MiniMax 四处突围,终于撞上了自己的“好日子”。
昨天凌晨,MiniMax正式开源它们的第一个推理模型M1,这款模型虽然在各项基准测试中表现“相貌平平”,却拥有业界最长的上下文能力:100万token输入,8万token输出。除了高调开源M1,另一个消息正在各大AI社区传播:MiniMax正在邀请用户测试它们的通用Agent。
在错失推理模型先发优势后,这家曾被认为是AI六小龙中最稳健的公司,想在下一程赢回来。
现在,它们终于等到了一个正在急剧缩短的时间窗口——Agent爆火的2025年。
那么,MiniMax这回推出的M1以及正在内测的Agent到底实力如何?是否还能在明星AI初创公司和大厂的强敌环伺下“正面突围”?
“直面AI”(ID:faceaibang)实际上手体验了下,并深度解读了这次的技术报告,“挖出了些”背后的东西。
01
上下文 + Agent能力是新模型的核心
接下来,我们实地测试下MiniMax M1推理模型和MiniMax Agent。
先来说下M1推理模型,它给我的第一个感受就是推理链很长,这其实与最近国产开源的几个前沿大模型的表现很相似,像是前段时间的Qwen系列以及DeepSeek的最新小版本。它们透露出来的能力都是推理很强,但是推理链非常长,网友们也多次指出:极长的推理链,往往会让模型输出结果走偏。
比如,像下面这个“钢琴键盘可视化小游戏”,我输入了一段提示词:
[角色设定] 你是一名前端开发者,擅长用原生 HTML + CSS + JavaScript 创建交互式页面。
[任务目标] 在网页端实现一个“钢琴键盘可视化小游戏”,支持鼠标点击或键盘按键触发高亮,无需播放音乐。
*[核心功能]
1. 绘制 14 个白键 + 10 个黑键(C4–C5)。
2. 点击/按键时,对应琴键变为高亮色,松开后恢复。
3. 页面顶部实时显示被按下的音名(如 “C4、D#4”)。*
[键盘映射] • A–L 对应白键 • W–O 对应黑键
