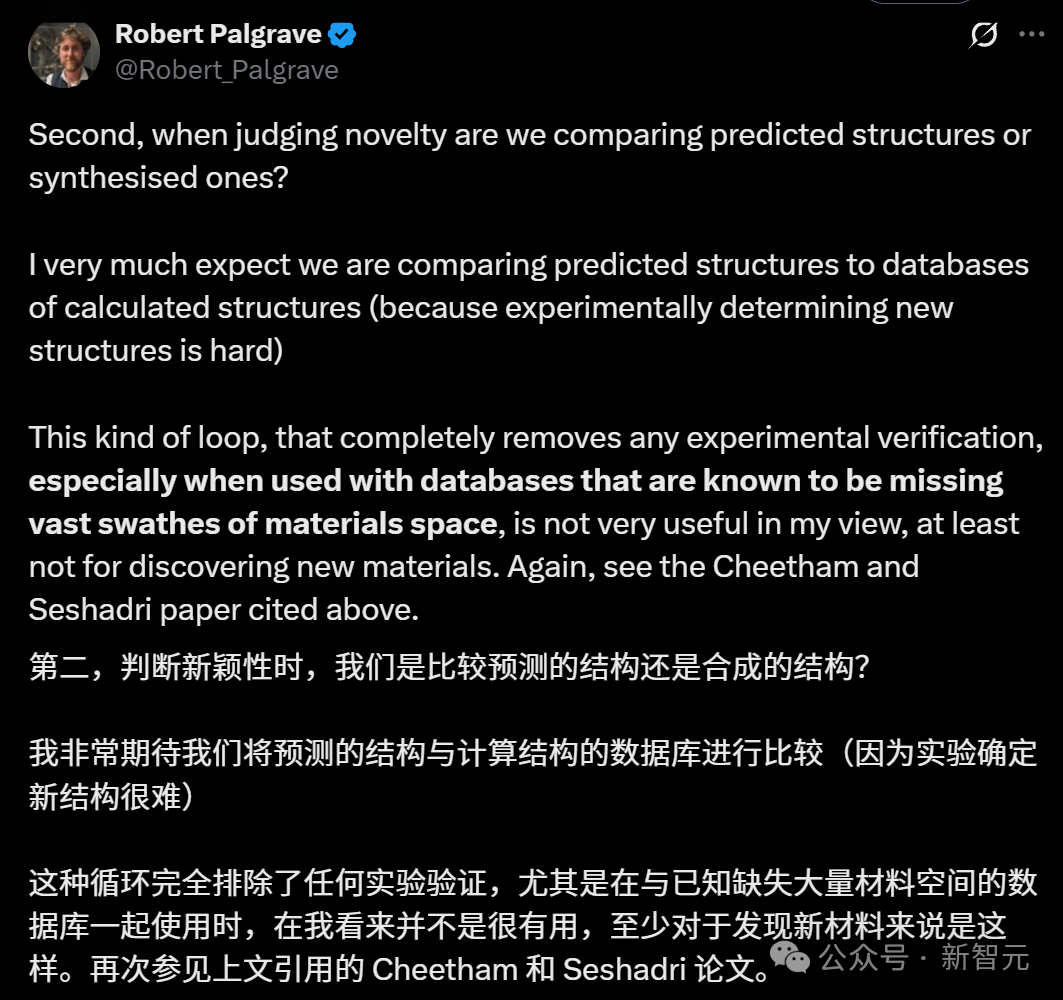
甚至,作者使用的SOAP方法,还被诡异地修改过了。
“第二项对更靠近质心的原子增加了额外权重,这反映了中心原子更能预测材料属性的事实。”
论文中的这一句,前提本身就是错误的。因为这些材料都是周期性结构,没有中心。
总之,这种新颖性指标,根本就不令人信服。
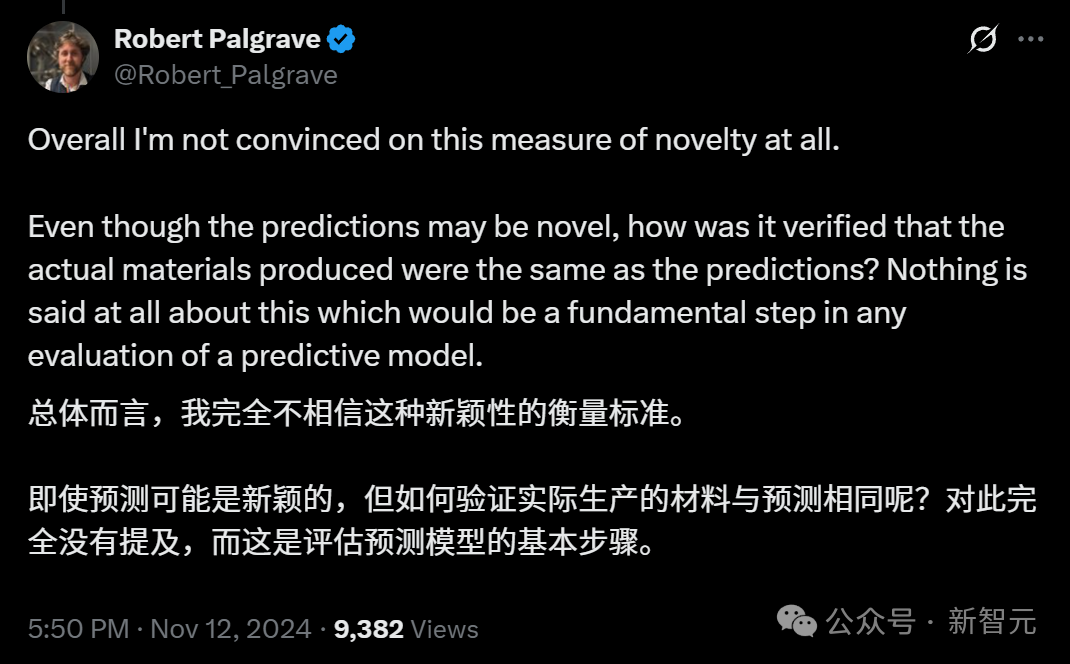

论文似乎在将AI帮助研究者发现了新材料,但如何验证,这种预测跟实际生产的材料相同呢?
另外,论文中只讲了如何将AI整合到实验流程中,但关于验证AI是否提供了实际有用的结果,却几乎没提。
