炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
本文来源:时代周报 作者:申谨睿
AI新云(也称GPU云、智算云)是全球 AI 基础设施当下变革的注脚。
过去一年,生成式AI及大语言模型集成企业应用加速生长,市场对训练 AI 模型的 GPU 专用计算需求激增。为满足该需求,GPU专用云服务平台不断涌现,这些云服务平台被称为 AI 新云( NeoCloud)。
 (九章云极CEO方磊 受访者供图)
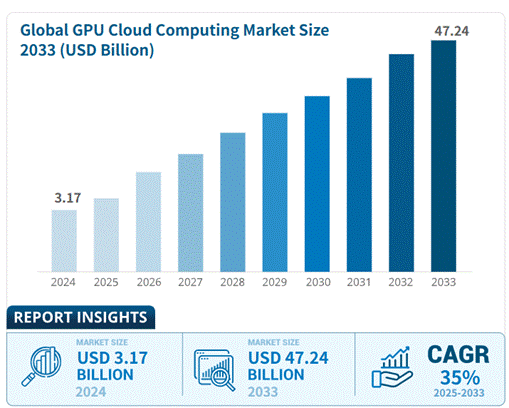
(九章云极CEO方磊 受访者供图)与提供广泛通用服务的传统通算云服务商不同,NeoCloud 专注为 AI 工作负载提供高性能基础架构。据Business Research预测,全球GPU专用云市场规模将由2024年的31.7亿美元快速增长至2033年472.4亿美元,增长近15倍,复合增长率约为35%。
为在这一蓝海中掌握先发优势,海内外企业皆摩拳擦掌。
今年3月,被业内称作“英伟达亲儿子”的AI基础设施企业CoreWeave上市,这家依托英伟达GPU资源冲击新云市场的创企,市值在IPO后的两个月从230亿美元飙升至720亿美元。与CoreWeave颇为类似,另一家海外AI基础设施企业Crusoe也凭借其掌握的GPU资源成功转型云服务商。
在这场AI算力淘金热中,中国同样参与者众多,其中不乏云服务商、利用云服务拓展业务的AI基础设施企业。
今年第二季度,这些冲击AI新云计算的公司先后发布了自己的AI基础设施服务。如CoreWeave推出基于英伟达GB200的全新架构;阿里云基于 PAI-DLC 云原生分布式深度学习训练平台推出了 FlashMoE,九章云极从AI计算底层革新出发,推出了基于Serverless+RL强化学习技术架构的九章智算云Alaya NeW Cloud。
“相比海外企业以资本驱动实现规模化,中国AI新云更关注迭代速度、总体拥有成本等务实客户价值。”近日,九章云极CEO方磊在接受时代周报记者专访时表示,资本市场对以CoreWeave为代表的资源型企业的考察重点并非技术,而是其凭借卖资源打下的市场规模。相比而言,中国企业更关注技术本身的“用处”——业务范围既涵盖售卖资源,也包括应用在各种场景中的AI工具。他认为,这样的模式有助于维系长尾客户,而长尾客户往往是企业稳健发展的关键要素。
九章云极DataCanvas于2013年成立,是国内AI基础设施的头部企业。此前,九章云极提出“一度算力包”概念,希望解决行业中算力结构性错配、服务非标准化、用户需求难以预测等问题。
方磊是清华电子工程系毕业的博士,虽技术出身,但对商业的见解十分“接地气”。他表示,商业的本质是“卖货”,在交易与合作中,要理解货物本身的价值,也要清楚其边界,同时看到客户企业的能动性和创造力。
“涉足AI新云业务的公司把所能提供的价值点押注在算力层而非工具链上,更有利于公司行稳致远。”方磊向时代周报记者解释道,GPU一旦“云化”,其规模和技术门槛会迅速提升。规模将会和电力一样巨大。就像微软从操作系统的软件公司涉足Office,GPU云企业也会克服算力、算法变迁带来的难题,在多元的生态位上找到自己的角色。
算力:CPU云向GPU云的历史性迁移
市场为什么会大力呼唤GPU专用云?