[技术要求] • 不使用任何框架,只用 原生 HTML/CSS/JS。 • 代码放在单个 index.html 中,可直接双击打开运行。
[样式细节] • 白键默认 #fff,黑键默认 #333。 • 高亮色统一用 #f59e0b(亮橙)。 • 页面居中,宽度 ≤ 800 px,移动端自适应。
MiniMax M1足足思考了791.2s,大部分时间都在思考键盘与字母的搭配问题,似乎在这一过程中,陷入了无尽的思考之中。

而且,我还在它的思维链里直接发现了可视化的“钢琴键盘”:

在经过大量时间的思考后,M1认为题目中的键盘映射存在矛盾,可能无法完全正确实现。不过,它仍然给出了一份完整的代码,我将它部署了一下,你可以看看效果,还是比较完整的:

除此之外,官方也给了几个案例。
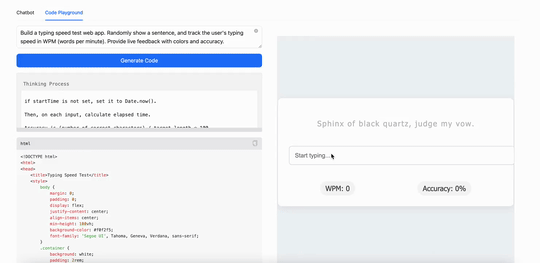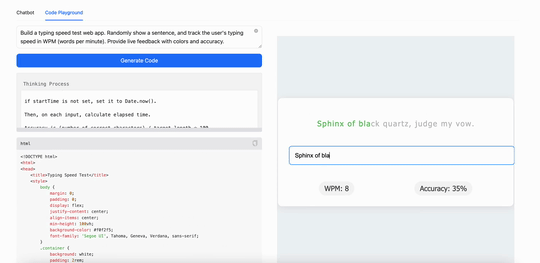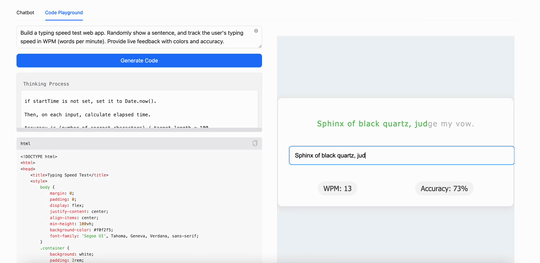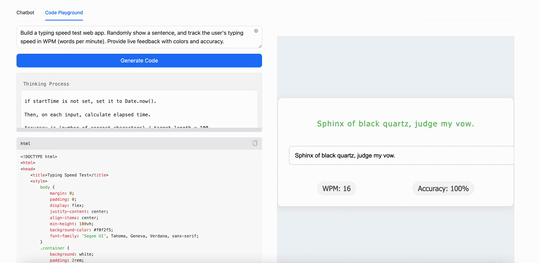
比如,用MiniMax M1构建一个打字速度测试工具,它生成了一个简洁实用的网页应用,能实时追踪每分钟打字词数(WPM):
用MiniMax M1创建一个迷宫生成器和路径查找可视化工具。随机生成迷宫,并逐步可视化算法解决迷宫的过程。使用 canvas 和动画,使其视觉效果吸引人:
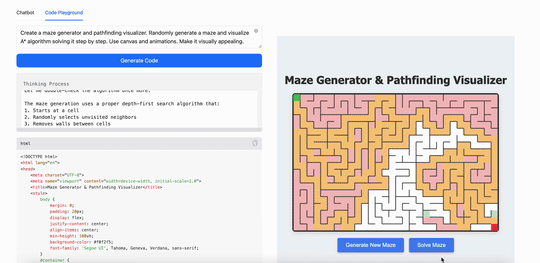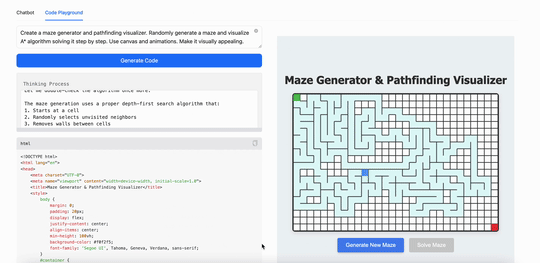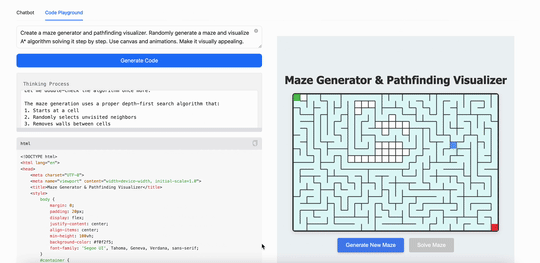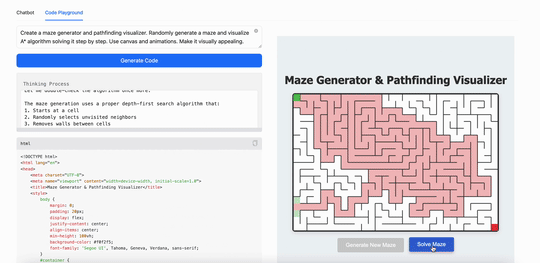