最后,教授还是口下留情,赞美说这篇论文引人入胜,付出了巨大努力。也继续强调了“华点”:一个学生如何在一家大公司展开如此广泛的研究?

现在回看,这位教授果然不愧是专业人士。
毕竟外行看热闹,内行看门道。在真正专业的火眼金睛前,造假的行为总会露出蛛丝马迹,无可遁逃。
假的就是假的,真不了。
AI、材料、欺诈
同时,Robert Palgrave教授也分享了另一篇详细扒皮文,出自材料科学家Ben之手。
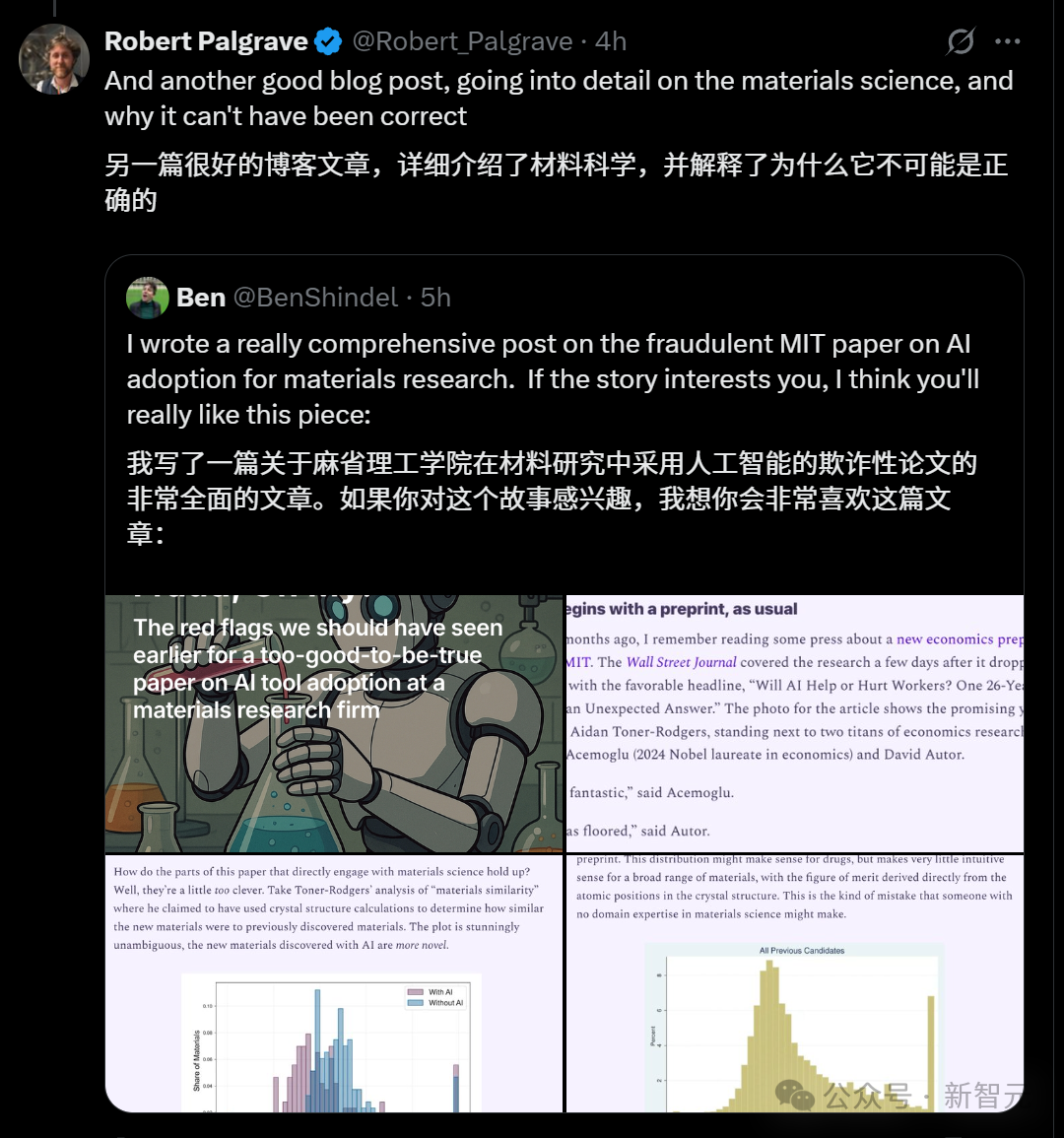
让我们跟着这位大佬一起看看,论文的“鸡脚”是从哪里露出来的。

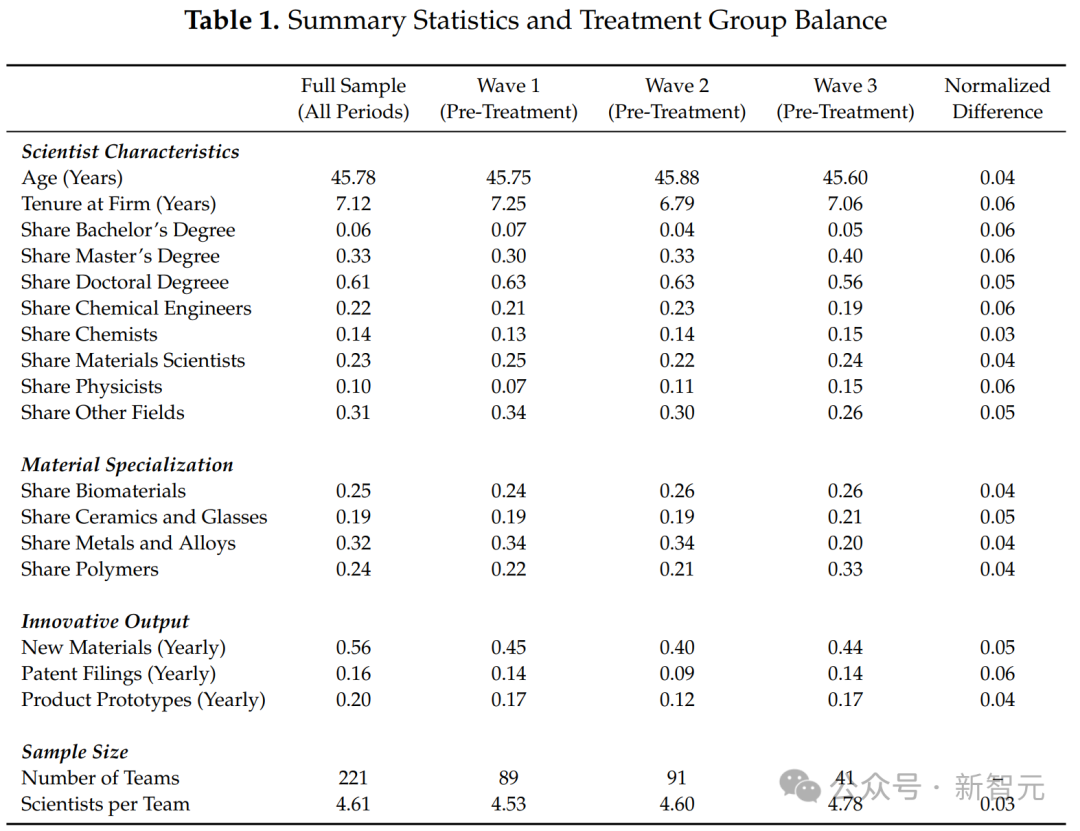
具体来说,这篇文章分析了一项随机试验的数据,其中涉及一家美国公司研发实验室的一千多名材料研究人员。
作者Toner-Rodgers熟练地追踪了这些AI工具的使用对以下方面的影响:
研究人员发现的材料数量
这些新材料申请的专利数量
基于这些新材料开发的新产品原型数量
研究人员在实验、判断和构思之间的时间分配随时间的变化
研究人员在采用AI工具前后对AI的态度
不仅这些指标中的每一个都显示出非常清晰的效果,而且作者还运用了几乎所有能想到的方法来探索它们。其中不乏一些非常复杂的方法论:
他通过一个非常精密的算法计算新材料的质量。这种算法测量的是每种发现的材料与“目标”属性之间的距离。
他通过计算原子位置的差异来测量新材料的晶体结构与现有材料的结构相似性。即使对于材料科学家来说,这也是非常困难的,更不用说经济学家了!
