炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
大自然用了亿万年优化的神经算法,或许正是突破当前人工智能瓶颈的钥匙。[1]”近日,美国哈佛大学团队和合作者探索了生物强化学习中多个时间尺度的存在,借此证明在多个时间尺度上学习的强化学习智能体具有独特的计算优势,并发现在执行两种行为任务的小鼠实验中,当多巴胺能神经元(Dopaminergic Neurons)编码奖赏预测误差时,表现出了多样化地折扣时间常数的特性。
这一成果为理解多巴胺能神经元的功能异质性提供了新范式,为“人类和动物使用非指数折扣”这一经验性观察提供了机制基础,并为设计更高效的强化学习算法开辟了新途径。
 图 | 相关论文(来源:Nature)
图 | 相关论文(来源:Nature)日前,相关论文发表于Nature[2],加拿大麦吉尔大学助理教授、原美国哈佛大学博士后研究员保罗·马赛(Paul Masset)是第一作者兼共同通讯作者。
 (来源:https://mila.quebec/en/directory/paul-masset)
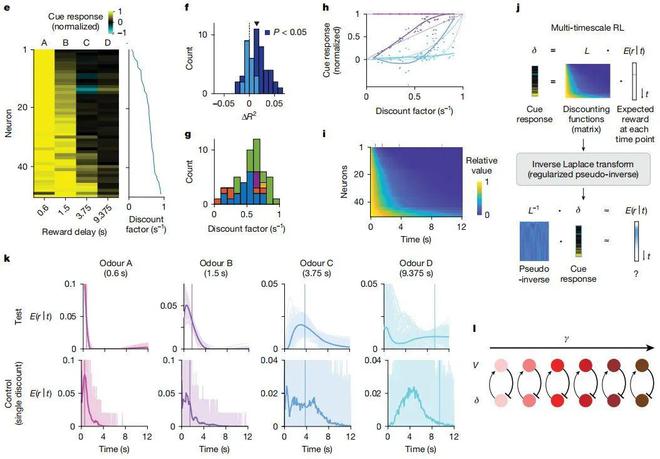
(来源:https://mila.quebec/en/directory/paul-masset)研究中,研究团队使用专有模型解释了时间折扣(temporal discounting)的异质性,这种异质性既体现在由线索引发的瞬时反应中,也体现在被称为“多巴胺斜坡”的较慢时间尺度波动里。其中的关键在于,单个神经元在不同任务中测量得到的折扣因子具有显著相关性,这表明这些折扣因子拥有同一种细胞特异性属性。
需要说明的是,时间折扣(Temporal Discounting)是指个体对奖励或惩罚的主观价值评估会随着时间延迟而下降的心理现象。这一概念在行为经济学、神经科学和强化学习领域具有重要意义。折扣因子(Discount Factor)则是强化学习中的核心参数,用于衡量智能体对于未来奖励的重视程度。

大脑中的强化学习也表现出多时间尺度特性吗?
不少人工智能领域的最新进展都依赖于时序差分(TD,temporal difference)强化学习。在这一学习方法中,时序差分的学习规则被用于学习预测信息。
在该领域之中,人们基于对于未来的预期值,来不断地更新当前的估计值,这让时序差分方法在解决“未来奖赏预测”和“行动规划优化”这两类任务上展现出了卓越性能。
对于传统时序差分学习来说,它采用固定折扣因子的标准化设定,即仅仅包含单一学习时间尺度。这一设定在算法收敛后会导致指数折扣的产生,即未来奖励的价值会随着时间单位呈现出固定比例的衰减。
尽管这种固定折扣因子的标准化设定,对于保持学习规则的简洁性和自洽性至关重要,但是众所周知的是人类和动物这些生物体在进行跨期决策时,并不会表现出指数型折扣行为。
相反,生物体普遍表现出双曲线折扣行为:即奖赏价值会随延迟时间出现“先锐减、后缓降”的特征。
人类与动物这些生物体能够动态地调节自身的折扣函数,以便适应环境的时间统计特性。而当这种调节功能失调的时候,可能是出现心理异常或罹患某种疾病的标志。
研究团队表示,将时序差分学习规则加以进一步扩展之后,能够让人造神经系统与生物神经系统学习更加复杂的预测表征。越来越多的证据表明,生物系统中存在丰富的时间表征,尤其是在基底神经节中。需要说明的是,基底神经节是脊椎动物大脑中一组起源不同的皮质下核。而探明这些时间表征到底是如何学习的,仍然是神经科学领域和心理学领域的一个关键问题。
在大多数时间学习理论中,一个重要组成部分便是多重时间尺度的存在,这使得系统能够捕捉不同持续时间范围内的时间依赖性:较短的时间尺度,通常能够处理快速变化的关系以及即时依赖性关系;较长的时间尺度,通常能够捕捉缓慢变化的特征以及处理长期依赖性关系。
此外,人工智能领域的研究表明,通过纳入多个时间尺度的学习,深度强化学习算法的性能可以得到提升。那么,大脑中的强化学习是否也表现出这种多时间尺度特性?
