炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
CVPR 2025,自动驾驶传来重大进展:
Scaling Law首次在这条赛道被验证!

来自中国的小鹏汽车,完整拿出了技术方案和AI司机“智能涌现”的成果。
自动驾驶的“ChatGPT时刻”,真的要来了吗?
CVPR 2025,小鹏汽车拿出了什么成果
今年的CVPR线下会议在美国田纳西州纳什维尔举办,日期是6.11-6.15。观众老爷们看这篇推送的时候,CVPR才刚刚结束几个小时——新鲜出炉
CVPR的自动驾驶分论坛(Workshop on Autonomous Driving),历年都是业内极具影响力的技术风向标和盛会。比如2022年的WAD,Wayve首次披露了自己低传感器端到端路线方案,马上成为自动驾驶赛道炙手可热的明星公司;再比如,特斯拉最早在CVPR WAD上详细分享了占用网络技术,随后成为业内悉数跟进的量产方案……
今年的WAD,中国的小鹏汽车是唯一一家受邀发表主题演讲的车企
小鹏在演讲前一天,刚刚开启了最新SUVG7的预售,创造了量产L3级AI算力第一车的纪录,单车算力超过2200TOPS,何小鹏将G7定义为“真正的AI汽车”。

随之而来也有争议:预售价23.58万的G7不给激光雷达,智能辅助驾驶靠谱吗?
其实答案就在小鹏CVPR的演讲中。
先看实验结果。几个月前,小鹏汽车在后装算力的车端部署了新一代自动驾驶基座模型,实现了无任何规则代码托底情况下,基座模型直接控车并安全完成一系列驾驶任务。
比如丝滑地加减速、变道绕行、转弯掉头、等待红绿灯等等:

整个自动驾驶系统全流程模型化,其实就是马斯克宣讲多年的AI司机,其最重要的特征是展现出对环境、路况的全局理解和思考。
比如这个场景下,直行道上,先是前方大车切出后,然后又看到了里边临停车,但系统全程没有任何“紧急避险”的举措,而是从容有序的减速绕行,丝滑通过场景:

再比如这个场景:系统首先提前变道,避让施工区,但就在转向过程中,又突遇从小路汇入主路的大货车:

再比如雨天的窄路弯道,道路一侧已经被各种违停车占满,行进途中又突遇临时上下客的网约车,系统没有丝毫犹豫,直接发起绕行:

并且在绕行过程中,还避让了一连串在机动车道上逆行的低速电驴。
所有场景主打的是决策果断、路线合理,体验丝滑。
小鹏解释,同样的场景传统技术方案也有概率能通过,但熟练丝滑大打折扣,乘坐体感也不行。
目前市面上几乎所有量产智能辅助驾驶,一旦周围目标的距离、速度相对本车达到一定区间(比如突然汇入的大车、迎面而来的电驴,极度狭窄的道路空间等),必然首先触发紧急刹车,车内乘员一顿前俯后仰之后,可能仍然需要接管……
至于一些极端场景,是这些传统方案很容易“宕机摆烂”的。比如这个位于福州的路口,马路对面的主干道上有两棵大树伫立,车道竟然就在这两棵大树之间……不是本地司机,可能根本搞不明白该怎么走。
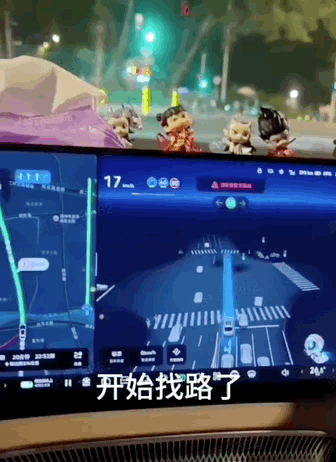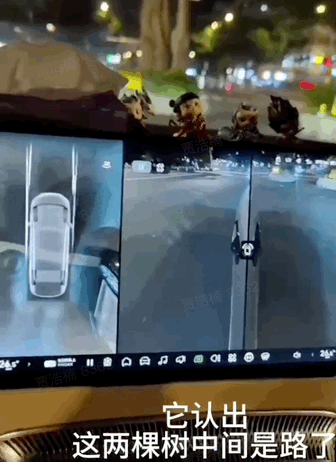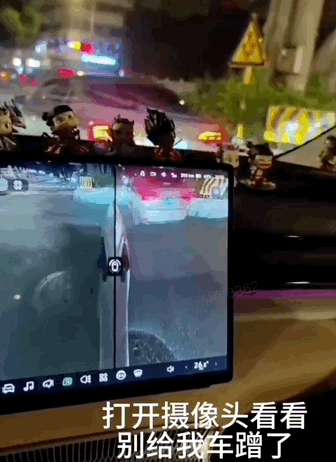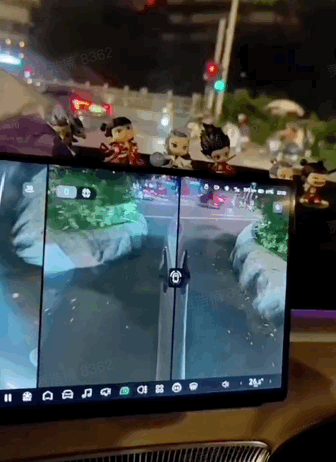
但小鹏的系统竟能准确辨识出车道,顺利通过。这对目前的量产系统来说属于“惊喜”,对于今后要上车的下一代模型来说就是“基操”。
小鹏世界基座模型负责人刘先明说,这就属于典型的CoT场景,车端模型在整个过程中不断实时推理:
链式思考能力(CoT,Chain of Thought),背后的基础是小鹏自研的“自动驾驶基座模型”——物理世界模型。