他使用二元语法分析来确定专利的新颖性。
他使用一个LLM(Claude 3.5)来自动分类研究任务。
数据好看得不像话
第一个本应亮起的红灯,是数据来源本身。
这是一家美国公司,仅材料发现领域就拥有(至少)1018名研究人员,数量惊人。这就将范围缩小到少数几家公司,比如苹果、英特尔和3M。
然而,论文所列出的研究人员在材料专业方向的细分情况,却非常奇怪。
因为很少有公司会进行大规模的材料研究,而且这些研究还相当均匀地分布在各种材料领域,涉及生物材料和金属合金等截然不同的领域。

经过实际调研之后可以发现,没有一家现实中的公司能完美匹配这个数据,尤其是在金属和合金领域占有32%份额这一点上。
对此,有两种可能的情况:
1. 确实有一家研发实验室提供了数据,但作者进行了篡改
2. 数据从一开始就完全是捏造的
相比之下,第二种的可能性更高,原因是:
像这样的大公司为什么要费尽周折对自己的员工进行随机试验,追踪他们绩效的多个指标,然后却把这些数据匿名提供给一位MIT的研究员,而不是自己发表研究成果?而且,这个人还只是一名博士一年级的学生。
即使在那些大型研发公司里,也只会有一小部分研究人员致力于“材料发现”这项任务。一家公司以如此结构化的方式对一千多名员工进行AI应用实验,可能性实在不大。