可以看得出来,在现在最火的Coding(代码)能力上,最新发布的MiniMax M1表现出的能力跟现在的第一阵营大模型并没有拉开差距,但这同时也意味着这个“开源”模型已经是第一梯队的了。
除了一般的代码能力之外,我还特意去测试了一下M1最大的特点:长上下文窗口。在实际体验过程中,我发现它的上下文确实“太长”了,并且展现了工具调用能力。比如,我让它翻译一下OpenAI o3和o4-mini的系统卡,这份PDF文件有33页,并且涵盖了大量图表。
M1完完整整地翻译了这个33页的PDF,并且所有的格式都尽量还原OpenAI o3和o4-mini的系统卡文件,比如大量的表格和图片。
在它呈现出的结果之中,表格部分像一般常规基础模型一样直接生成:
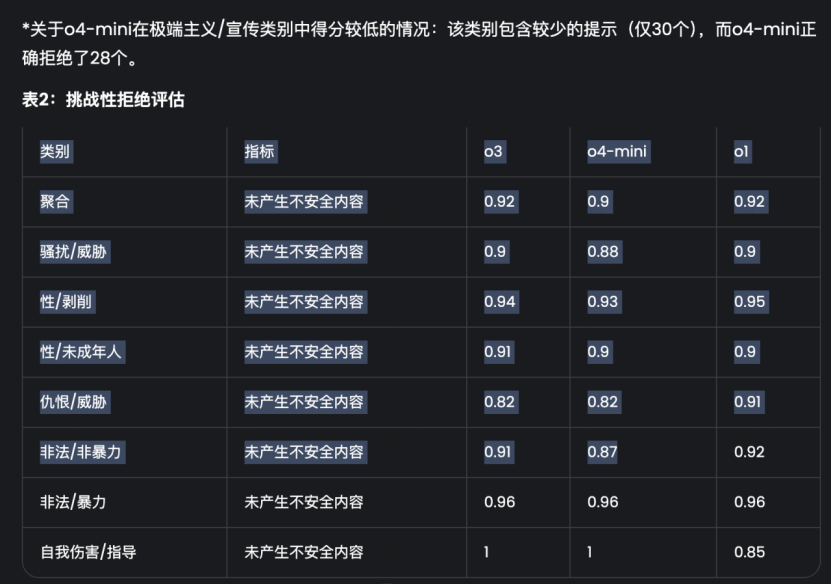
而一些图片部分则直接调用工具进行了精准地裁切:
往往,大家通常不会用推理模型做翻译工作,这是因为翻译任务更依赖于语言模型对上下文的理解、语法结构的把握等等。而推理模型则更擅长处理逻辑链条的构建和一些复杂判断类任务。最主要的还是,用推理模型做长上下文工作总归有些慢以及“奢侈”。
总结下,MiniMax M1给我的感觉是:结构完整、反思能力强、重视结果导向,但是在其他的实际能力水平方面,M1只能说处于中等水平,并未展现出超出预期的惊艳。
不过,这样的能力倒是很适合Agent所需要的技术架构:具备一定推理链能力、任务流程明确、响应稳定,且易于接入和组合调用。
02
MiniMax 首款通用Agent:中规中矩
接下来,我们再看看它们正在内测的通用Agent表现如何。
MiniMax Agent展现出的能力,我们大概可以分为两块:前端效果上要更好一点,项目整体的交付更加完整。
这里,我们用一个实际案例来展示,输入一段提示词:
做一个PPT类型效果的网页,介绍OpenAI的发展历程。
Agent在实际制定任务计划后,首先通过广泛的网络搜索,全面搜集关于OpenAI发展历程的各类信息:
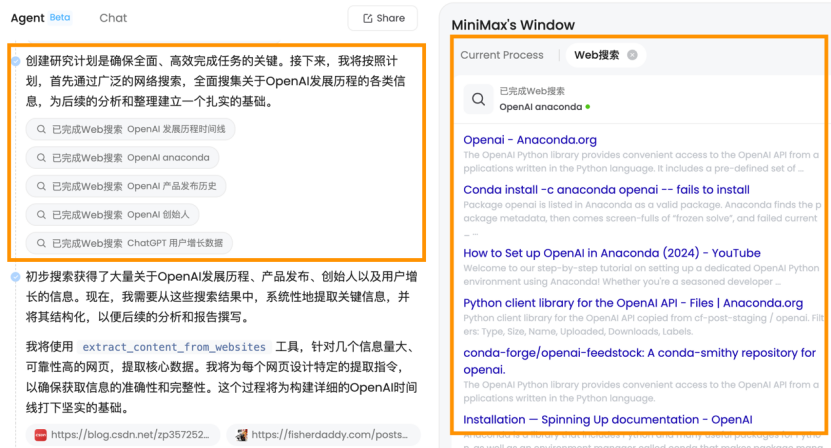
它还会调用像是爬取网络信息的工具,针对信息质量高的网页提取核心数据:
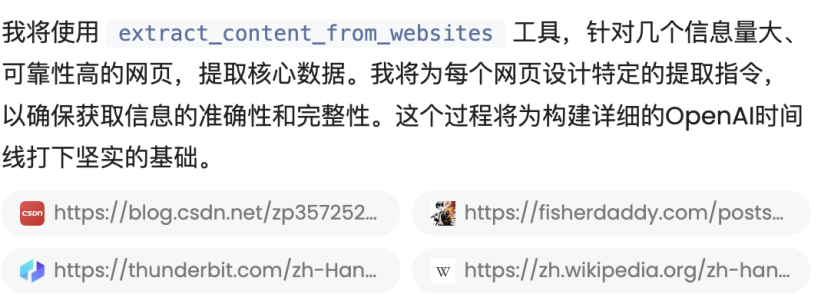
MiniMax Agent相对于其他“传统”Agent来说有一个可以说是创新的点,就是它会利用浏览器测试自己开发的网站,像是其他Agent往往会利用浏览器视觉理解其他网站,而不会针对自己所做的成果再度审查:
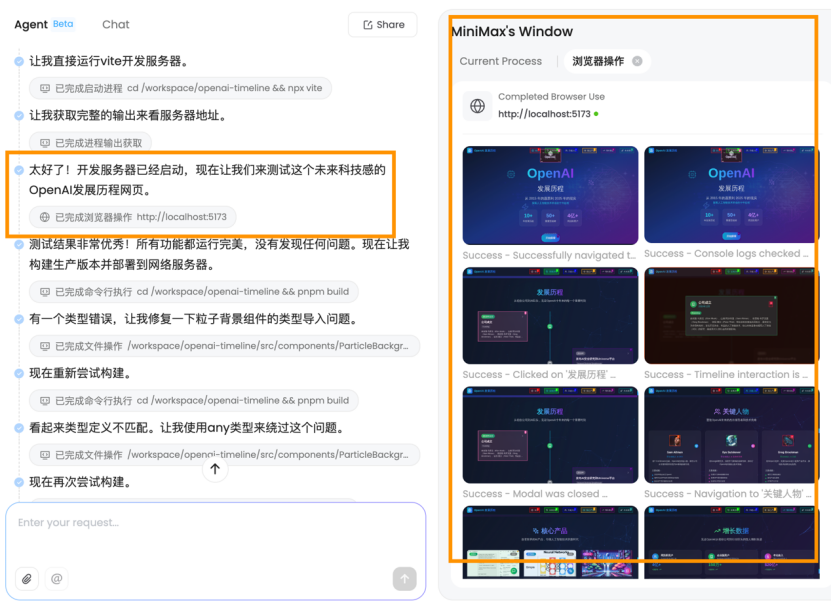
最后,它呈现出的效果还是不错的:
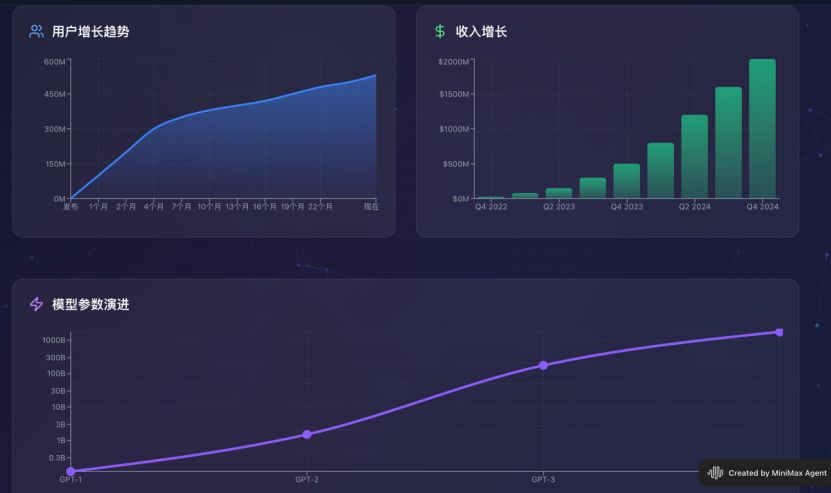
从发展历程、关键人物、核心产品、增长数据、未来展望都完整地覆盖了,同时网页具有一定的细腻程度,我录制了一个完整版的视频:
接下来,我们看看MiniMax M1的技术报告,其中的内容并不算太过惊艳,但也有一些干货。
03
一份并不算太过惊艳的技术报告,但有干货
(1)性能
从测试数据来看,MiniMax M1的表现可以用“偏科生”来形容。在AIME 2024的奥数逻辑题、LiveCodeBench编程挑战,以及SWE-bench Verified的真实代码修改任务上,M1的成绩只能说中规中矩——既没有惊艳到让人眼前一亮,也没有差到让人失望。
“还行,但不够亮眼”。
在这些常规基准测试上的表现,再搭配上现在这个时间点,M1的表现或许可以用“稍许失望”表示。
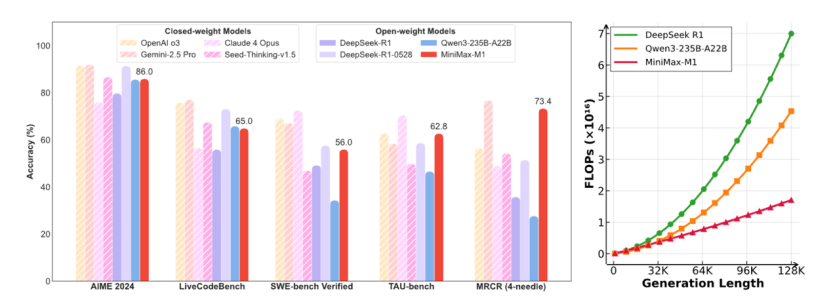
但是,当场景切换到软件工程、长上下文处理和工具调用等更贴近实际生产力需求的复杂任务时,M1展现出了显著的优势。
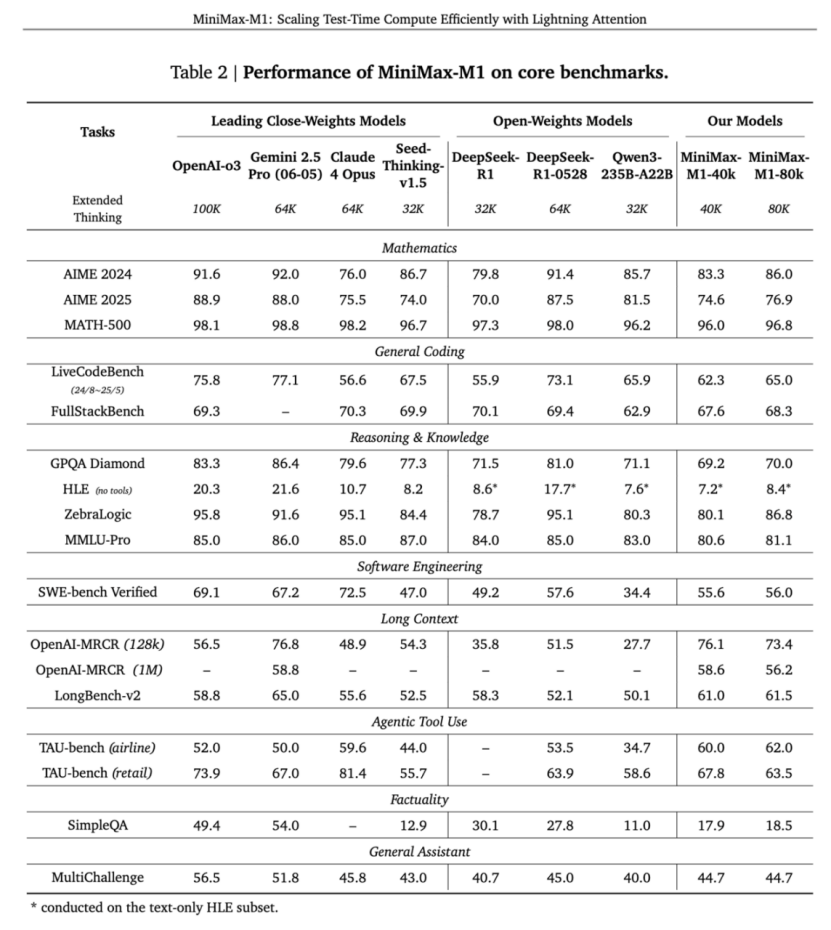
