炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!

在 AI 领域向来低调的社交平台小红书,近期开源了其首个自研大模型。
6月9日消息,小红书hi lab(Humane Intelligence Lab,人文智能实验室)团队近期在Github、Hugging Face等平台发布首款开源文本大模型dots.llm1。
据悉,小红书hi lab团队开源了所有模型和必要的训练信息,包括微调Instruct(dots.llm1.inst)模型、长文base(dots.llm1.base)模型、退火阶段前后的多个base模型、超参数以及每1万亿个token的中间训练checkpoint等内容。
6月9日,笔者注意到,dots.llm1两个型号的模型于9日晚进行了update,修复了停止符号的配置,属于模型常规的修复。
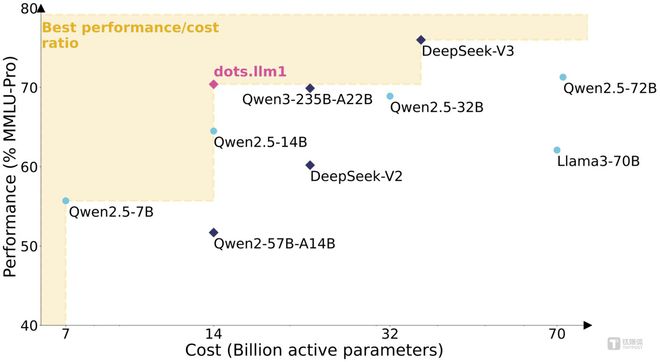
目前来看,dots.llm1大部分性能与阿里Qwen 2.5模型,部分性能与阿里Qwen 3模型相当。
具体来说,dots.llm1混合专家模型(MoE)模型拥有1420亿参数,使用11.2万亿token的非合成高质量训练数据,在推理过程中仅激活140亿参数,能保持高性能的同时大幅度降低训练和推理成本。
此次小红书团队开源了base模型和instruct模型,作为大语言模型的两个阶段,base模型是“基座模型”,通常只完成了预训练(pre-train);instruct模型是在 Base 模型基础上,通过指令微调的模型,方便直接部署、开箱即用。
在预训练阶段,dots.llm1 一共使用了11.2万亿高质量 token数据,并经过人工校验和实验验证该数据质量显著优于开源 TxT360 数据。然后,经过两阶段SFT(监督微调,Supervised Fine-Tuning)训练,得到dots.llm1 base 模型和 instruct 模型。
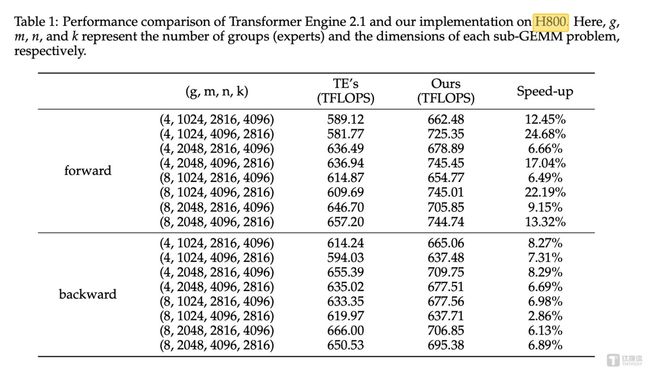
MoE 高效训练实践层面,团队引入Interleaved 1F1B with AlltoAll overlap,实现通信与计算最大重叠,并且优化 Grouped GEMM。经过实测验证,基于英伟达H800上前向和后向计算的性能比较,与NVIDIA Transformer Engine中的 Grouped GEMM API 相比,hi lab 实现的算子在前向计算中平均提升了14.00%,在反向计算中平均提升了6.68%,充分证明了这套解决方案的有效性和实用价值。
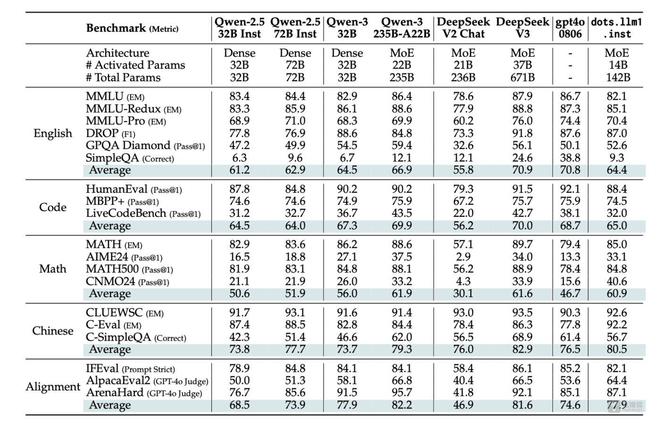
结果方面,在激活140亿参数情况下,dots.llm1.inst在中英文通用场景、数学、代码、对齐任务上的表现亮眼,对比阿里通义Qwen2.5-32B/72B-Instruct具备竞争力;同时在中英文、数学、对齐任务上,表现与阿里Qwen3-32B相当或更优。
另外,与DeepSeek相比,整体来说,dots.llm1性能高于DeepSeek开源的V2模型,但略低于V3模型的性能表现。
中文性能上,dots.llm1.inst在中文任务中展现出显著优势,它在CLUEWSC上取得了92.6分,在中文语义理解方面达到业界领先水平。在C-Eval上,它取得了92.2分,超越了包括DeepSeek-V3在内的所有模型。
据笔者了解,成立于2013年的小红书,是移动互联网创业浪潮中少数未上市企业之一。2016年初起,小红书将人工运营内容改成了机器分发的形式。通过大数据和AI,将社区中的内容精准的匹配给对它感兴趣的用户。
随着2022年底ChatGPT热潮爆发,小红书2023年起持续投入研发大模型。
近几个月来,小红书加快了 AI 落地步伐,推出了一款AI搜索应用“点点”,并在小红书内置“问一问”功能等,帮助用户在小红书内容平台上查找信息。
值得一提的是,6月5日,金沙江创投旗下的一份股份交易文件显示,截至3月底的基金净资产价值换算后,小红书的估值从200亿大幅跃升至260亿美元(约合人民币1869.26亿元)。这一估值远超过B站、知乎等上市公司的市值,但低于快手,后者最新市值约为323亿美元。不仅如此,一级市场称。小红书老股的报价已经到了350亿美元,超过2500亿元。
目前,小红书的股东包括真格基金、金沙江创投、纪源资本、淡马锡、DST Global、阿里、腾讯等20余家知名机构。公开信息称,2024年小红书净利润超过10亿美元。
随着阿里、腾讯、字节等大厂都在发力 AI 大模型领域,小红书似乎不甘心做内容社区和直播电商,瞄向 AI 技术发力大语言模型落地。
作为未来工作的一部分,小红书hi lab的目标是训练一个更强大的模型。为了在训练和推理效率之间取得最佳平衡,其计划集成更高效的架构设计,例如分组查询注意力 (GQA)、多头潜在注意力(MLA)和线性注意力。此外,hi lab还计划探索使用更稀疏的混合专家(MoE)层来提升计算效率。此外,由于数据是预训练的基础,hi lab将加深对最佳训练数据的理解,并探索实现更接近人类学习效率的方法,从而最大限度地从每个训练示例中获取知识。
对于小红书hi lab下一步是否会发力多模态,该团队公开的技术文档显示,小红书hi lab团队将为社区贡献更多更优的全模态大模型。(本文首发于钛媒体App,作者|林志佳,编辑|盖虹达)