对这些员工所做任务的描述、领域之间的划分以及所有其他提供的信息,看起来都过于完美。真正的公司不会有数百个研发团队各自从事类似的任务,规模相近,并且都追踪相同的指标。这读起来就像是一名只读过Top 1%经济学创新研究论文的学生,对于研发实验室运作方式的想象。
下一个本应亮起的红灯,是“完美无瑕”的研究结果。
在探索的每个领域,都有一个相当明确的结果:
新材料?增加了44%(p<0.000)
新专利?增加了39%(p<0.000)
新原型?增加了17%(p<0.001)
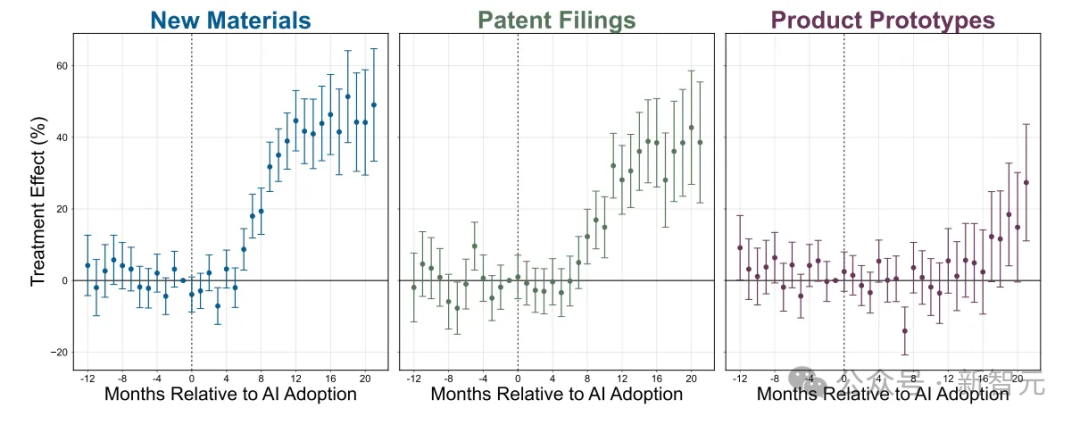
新材料的质量?提升了,并且具有统计显著性。
新材料的新颖性?提升了,并且具有统计显著性。
那些先前更有才华的研究人员在使用AI工具后进步更大吗?是的。
这些结果是否反映在研究人员对其时间分配的自我评估中?是的。
最后的图表,更是堪称每个经济学家的梦想——完美体现了比较优势原则的生效过程:
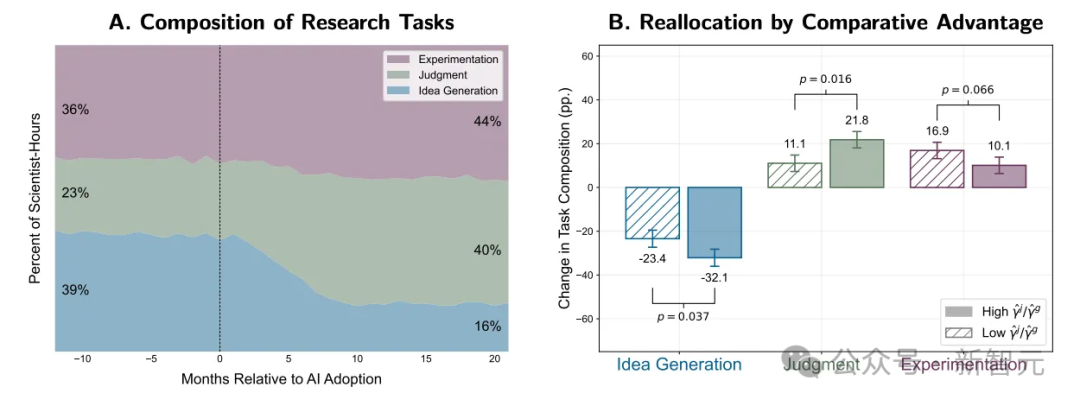
类似的,其他图表看起来也都非常的刻意和规整。
比如下面这张表,展示的就是研究人员对自己判断能力的自我评估,同他们在调查中对“不同知识领域在AI材料发现中所起作用”的反馈之间,是否存在关联。