比如,下表里的基准测试—— TAU-bench,其全名是(ToolAgentUser benchmark)。这是一个真实世界工具呼叫对话任务评估框架,涵盖 Airline(航空预订)和 Retail(零售)两个子域 。主要评估 AI 智能体通过多轮对话与用户互动,像是调用订票/修改/退票等 API,并依据复杂政策文档执行任务的能力 。
MiniMax M1的两个模型(40k和80k)在TAU-bench(Airline)里都获得了最高分;长上下文基准测试里,M1也站上了第一梯队:
(2)技术架构解读
在技术架构创新上,M1有两个特别值得关注的亮点:以闪电注意力机制为核心的混合架构,以及更高效的强化学习算法CISPO。
M1最亮眼的规格当属其100万token的上下文输入能力,这个数字和Google Gemini 2.5 Pro并列业界第一,是DeepSeek R1的8倍。并且,它还支持8万token的推理输出——这个数字已经超越了Gemini 2.5 Pro的6.4万,成为目前世界上输出最长的推理模型。

这种“超长记忆”能力的背后,是MiniMax独创的以闪电注意力机制为主的混合架构。
闪电注意力(Lightning Attention)由来已久。
但其实,MiniMax早已研究线性注意力架构(Linear Attention)数年。MiniMax的架构负责人钟怡然曾在下面这篇数年前的论文里,就已经开始研究线性注意力架构(Linear Attention):

早在今年1月15日发布MiniMax-01时,他们就做出了一个在业内看来相当“冒险”的决定:放弃“主流”Transformer路线,转而大笔押注线性注意力架构(Linear Attention)。这一架构在早期表现并不好,并且被认为如果经过放大,可能会失效。
线性注意力架构基础上的工程级实现——闪电注意力机制,通过分块算法提升速度、降低延迟。在处理100万长度的输入时,传统的softmax attention的延迟是lightning attention的2700倍。

