炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
想象一下,当你的宠物狗看到你举起网球准备投掷时,它会本能地预判球的落点并提前跑向那里,而不是傻傻地盯着你手中的球。
这种对物理世界的直觉理解,正是 AI 领域长期以来始终难以攻克的难题。
如今,Meta 推出了新的开源世界模型 V-JEPA 2 和三个新基准测试,希望借助它们的力量来改变这一点。模型和测试已开源在 GitHub 和 HuggingFace 上。
 (来源:Meta)
(来源:Meta)所谓世界模型,就是专门来帮助 AI 智能体理解周围世界,预测周遭状况如何发展,并最终通过规划自身行动来完成目标的模型。
这种能力在人类身上体现为直觉与预判:预测世界将如何回应我们的行为(或他人的行为),尤其是在规划行动以及判断如何应对新情况时。
世界模型已然成为 AI 领域聚焦的目标。李飞飞的 World Labs 、谷歌的 DeepMind 都在开发类似的世界模型。
英伟达也开发了世界模型 Comos,而 Meta 表示,V-JEPA 2 的运行速度是英伟达 Cosmos 模型的 30 倍。
Meta 首席 AI 科学家杨立昆(Yann LeCun)表示:“我们相信世界模型将开启机器人技术的新时代,使现实世界的 AI 代理能够帮助处理家务和物理任务,而无需天文数字般庞大的机器人训练数据。”
V-JEPA 2 是去年发布的 V-JEPA 模型的升级版。它主要基于视频进行训练,拥有 12 亿参数,采用自监督学习方法。它的英文全名是联合嵌入预测架构(joint-embedding predictive architecture,缩写即为 JEPA)。
V-JEPA 2 包含两个主要组件:
一个是编码器(encoder),它接收原始视频并输出嵌入(embeddings),以捕获有关观察世界状态的有用语义信息。
另一个是预测器(predictor),它接收视频嵌入和关于预测内容的额外上下文,并输出预测的嵌入。
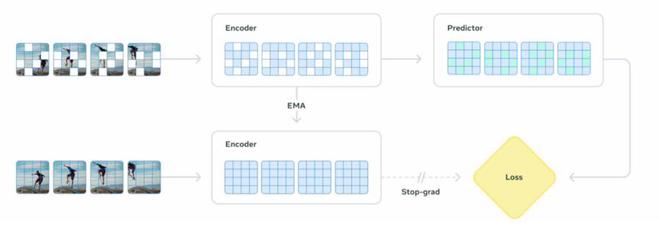
V-JEPA 2 的训练过程则分为两个阶段:
在第一个预训练阶段,研究团队使用了超过 100 万小时的视频和 100 万张图像。这些丰富的视觉数据帮助模型学习了世界运行的大量知识,包括人们如何与物体互动、物体如何在世界中运动,以及物体如何与其他物体互动。
Meta 发现,仅在预训练阶段后,模型就已经展现出了与理解和预测相关的关键能力。
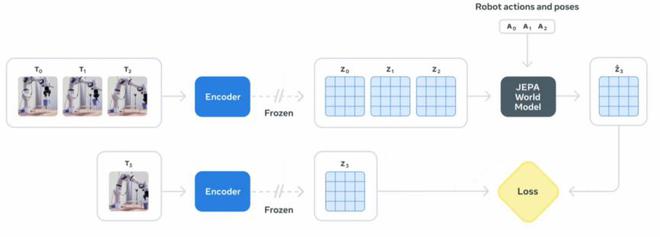
在训练的第二阶段,Meta 专注于利用机器人数据来提升模型的规划能力。他们向预测器提供动作信息,从而将这些数据整合到 JEPA 训练流程中。在使用额外数据训练后,预测器学会了在预测时考虑具体动作,然后可用于控制。
令人惊讶的是,这个阶段并不需要大量的机器人数据。Meta 的技术报告显示,仅使用 62 小时的机器人数据进行训练,就足以产生一个可用于规划和控制的模型。
在性能表现方面,V-JEPA 2 展现出了令人瞩目的能力。在运动理解方面,该模型在 Something-Something v2 数据集上实现了 77.3% 的 top-1 准确率。
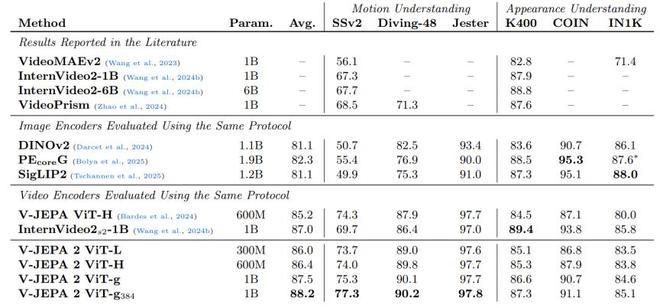 (来源:Meta)
(来源:Meta)在人类动作预期任务中,它在 Epic-Kitchens-100 数据集上达到了 39.7% 的 recall-at-5 分数,超越了现有所有任务特定模型。