可以看到,四类中有三类显示出规整的增长,另一类则保持不变(而这一类从基本原理来看似乎本就无关紧要,即使用其他AI评估工具的经验)。
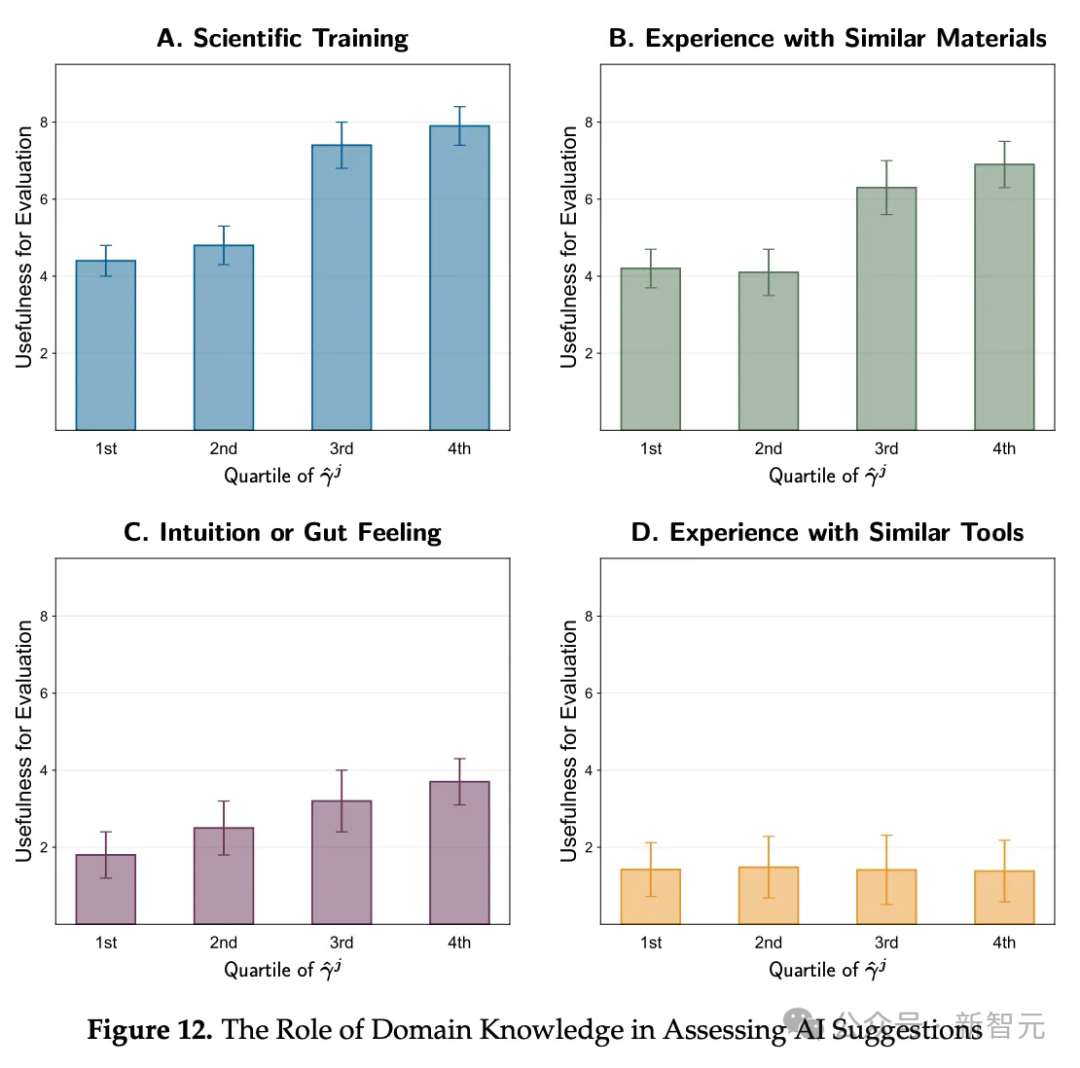
但仔细想想就会发现,这个图表也毫无道理。
为什么判断力更强的研究人员,会系统性在这项调查问题上给出更高的平均分?
问题3:在1-10分的范围内,以下各项在评估AI建议的候选材料方面有多大用处(科学训练、类似材料的经验、直觉或预感,以及类似工具的使用经验)?
然后,更绝的是,作者是这样描述公司一次幸运的裁员的,这次裁员奇迹般地没有干扰主要分析的数据收集,反而还提供了一个富有洞察力的例子来支持他的发现:
在最后的一个月,实验室解雇了3%的研究人员,并对团队进行了重组。与此同时,公司通过招聘不仅弥补了这些空缺,还实现了员工的净增长。
虽然我没有观察到新员工的能力,但那些被解雇的人更有可能判断力较弱。
图13显示了按γˆj的四分位数划分的被解雇或调岗的百分比。前三个四分位数的科学家被解雇的几率不到2%,而最低四分位数的科学家则有近10%的几率。
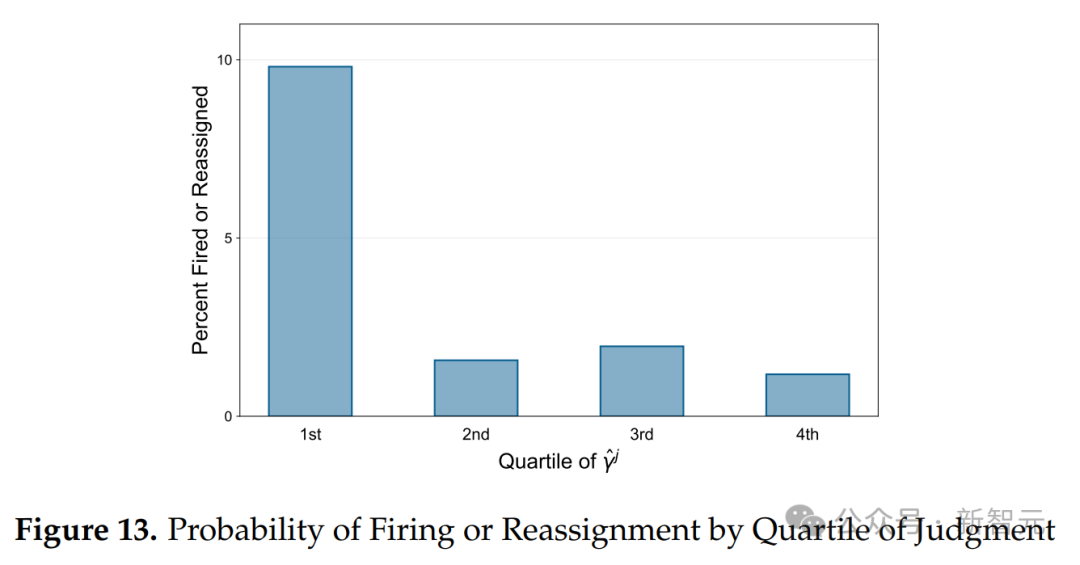
材料科学家怎么看?