为此,研究团队研究了多时间尺度强化学习的计算含义。随后,他们发现多巴胺能神经元会在不同的时间尺度上编码预测,从而能为大脑中的多时间尺度强化学习提供潜在的神经基础。
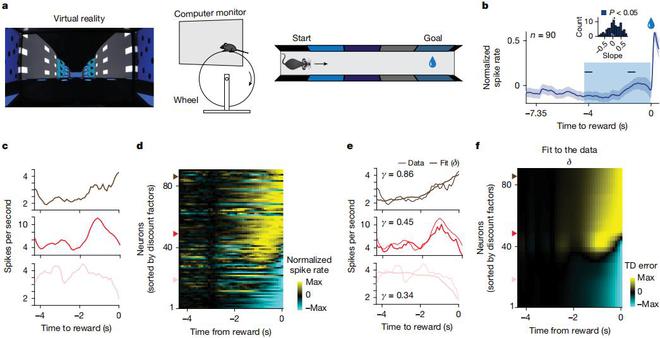 (来源:Nature)
(来源:Nature)
解释多巴胺能神经元活动背后的多个原理
研究团队发现,对于在各类复杂问题中的表现来说,那些采用多时间尺度学习的强化学习智能体,远远优于采用单一时间尺度的智能体。
为了说明多时间尺度表征的计算优势,他们展示了几个示例任务:包括一个简单的线性迷宫、一个分支迷宫、一个导航场景和一个深度 Q 网络(DQN,deepQ-network)场景。
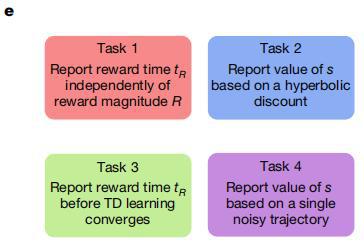 (来源:Nature)
(来源:Nature)在线性迷宫任务中,智能体需要在一条线性轨道中导航,并会在特定时间点(tR)遇到一定大小的奖励(R)。
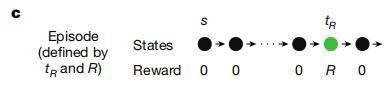 (来源:Nature)
(来源:Nature)R 和 tR 的数值会在不同的回合之间变化,但在同一回合内保持不变。每个回合由在初始状态(s)呈现的提示信号开始。
在每个回合之中,智能体通过简化强化学习算法,利用单个折扣因子或多个折扣因子来计算线索所预测的未来奖赏。
同时,智能体基于已经习得的线索关联价值,通过解码网络针对价值信息进行任务特异性转换,最终生成与任务需求相匹配的行为输出。
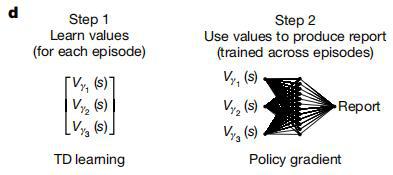 (来源:Nature)
(来源:Nature)由于某些任务涉及到多时间尺度值上的复杂非线性操作,于是研究团队使用策略梯度为每个任务训练了一个通用的非线性解码器。
鉴于本次研究旨在评估多时间尺度价值表征相比单时间尺度表征的核心优势,以及旨在探究这些优势能在多大程度上被一个与代码无关的简易解码器所利用。因此,在研究团队的模型中,多时间尺度价值信号并不直接驱动行为输出,而是作为一种增强型状态表征,以便能为后续任务特异性行为的解码提供信息基础。
通过此,他们分析了多时间尺度强化学习智能体的独特计算优势,并表明这一视角能够解释多巴胺能神经元活动背后的多个原理。
 (来源:Nature)
(来源:Nature)
为新一代算法设计带来革命性启示
研究团队表示,“将多巴胺能神经元理解为通过时序差分强化学习算法计算奖励预测误差”的观点,彻底改变了人们对于这类神经元的功能的认知。
但是,也有研究通过拓展记录位点的解剖学范围,揭示了多巴胺神经元响应存在显著的异质性,不过这些发现难以在经典的时序差分强化学习框架中得到合理解释。
同时,许多看似异常的发现可以在强化学习框架的扩展中得到调和和整合,从而进一步加强时序差分理论在捕捉大脑学习机制复杂性方面的强大能力和通用性。
在这项工作中,研究团队还揭示了多巴胺能神经元异质性的另一个来源:即它们能在多个时间尺度上编码预测误差。