方磊表示, 传统云架构的局限性逐渐凸显。传统CPU 云基于虚拟化技术的资源切片模式,主要针对互联网时代带宽密集型应用设计。但 AI 工作负载以计算密集型处理为核心,需要大规模并行计算能力,这与CPU的串行处理特性形成了根本性矛盾。
简而言之,CPU的技术架构在训练和推理大型AI模型方面不够高效。那么,AI时代需要怎样的硬件设施?
方磊向时代周报记者拆解道,硬件方面,GPU性能更强,资源利用方式更“聪明”。如英伟达最新的 H200 GPU 内存带宽达 4.8TB/s,约为传统 CPU 系统( 50GB/s) 的近百倍,在深度学习训练中,性能可提升 10-100 倍。同时,Multi-Instance GPU(MIG)技术能将单个 GPU 分割为最多7 个独立实例,即不同“GPU分身”可以同时工作,互不干扰,便于下游企业更灵活地分配计算资源,实现 GPU 的精细化管理。
硬件迭代如同给AI研发装上了"涡轮增压",在带来高效计算的同时,也为业内玩家的商业模式带来与传统巨头同台竞技的底气。时代周报记者注意到,在传统 CPU 通算云向 GPU 智算云的架构迁移的过程中,传统云巨头面临了新势力的挑战——AWS、Google Cloud、Azure等企业虽推出 GPU 实例,但在定价和性能优化上未能即时适应新的市场需求。
“一个数据中心,如果同时兼顾CPU和GPU的需求,就会变成‘四不像’。”方磊解释称,一方面,如果数据中心仅运行GPU,要比同时运行GPU和CPU的成本低廉。据市场信息,如亚马逊的GPU租赁价格为12美元/卡时,CoreWeave的价格则为6美元/卡时;另一方面,假如一个计算中心不是单纯为GPU高度优化的,也会影响GPU的性能。”
相较传统云厂商“大象难起舞”,专用GPU云企业的成本与商业模式更显“普适性”。如CoreWeave 的 GPU 实例定价,相比传统云提供商有 50%-80% 的成本优势;九章云极智算云Alaya NeW Cloud的定价策略则抛去了传统裸金属租赁方式,提出“一度算力”按量计费模式,降低算力使用门槛,提升算力使用的灵活性。
从 CPU 云到 GPU 云的迁移,不仅是技术升级,更是计算范式从通用向专用的根本转变,这种转变正重塑着整个云计算产业的竞争格局。
算法:深度学习向强化学习跃迁
算法层面的变革也在影响底层算力的跃迁。当前,AI 算法正从数据驱动的深度学习向经验学习转变,这一新的模型训练方式,对GPU专用云的效率提出了新要求。
“用于训练大模型的高质量数据量接近天花板,难再有指数级增长。这一限制促使研究者转向强化学习,通过模型与环境交互生成训练数据,以经验反馈突破数据稀缺瓶颈,增强模型的推理能力。”方磊告诉时代周报记者,算法范式的变化会产生新的算力缺口。原因在于,强化学习的多模型架构大幅增加了训练资源需求。以 70B 参数模型为例,RLHF 阶段约需 48 个 A100 GPU 同时工作,计算需求比传统深度学习增加 1-2 个数量级。
"这一数据的判断与英伟达计算芯片迭代的实际节奏高度吻合——与‘B系列’芯片相比,其‘R系列’芯片的推理性能实现了十倍乃至百倍的提高。”方磊补充道。
如何提升GPU专用云的效率以应对算法的变革?不妨从云计算的发展史中汲取经验。
近20年,云计算产业的发展出现了三个分水岭。一是以虚拟化为主要技术支撑的云计算正式登上历史舞台,应对高速扩张的移动互联网以及流媒体萌芽所带来的爆炸式计算需求;二是池化技术的变革,通过规模化的调度、编排,形成了超大规模的计算和存储资源池,继而形成亚马逊云、微软云、阿里云三强鼎立的格局;三是阿里云创新性地推出CIPU(云基础设施处理器)架构方式,该架构不仅能在数据中心内发挥效用,也能和系统内的软硬件深度适配,当计算资源、存储资源、网络资源接入CIPU后,就会被云化为虚拟算力进行调度编排,兼顾零损耗与高性能。