这篇论文中直接涉及材料科学的部分表现如何呢?
身为材料科学家的大佬表示,它们有点过于巧妙了。
以作者对“材料相似性”的分析为例,他声称通过晶体结构计算确定了新材料与已发现材料的相似程度。其中,图表所呈现出的结果令人震惊地明确——AI发现的新材料更具创新性。
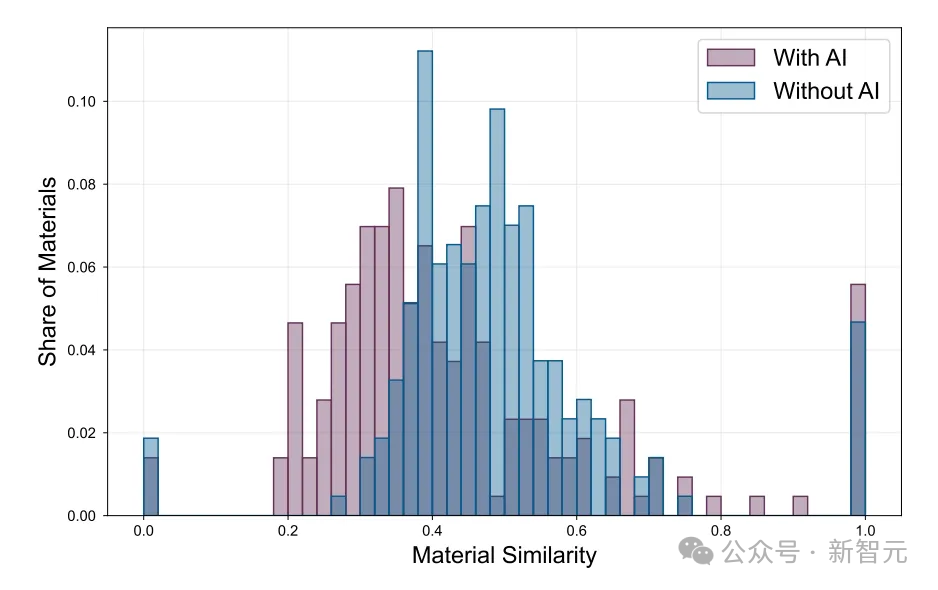
然而,令人难以置信的是,区区一名经济学学生,竟能够轻易地(而且没有提供任何进一步的细节)实施他所引用的论文“Comparing molecules and solids across structural and alchemical space”中那种高度复杂的技术。
尤其是,在没有任何计算材料研究领域专业知识的情况下,用如此精妙且规范的方式来完成这项工作。
这张图表及其代表的数据,如果是真的,其本身可能就足以发表一篇关于AI材料发现的Nature了。但在他的论文里,却仅仅被归入了附录。
然而,这种方法论在推广到不同类型的材料时,是毫无意义的。因此,也很难理解作者是如何用这种方式将如此广泛类别的材料的结果简化为单一品质因数的。
0.0到0.2以及0.8到1.0之间的空白,对于读过几篇论文的人来说可能看起来合理,但当推广到几类材料时就会显得很奇怪,因此数据很可能是完全捏造的。
举个例子,一种新型金属合金与先前发现的合金参考类别相比,其相似性水平会与一种新型聚合物与其自身参考类别相比截然不同。
这需要一些非常复杂的方法论来对不同材料类型的这个单品质因数进行归一化处理,而作者对此完全没有提及。
此外,使用来自“材料计划”(Materials Project)的数据来实现这些是异常困难的,需要极其复杂的“大数据”工作流程。
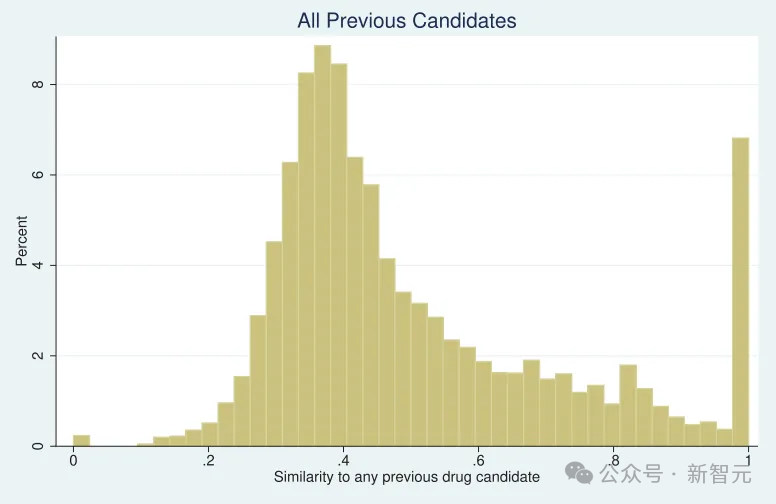
如果想要确凿的证据,可以看看论文“Missing Novelty in Drug Development”中的图表,作者也进行了引用并在药物发现中使用了类似的方法论。