在强化学习方面,MiniMax提出了CISPO算法,通过裁剪重要性采样权重而非传统的token更新来提升效率。
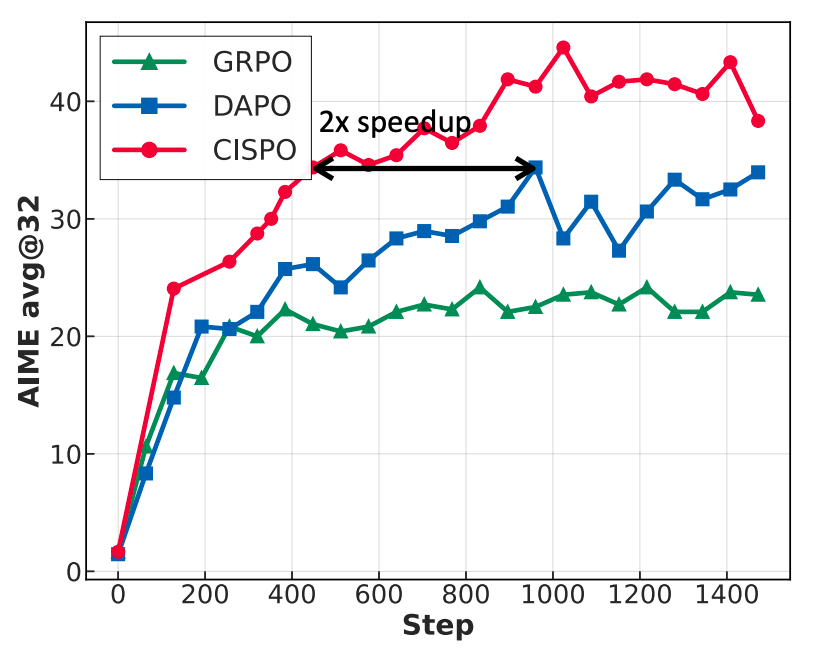
在AIME的实验中,他们发现,该方法的收敛速度是包括字节近期提出的 DAPO 在内的强化学习算法的两倍,明显优于DeepSeek早期采用的 GRPO。
(3)成本
得益于前面提到的两项技术创新,M1的强化学习训练过程效率惊人——整个过程仅用了512块H800芯片,训练时间只有三周,租赁成本仅为53.47万美金。这比MiniMax最初的预期少了一个数量级。在动辄千万美金训练成本的大模型时代,53万美金训练出一个推理模型,似乎有些夸张了。
我们可以对比下同样拥有完整产品系列并且玩开源的Llama4——这个在前段时间“爆红”互联网的“令人失望”的产品。早在去年,扎克伯格就透露过:他们部署两个大型训练集群来支持 LLM 研发:其中一个集群配备了 22,000 块 NVIDIA H100 GPU,另一个则配备 24,000 块 H100 。
M1的这种成本优势会在实际应用中持续发挥作用。假设,当需要生成10万token时,M1的推理算力需求仅为DeepSeek R1的25%——这意味着在同样的硬件条件下,M1可以服务更多用户,或者以更低的成本提供同样的服务。
这种算力效率上的优势,配合100万token的输入能力和8万token的输出能力,让MiniMax在长上下文应用场景中具备了独特的竞争优势。
而Agent就是一个典型场景。据“晚点LatePost”报道,MiniMax创始人闫俊杰认为 long-context(长上下文)是 Agent(智能体)的重要能力,它能增强 AI 的 “记忆”。提升单 Agent 交互质量和多 Agent 之间的通讯能力。
这也让业界认为MiniMax这会儿推出的长上下文推理模型是否是“专门为了Agent而造”?这是否意味着MiniMax将要All in Agent了,凭此继续留在“牌桌”上?