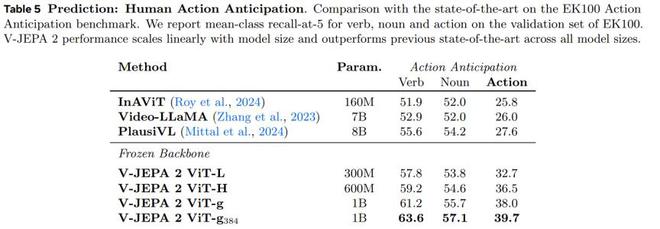 (来源:Meta)
(来源:Meta)当 V-JEPA 2 与大语言模型对齐后,在多个视频问答任务上展现了 80 亿参数规模下的最先进性能。例如,在 PerceptionTest 上达到 84.0 分,在 TempCompass 上达到 76.9 分。
 (来源:Meta)
(来源:Meta)为了更好地评估模型从视频理解和推理物理世界的能力,Meta 还发布了三个新的基准测试:IntPhys 2、MVPBench 和 CausalVQA。
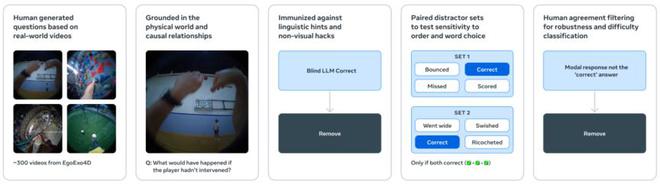
IntPhys 2 用于衡量模型区分场景是否符合物理学的能力,它是在 IntPhys 基准的基础上扩展的。
 (来源:Meta)
(来源:Meta)MVPBench 是通过选择题来衡量视频语言模型对物理(世界)的理解能力,防止模型依赖肤浅的线索“走错误的捷径”。
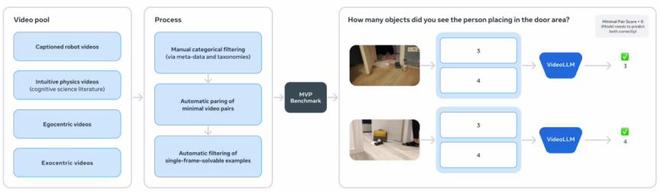 (来源:Meta)
(来源:Meta)CausalVQA 则是衡量模型回答与物理因果关系有关问题的能力,包括反事实问题(如果……会发生什么)、预期问题(接下来可能会发生什么)以及规划问题(为了实现目标,下一步应该采取什么行动)。
 (来源:Meta)
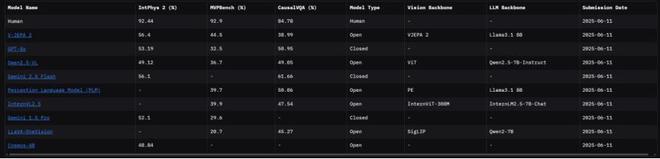
(来源:Meta)三个测试对人类来说小菜一碟,在 84%-93% 之间,但 V-JEPA 2 等模型与人类表现之间仍存在显著差距。
整体来看,V-JEPA 2 在 IntPhys 2 和 MVPBench 表现最好,Gemini 2.5 Flash 则在 CausalVQA 推理预测任务中表现最好。
值得注意的是,在三个测试中,阿里通义千问视觉语言模型 Qwen2.5-VL 的表现也比较亮眼。
 (来源:Meta)
(来源:Meta)Meta 还展示了在全新环境中使用 V-JEPA 2 进行零样本机器人规划。他们在不同实验室的 Franka 机械臂上零样本部署 V-JEPA 2-AC(动作条件版本),实现了使用图像目标进行规划的物体拾取和放置。
这是在没有从环境中的机器人收集任何数据,也没有任何任务特定训练或奖励的情况下实现的,展示了从网络数据和少量机器人交互数据中,自监督学习如何产生一个能够在物理世界中规划的世界模型。
最后,需要看到的是,V-JEPA 2 模型也存在局限性,比如预测动作时没有使用摄像头参数,依赖手动找到效果最好的摄像头角度;误差累积和搜索空间爆炸导致无法完成长时规划任务。
接下来,Meta 团队计划探索多模态 JEPA 模型,通过多种感官进行预测,包括视觉、听觉和触觉等等。
参考资料:
https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks/
https://github.com/facebookresearch/vjepa2
https://huggingface.co/collections/facebook/v-jepa-2-6841bad8413014e185b497a6
https://ai.meta.com/research/publications/v-jepa-2-self-supervised-video-models-enable-understanding-prediction-and-planning/
排版:刘雅坤