可以看到,它的分布和MIT论文惊人地相似。这种分布或许适用于药物领域,但对于从晶体结构原子位置直接推导品质因数的广泛材料而言,则完全不符合常理——这正是缺乏材料科学领域专业知识的人可能会犯的典型错误。
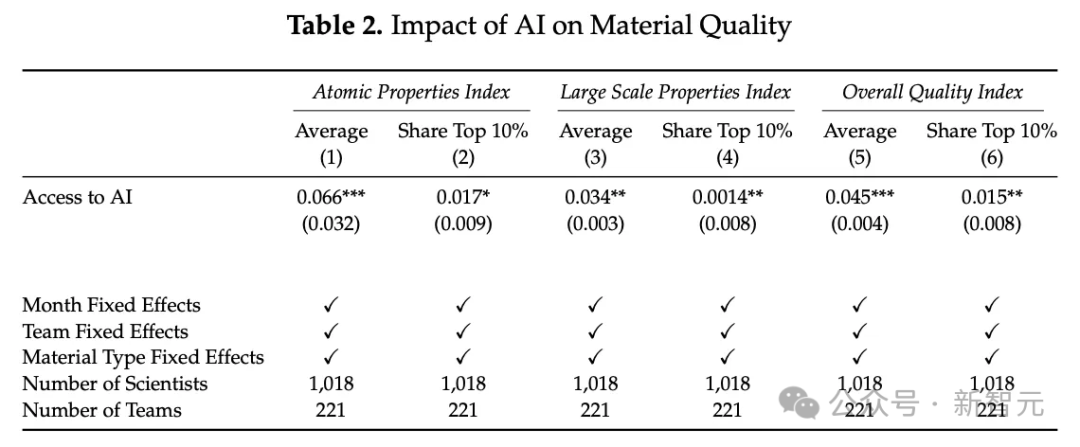
作者对“材料质量”的处理方式,甚至可能会把材料科学家逼疯。
他用来计算新材料“质量”的方程式,堪称是一个“垃圾进,垃圾出”的典范:

首先,通常没有能够轻易简化为单一数值的“目标特性”,而且,即使有,其中一些也会以对数尺度分布,这将极大地扭曲某些类别材料的数值。
此外,一个研发实验室开发的新材料的“质量”很可能与实际的关键品质因数(如作者提出的“带隙”或“折射率”)的改进完全无关。
相反,它们会是针对诸如耐久性、经济性、易于制造等方面的。这些都是不容易简化为单一数值的特性。
而且即使可以,要让研究人员系统化地测量并记录每个新材料的这些参数,说是天方夜谭都不为过。
然而,从这一堆胡言乱语中,作者还是设法得出了一个重大发现——所有1018名科学家,都在每一个类别中报告了具有统计学意义的显著结果。
这未免也太完美了。
总的来说,作者极大简化了材料工作复杂性的部分,对于大部分人来说,包括顶刊的编辑,都很难察觉出论文中的错误。
就是这样一篇造假文章,已经让作者取得了巨大声誉,险些登上顶刊。
那些没被发现,却让作者荣誉等身的造假文章,究竟还有多少呢?
参考资料:
https://economics.mit.edu/news/assuring-accurate-research-record
https://www.wsj.com/economy/will-ai-help-hurt-workers-income-productivity-5928a389
https://x.com/Robert_Palgrave/status/1923394441382903982
https://thebsdetector.substack.com/p/ai-materials-and-fraud-oh-my