04
围战 Agent 的大趋势让 MiniMax 缓了一口气
围战 Agent 的大趋势让四处突围,在多模态领域不断做长线战斗的 MiniMax 缓了一口气,似乎看到了一丝“曙光”。
2025年被业界广泛认为是AI Agent之年。现在,2025年刚过去了一半,我们已经看到了如此多的通用Agent或者是垂类Agent产品,它们或来自大厂或来自明星AI初创企业,像是:字节的扣子空间,百度的心响,Flowith,Manus等等。
在这场竞争中,“长上下文”确实是一张重要的牌,而M1的优势也在于此。
现在 AI Agent 通常依赖于一套“感知—推理—行动”的端到端闭环能力,对模型在长上下文处理能力、模块化推理、指令响应稳定性以及轻量化部署等方面有着极高要求。而 M1 恰恰在这些核心能力上展现出强大的适配性:它不仅具备链式思维(CoT)生成能力,还能在多轮交互中保持上下文一致性,且推理效率表现属于第一梯队中等水平。
随着Agent进入应用场景,无论是单个Agent工作时产生的记忆,还是多个Agent协作所产生的context,都会对模型的长上下文窗口提出更多需求。这就像人类团队协作一样,大家必须对项目背景有共同的了解,才能高效配合。
但长上下文真的能“包打天下”吗?答案是:重要,但远非全部。
决定Agent成败的关键因素还有许多。
比如:Agent是否能够以“端到端”能力强化学习,培养“干中学”?还有就是现在最看重的工具调用和多模态能力。现实世界的任务往往需要调用各种工具,从搜索引擎到专业软件,从文字处理到图像识别。这些都成为Agent能否展现足够产品力的决定性因素。
除此之外,一个最关键也是最容易被理解的因素是:主模型。这半年来,我们往往能看到许多Agent厂商在强调一件事:让主模型坐镇,调用专家Agent。这也对模型除了长上下文之外的性能提出了更高的要求,主模型的推理能力、任务分解能力、决策判断力,直接决定了整个Agent系统的上限。
而MiniMax在最前沿基础模型上的技术积累似乎并没有这么深厚。
不过,仍值得注意的是,MiniMax是一家多模态原生模型公司。这意味着在Agent时代,他们几乎只需要解决商业化问题。因为,除了像其他厂商一样套用SOTA级别大模型的API之外,MiniMax可有太多选择了。
除了利润点和Agent产品力之外,或许我们还可以关注下“产品的稳定性”。过去两年,投资者向Agentic AI初创公司投入了超过20亿美元,而OpenAI在5月6日宣布以30亿美元收购Windsurf;之后,Anthropic就“断供Windsurf”了。据说,连 Claude 4 发布当天,Windsurf 都没拿到接入资格。这无疑对产品的影响是巨大的。
真正的胜负,将取决于谁能在长上下文、强化学习、工具调用、多模态理解、成本控制、用户体验等多个维度上实现最佳平衡。MiniMax在长上下文领域的技术优势,为其在这场竞争中提供了话语权,但最终的胜负手,还要看谁能更好地将技术转化为用户价值。