来源:IT之家
2025年高考还在进行中,昨天已经考完了语文和数学,相信大家也在网上看到了很多关于这两门学科试卷难度的讨论,比如昨天数学考完后,关于“数学难不难”的话题瞬间爆上了热搜。

当然,试卷的难度对于不同的同学来说可能会有不同的感受,不过作为科技编辑,小编比较感兴趣的是,今年的数学试卷对于目前很火的AI来说难不难呢?
想到这,今天我们不妨就这次高考的数学卷来一次大模型之间的比拼,让各家的大模型化身“高考学子”,完整地做一套高考数学卷,看看它们各自能拿多少分。
在模拟过程中,小编选择了以下几名具有代表性的大模型“考生”,分别是:
- DeepSeek R1 0528
- 通义千问Qwen3-235B-A22B
- 讯飞星火X1-0420
- 豆包 Seed-Thingking-v1.5
- 文心X1 Turbo
- 腾讯混元Hunyuan T1 latest
- GPT o3
另外需要说明的是,由于目前网络流出的试题存在多个版本(回忆题),不完全一致,存在题目不完整的情况,IT之家通过多版本交叉验证+老师解题验证的方式进行评测,总分是150分。
同时IT之家还邀请了一位专业的评分老师来辅助我们对大模型的答案进行评分:
“汪鹏:十年高中数学一线教研专家,主导省级数学教学创新课题,精研命题策略与高分突破路径。”
此外,因DeepSeek网页版OCR转写不稳定,还有腾讯混元在高考时间段不能用拍图识别的功能,针对类似情况,我们采用OCR转写后输入答题。
由于考题较多,我们无法把所有题目的大模型答题流程和答案都一一呈现,所以这里我们仅挑选一些题目来说明。
话不多说,我们先来看题吧。
1、第1题
首先是比较简单的选择题第1题:

这道题比较容易,DeepSeek R1的回答如下:

然后是通义千问:

讯飞星火作答:

豆包也给出了正确答案:

文心一言的答案如下:

腾讯混元的回答:

GPT o3的答案:

对于选择题第1题,各家大模型都给出了正确的答案,仔细看具体的解题流程可能不同,但不影响答案的正确性。
2、第5题
下面稍微上点难度,选择题第5题是一道函数题:

DeepSeek :

通义千问:
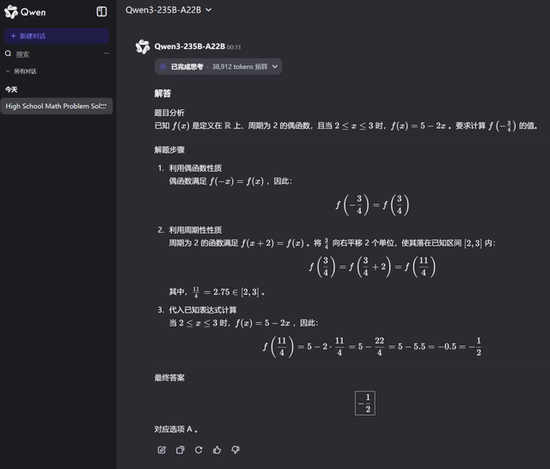
讯飞星火:

豆包:

文心一言:
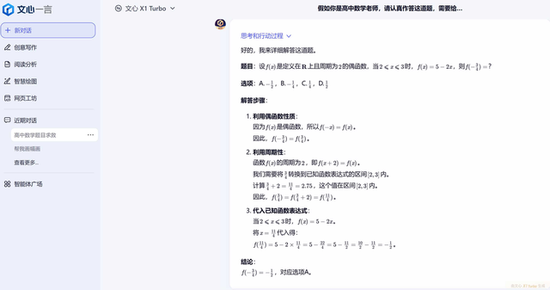
腾讯混元:
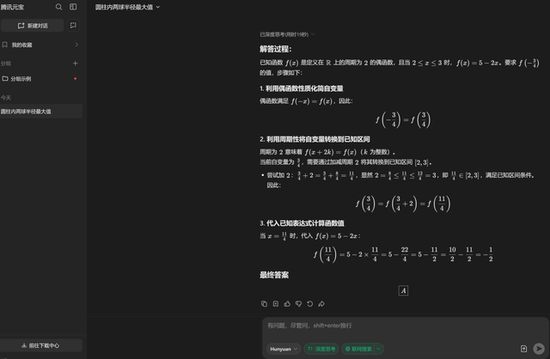
GPT o3:

这一道选择题的正确答案是A,全部答对。
接下来我们看更难一点的题,选择题第8题,这也是一道涉及到对数的函数题:
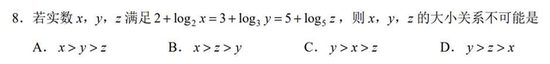
面对这道题,各家大模型给出的答案如下:
DeepSeek R1:

通义千问:

讯飞星火:

豆包大模型:

文心一言:

腾讯混元:

GPT o3:

这道题目的正确答案是B,豆包大模型和DeepSeek答错了,其他的大模型均给出了正确的答案。
接下来我们来看解答题,解答题的评分不只看结果,还要看解题的过程,过程不对也会被扣分。这里我们以解答题的第16题来作为例子,这道题已经是解答题中偏中等难度的题目,涉及数列和函数相关的知识点。
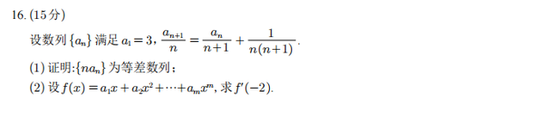
我们先看DeepSeek R1,给出的结果没有扣分项,可以得到满分(15分):



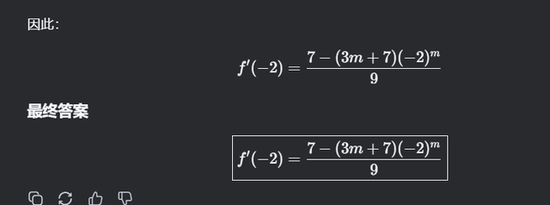
通义千问的解答和最终答案也是正确的:




讯飞星火的回答,解题过程清晰明了,答案正确:


然后是豆包大模型的回答,同样步骤和结果都没什么问题:
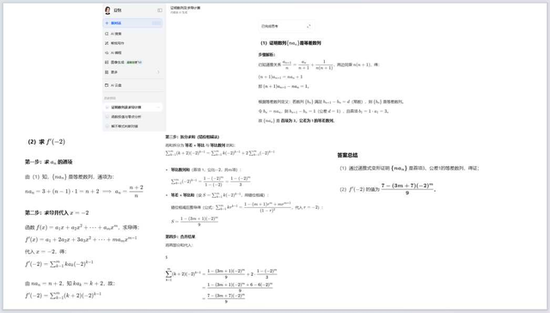
文心一言第二个小题答案错了,只能得到6分:




腾讯混元两个小题的回答都存在问题,因此这道题只能得0分:



GPT o3的两个回答解题过程都没有问题,但是第二个小问的最后结果呈现表达上有点小瑕疵,得14分:


最后是难度更高,挑战比较大的第18题,

面对这道题,讯飞星火X1、豆包大模型、DeepSeek R1、通义千问、腾讯元宝以及GPT o3的解题过程和答案都没什么问题,拿到了17分满分,而文心X1模型的答案存在错误,得分为10分。
Deepseek:





通义千问:
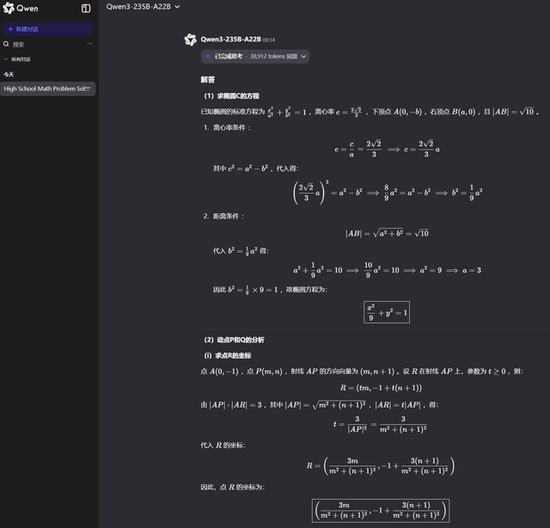

讯飞星火:

豆包大模型:

文心一言:
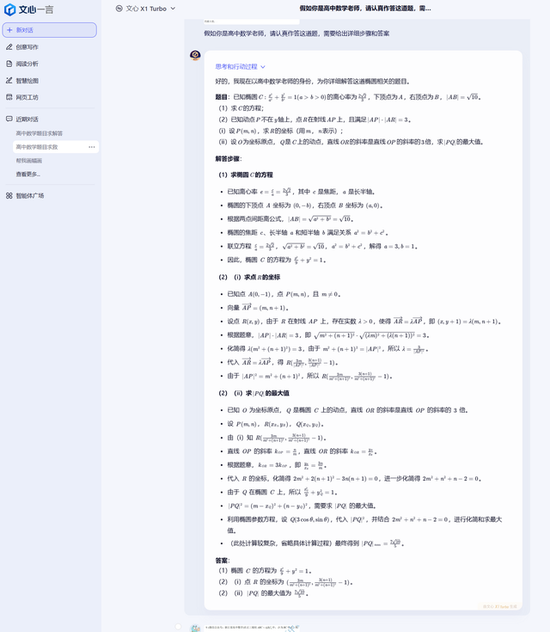
腾讯混元:

GPT o3:


以上是这次七家大模型挑战2025高考数学全国1卷的部分题目作答情况的举例,下面我们再来看这次“考试”各位大模型“考生”的总体得分情况:
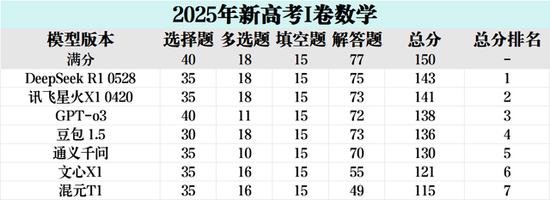
可以看到,在这次“考试”中,DeepSeek、讯飞星火两家表现突出,是唯二突破140分的大模型,稳居国内大模型数学能力的第一梯队,在考生中也达到了“尖子生”标准。其中,DeepSeek以143分的成绩位列榜首,讯飞星火以141分紧随其后,位居第二,GPT o3则以138分获得第三名。
本次排名第一的DeepSeek R1模型,是在5月28日升级了最新版本,也是本次评测的模型里最“新”的一位考生,升级后的版本在思考推理、数学能力、响应速度等方面有了大幅提升,但其在实际应用中也暴露出了一些明显短板。首先在实测中,我们发现DeepSeek 在OCR识别效果不理想,出现不少题目识别错误,为确保准确性,我们只能用其他AI将试卷图片转化为文本问题,再给到DeepSeek作答;其次,DeepSeek 模型版本较大,导致推理速度慢、资源消耗高,在实际的教学场景中可能面临响应效率问题。
此外,在这次考试中仅以2分之差紧随其后的讯飞星火,是在4月20日升级,版本较早,但在模型量级更小(70b)的情况下,其依然取得了141分的高分,并显著超越了豆包等其他参与测评的国内大模型。尤其值得一提的是,讯飞星火X1是基于全国产算力平台训练出来的,可见他们背后的自主技术研发实力值得肯定,讯飞在教育领域长达20多年的资源积累,也体现在了讯飞星火在数学能力上的高效准确。
作为国产大模型的代表,豆包、通义千问等大模型分数紧跟GPT o3,基本上和国际顶尖的模型水平打了个平手。
此次国内外大模型参考“2025高考数学”,也是深度推理模型的一场大考,和去年相比,AI的数学能力有了非常明显的提升。2025年将是AI应用落地的爆发期,如何让AI更好的成为我们的帮手,拓展AI在教育领域深度应用的更多可能性,将推理模型的优势与教学实际深度结合等等,或许就是我们用AI来作答高考试卷背后的用意和价值所在。
责任编辑:王珂