综合来看,这些结果表明此次所观察到的多巴胺反应中的一部分异质性,反映了强化学习框架中关键参数的变化。
相比传统强化学习框架中基于标量预测误差的方法,多巴胺系统能够学习和表征更丰富的信息,这是因为多巴胺系统使用了“参数化向量预测误差”。在“参数化向量预测误差”中,包含了对于奖励函数未来时间演化的离散拉普拉斯变换。
需要说明的是,离散拉普拉斯变换(DLT,Discrete Laplace Transform)是经典拉普拉斯变换在离散时间或离散空间上的推广,主要用于信号处理、系统控制和机器学习等领域。
另据悉,调整折扣因子已被用于在多种算法中提升性能,相关方法包括:通过元学习获取最优折扣因子、学习依赖状态的折扣因子,以及结合并行指数折扣智能体。
但是,神经元通过任务或情境来适配全局折扣函数的募集机制是什么?解剖位置与折扣行为之间的关联是什么?以及 5-羟色胺等其他神经递质对这种适配的贡献是什么?这些都是尚未解决的问题。
同样的,向量化误差信号对于下游时间表征的调控机制仍有待进一步研究。而理解这种神经资源“调动”机制的背后原理,有助于人们在机制层面理解时间尺度多样性在时间决策中的校准作用与失调作用。
目前,研究团队所面临的一个难题是,强化学习理论使用指数折扣,而人类和动物这些动物体经常表现出双曲线折扣。
此前曾有研究探索了多巴胺能神经元的折扣机制,并认为单个多巴胺能神经元表现出双曲线折扣。然而,此前这一研究采用非提示性奖励反应作为零延迟奖励的测量指标,这种方法可能导致结果更加偏向于双曲线折扣模型。
相比之下,本次研究团队的数据与单个神经元水平的指数折扣保持一致,这表明每个多巴胺能神经元所定义的强化学习机制,和强化学习算法的规则是互相符合的。
当这些不同的指数折扣在生物体层面结合时,可能会出现类似双曲线的折扣。也就是说,多个时间尺度对全局计算的相对贡献决定了生物体水平的折扣函数,并且该函数会根据环境风险率的不确定性进行校准。
因此,适当地引入折扣因子的异质性,对于适应环境的时间不确定性非常重要。这一观点也与分布式强化学习假说存在相似之处,该假说认为乐观与悲观的校准失衡会导致习得价值出现偏差。
由于遗传、发育或转录因素导致的这种分布偏差,可能会使生物体在学习过程中要么倾向于追求短期目标、要么倾向于追求长期目标。同样的,这种观点也可用于指导算法设计,使其能够调动并利用这些自适应的时间预测。
总的来说,本次成果创立了一个全新的研究范式,能被用于解析多巴胺能神经元中预测误差计算的功能机制,这不仅为生物体疾病状态下的跨期决策障碍提供了新的机理解释,更为新一代算法的设计带来了重要启示。
参考资料:
1.https://www.ebiotrade.com/newsf/2025-6/20250605082948946.htm
2.Masset, P., Tano, P., Kim, H.R.et al. Multi-timescale reinforcement learning in the brain.Nature(2025). https://doi.org/10.1038/s41586-025-08929-9
排版:溪树