既非行业常见的模拟训练世界模型,也不是单一的VLA、VLM,更超出了端到端“一段或两段”的争论……
押注新技术路线背景下,小鹏最新的量产方案也和其他所有玩家产生了明显不同。
小鹏的自动驾驶基座模型,到底是什么?
上面道路实测的小鹏自动驾驶基座模型,其实就是4月小鹏公布的“下一代自动驾驶基座模型”的早期车端实测版本。
对于真正的自动驾驶模型,小鹏的理解和实践与绝大多数业内玩家不同
现阶段主流的“车端模型”,其实主体就是端到端算法,从传感器取数据,然后输出路线规划,一般还会有一些强制规则安全兜底。

但小鹏认为,这种传统模式尽管一定程度上AI化了,但端到端本质仍然是“小脑”,对输入的道路信息做出的反应是被动式、条件反射式的关键这种“条件反射”还是黑盒,过程难以把握
其实也是L4玩家质疑L2路线的核心依据:不会思考的模型,数据量再大也只能模仿人类行为,无法真正超越人类达到“自动驾驶”的层级。
小鹏认为问题出在了现行的技术方案上:只局限在车端算力的一亩三分地,模型大小是受限的,能真正消化的数据也是受限的。
只有超越车端芯片算力的限制,应用更大的模型、更海量的数据,才能真正实现车端的智能
小鹏“世界基座模型”本身是以大语言模型为骨干网络,使用海量优质驾驶数据训练的VLA大模型,参数量高达720亿,部署在云端。
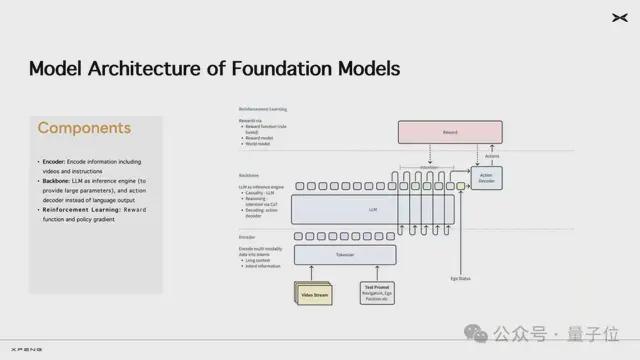
VLA,全称Vision-Language-Action,一般同时包含视觉编码器、语言编码器、跨模态融合模块、动作生成模块,能同时理解视觉图像、自然语言,并生成动作控制指令的AI模型架构。
2023年谷歌Robotics团队的RT-1打响VLA第一枪,用人类操作示范构建多模态训练集,以图像、语言指令和连续控制信号作为输入,训练机器人理解语言并直接输出动作。后续RT-2又把CLIP等视觉语言基础模型引入控制流程中,基本奠定了“图像+语言+动作”统一建模的VLA基线,成为具身智能和自动驾驶的新希望。
VLA特别之处在于,不再是分模块“各自为政”,而是通过建立视觉信号、语言指令与物理动作之间的关联映射,实现环境理解到行为输出的闭环决策。
简单说,过去一个任务需要分别训练图像识别模型、语义理解模型、控制策略模型;而现在,VLA一个模型就能从图片和语言中“看懂任务”,并“动手完成”。
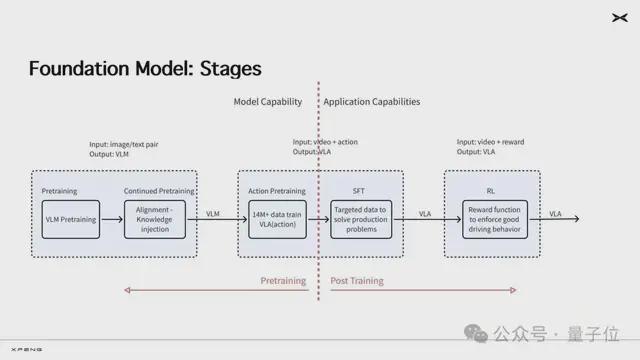
基座模型完成预训练、监督精调(SFT)之后,就进入强化训练阶段。强化学习是小鹏基模训练最大的特点,也是模型能力的隐形护城河。
小鹏自研开发的强化学习奖励模型主要从三个方向上去激发基模潜能:安全、效率、合规。实际上也是人类驾驶行为中的几个核心原则。
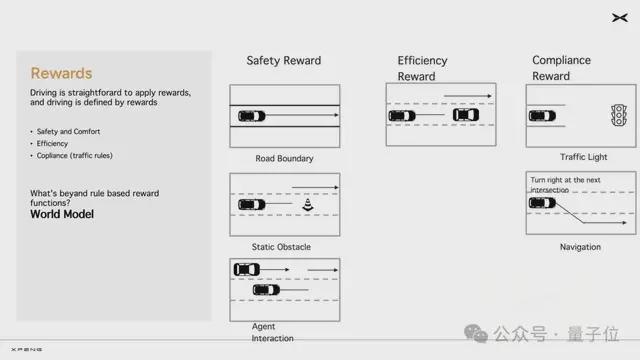