前两次浪潮,使得CPU为核心的传统X86架构替代了大型机、小型机,满足了当时企业业务扩展带来的算力弹性需求,但他们的本质都是通过软件的优化,将越来越多的计算节点连接组合对外提供服务。时至第三次变革,软件的迭代已不足以应对当时的市场需求,架构的创新成为云厂商换道超车的新思路。
同样地,于GPU专用云而言,“软硬一体化”的创新架构是应对当前算法变化的抓手。方磊告诉时代周报记者,九章智算云从底层技术架构出发,推动由虚拟技术向Serverless(无服务)+RL(Reinforcement Learning,强化学习)为主导的架构演变,支撑AI部署从“配置机器”转向“提交任务”,从而提高高密度算力需求下的GPU资源的利用率。
Serverless+RL的核心是将传统后端服务拆解为更细粒度的函数或服务单元,由云平台自动管理资源、运维和扩展。就如解决饱腹问题,需求方原本需要建厨房、买食材甚至雇厨师,而现在只需要在外卖平台下单即可。
“在CPU云时代,虚拟化技术通过切片资源让用户使用;GPU云时代,Serverless技术可以让用户更聚焦应用而非花太多代价去关注底层优化。让GPU云的提供者更关注如何做好AI优化、高密集AI计算等,让企业低成本实现他们的目标。”
“与自动驾驶的AI训练系统类似,得益于Serverless 架构,九章云极AI新云平台DataCanvas Alaya NeW Cloud能自动完成环境配置、策略加载与任务监控,在强化学习训练中的端到端性能提升5倍。同时,Alaya-UI智能体采样速率提升5-10倍,GPU利用率提升2倍。”方磊认为,Serverless会成为GPU云的主要技术趋势。
(九章云极智能计算论坛 受访者供图)
中美AI新云分野
在AI云服务的竞逐中,中美两国走出了截然不同的发展路径。
美国AI云市场呈现出典型的资本集聚特征。CoreWeave通过与英伟达的深度合作,凭借数百亿美元的基础设施投入,构建起50-80%的成本优势;同样采用资本密集策略的Lambda Labs,则以每小时2.49美元的H100 GPU租赁价格快速占领学术市场。
不过,上述两家企业的客户集中度较高,如CoreWeave超过60%的收入来自微软单一大客户。这种商业结构虽能保证短期收入快速增长,却也暗藏一定业务风险。
中国企业则倾向于通过技术破局、围绕客户需求提供服务方案寻求增长。“我们优化后的GPU利用率可以超过95%,这个数字比很多客户自己优化的结果还要高,而行业平均GPU利用率通常为70%左右。”
此外,中美AI云企业的市场定位也存在差异。美国的资本驱动模式聚焦大型企业客户,而中国的技术驱动模式则将目光投向长尾市场。在生态建设理念方面,前者追求规模与效率,后者更强调普惠与可持续发展。
方磊认为,数百万企业、数千万个人开发者,都亟需弹性且高性价比的GPU云服务。他坦言,目前中国智能算力的短缺主要呈现结构性错配的特征。“如某厂商在某一地区设立了万卡集群,但当地的智能算力需求方可能需要在外地寻找服务器租用。目前公开市场上,大量AI计算芯片要么掌握在头部互联网厂商手中,要么以服务器(裸金属)的形式出租,市场化的、面向大众的、普惠的智能算力非常稀缺。”
谈及发展目标,方磊表示,九章云极希望成为中国NeoCloud的定义者,"此前我们定义了'一度算力',未来希望探索出具备中国特色的AIDC运营模式”。他称,DeepSeek-R1的问世已表明,低成本投入能博取优质的模型能力。这也意味着,能否为数千万开发者提供普惠算力服务,将成为决定AI云企业竞争力的重要考核维度。