比如遇到不认识的障碍物要绕行是为了安全、路上遇到特别慢的车适时变道超车是为了通行效率、按照红绿灯车道线道路标牌的指示开车是为了合规…….
刘先明还透露,小鹏已在开发世界模型(World Model),今后会用于基座模型的强化训练。
世界模型被认为是自动驾驶“专用Sora”,用来生成各种交通场景的corner case,源源不断产生高价值训练数据。
但刘先明认为自动驾驶的世界模型远远不是今天的“仿真建模”,它应该是一种实时建模和反馈系统,能够基于动作信号模拟真实环境状态,渲染场景,更重要的是,能生成场景内其他智能体(也即交通参与者)的响应,也就是说,所有智能体都不是NPC,都需要通过跟其他智能体的交互产生博弈行为。这样的世界模型,才算得上一个闭环的反馈网络。
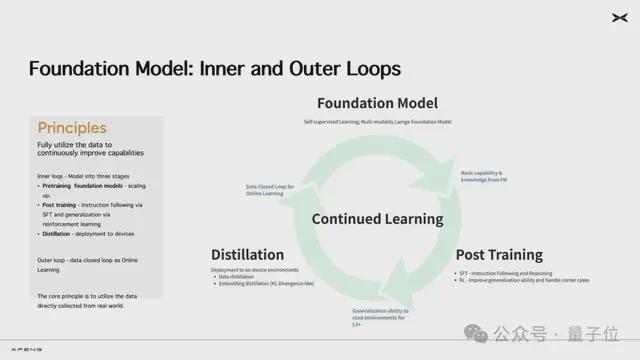
最后,云端模型将通过知识蒸馏方式生产小尺寸模型,部署到车端,成为“AI汽车”全新的大脑。模型在车端部署之后,持续获取新的驾驶数据和用户反馈,又能继续用于云端基模的训练,让基模不断迭代。这个过程被小鹏汽车称为持续在线学习(Online Learning),由VLA和OL构成的这套技术架构,将让基模常训常新。
你可能会问,为什么不用相同的数据,去直接训练一个可在车端直接部署的小模型呢?
小鹏提到了在实践中,同样的数据在10亿、30亿、70亿、720亿参数上看到了非常明显的Scaling Law效果:随着参数规模越大,模型的能力越强
目前基座模型累计吃下了2000多万条视频片段(每条时长30秒)。在不断扩大训练数据量的过程中,研发团队同样清晰地看到了规模法则(Scaling Law)的显现:
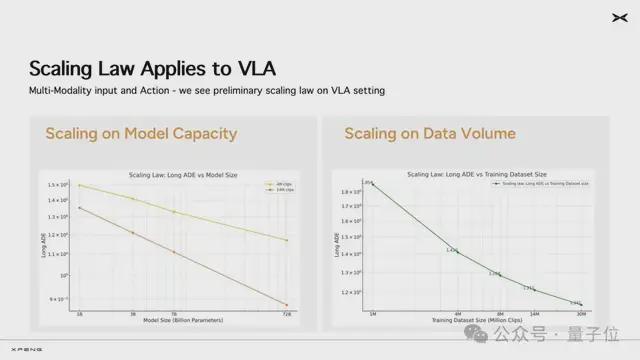
这是大模型浪潮以来,行业内首次明确验证规模法则(Scaling Law)在自动驾驶VLA模型上持续生效
而要想把大模型的能力尽可能延续到车端相对较小的模型上,知识蒸馏是目前最好的方法。这比直接训练一个车端小模型更难,但上限也更高
因为模型参数的利用率是有限的,云端有更多的数据,能学到更多的东西,智能涌现效应更强。再蒸馏到车端的小模型上,可以让小模型有更强的表现。
另外,自动驾驶本身具有“多模态”或者说“多解输出”的特点,容易遇到“模态不统一”的困境。意思是同一个驾驶场景可能会有多种路径选择,而且它们都是对的。当模型使用的数据量增大,就会出现越来越多的“相似场景,多种解法”的训练数据,对于参数量不足(智商不足)的小模型来说,可行解法越来越多,可能造成模型的confusion,导致模态坍塌。因此,直接训练车端小模型,实际上并不能通过数据的增加实现scaling law。
但如果本身云端训练了更大的模型,作为老师,去教车端的模型学习,就会有“模态统一”的优势。

另外刚刚提到的强化学习方法,同样也是模型越大效果越好。更大的云端模型后训练,再向车端小模型去蒸馏,得到的结果,比直接车端的小模型做强化训练要好得多。
这样的时间和认知下,小鹏从2024年开始,开始开拓、押注自动驾驶以及量产车的新技术路线,明显和所有其他玩家不同。
首先是云端,开发具有普遍认知能力的超大规模多模态模型作为基座模型。并且为此开始储备超级计算集群,目前已达10 EFLOPS,集群运行效率常年保持在90%以上,全链路迭代周期可达平均5天一次。
这个水平远超其他车企,和顶尖AI科技公司相当

车端侧,出于自动驾驶安全性、实时性考虑,小鹏坚持把蒸馏后的“大脑+小脑”方案完整部署在本地,避免网络时延安全隐患。
因此,超大算力、大模型针对性优化的计算芯片就成了必须——小鹏历时5年自研的图灵AI芯片的,“1颗顶3颗”,单颗有效算力相当于3颗主流芯片。

新车G7最后呈现的,其实就是小鹏最新AI认知的落地:3颗图灵AI芯片2200TOPS+有效算力,车端VLM+VLA。
小鹏汽车CEO何小鹏称:VLM是车辆理解世界的大脑,过去我们使用语音、触屏、按键来操控汽车。而不久之后,VLM将替代彻底取代这些操控手段,成为人和汽车对话操控的新一代入口。
另外VLM也像车辆行动的总指挥,指导智驾和智舱等整车能力的进化,真正实现“AI定义汽车”。
车端的VLA-OL模型,则给智能辅助驾驶增加“运动型大脑”,还进一步增强了“小脑能力”同时具备持续强化学习能力,未来进化到自主强化学习,让大模型持续进化。
何小鹏坚信,这条路线不仅是小鹏下一阶段增长引擎,更是对现行所有量产L2路线的突破,也是自动驾驶和具身智能大一统的开端。
小鹏进入AI“无人区”
小鹏在CVPR 2025上的演讲,技术上是一个转折点。
L4和L2都在堆算力。比如小马智行、百度Apollo、文远知行等头部Robotaxi玩家,单车算力也都超过了1000TOPS;包括小鹏在内,蔚来、理想、极氪等等新车,也都把算力数值堆到了“千TOPS”这个级别。

但两个阵营的方向有明显分化。L4是为了超多传感器冗余堆算力,L2则是为端侧超大模型堆算力,一个保下限一个拼上限。
L4阵营的大佬,过去常嘲讽质疑智能辅助驾驶,认为两个技术体系有不可跨越的鸿沟,依据就是L2太依赖端到端,而端到端的本质是模仿,但数据来源(即人类司机)的上限永远不可突破,下限永远不可预测。
而小鹏的新技术路线,第一次从技术层面回应了“端到端只能模仿不能超越”的问题:跳出数据局限性的叙事,从AI本质出发,打造一个有完整认知能力和运动规划协调能力的“大脑”。
这套方案中,关于“上限”问题的回答是模型本身的超大参数规模带来的能力跃升,关于“下限”问题的答案,同样是超大规模模型对强化学习的出色反馈。

小鹏的技术路线发展方向,要解决的不仅仅是车的问题。
新G7的量产方案中,小鹏开始用一整个“AI智能体”视角解决问题:
VLM则是车辆理解世界的“大脑”,统一舱驾和用户直接交流。
而具身智能则是在此基础上增加“脊柱、脑干”,即复杂的运动规划控制能力。
小鹏其实已经实现了新技术体系在车、机器人和飞行汽车的通用。

何小鹏自述在自动驾驶和机器人研发过程中自然而然积累的这样的认知,于是开始主动布局有完整认知能力的世界模型;以及从5年前就开始开发储备云端算力储备,图灵AI芯片、自动驾驶基座模型等等。
小鹏在CVPR WAD上的演讲,本质上是小鹏汽车带着工业问题和解法反哺自动驾驶学术界。
“一流的自动驾驶公司,首先是一流的AI公司”,小鹏造车10年得出了这样的结论,现在又知行合一,孤身走进了“AI无人区”。