人类从农耕时代到工业时代花了数千年,从工业时代到信息时代又花了两百多年,而 LLM 仅出现不到十年,就已将曾经遥不可及的人工智能能力普及给大众,让全球数亿人能够通过自然语言进行创作、编程和推理。
LLM 的技术版图正以前所未有的速度扩张,从不断刷新型号的“模型竞赛”,到能够自主执行任务的智能体,技术的浪潮既令人振奋,也带来了前所未有的挑战。
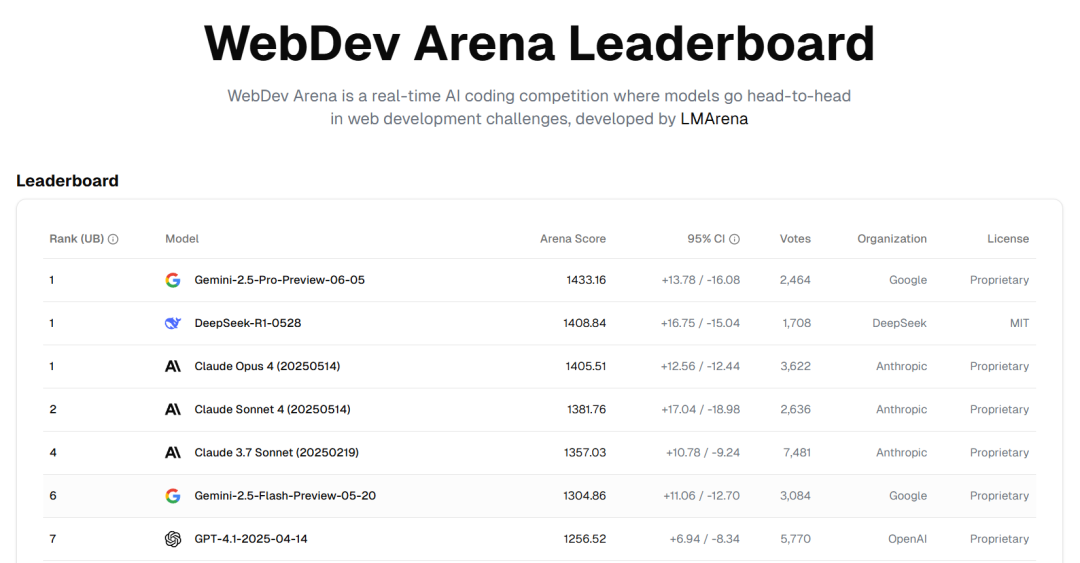
如何在海量信息中建立真正的认知深度,而非仅仅成为一个热点的追随者?也许可以从“做题”开始。
最近,MIT CSAIL 分享了一份由工程师 Hao Hoang 编写的 LLM 面试指南,精选了 50 个关键问题,旨在帮助专业人士和AI爱好者深入理解其核心概念、技术与挑战。

文档链接:https://drive.google.com/file/d/1wolNOcHzi7-sKhj5Hdh9awC9Z9dWuWMC/view
我们将这 50 个问题划分为了几大主题,并附上图示和关键论文。希望这份指南能成为您的“寻宝图”,助您开启 LLM 探索之旅,无论是在面试中,还是在未来的技术浪潮中,都能保持清醒的认知和持续探索的热情。
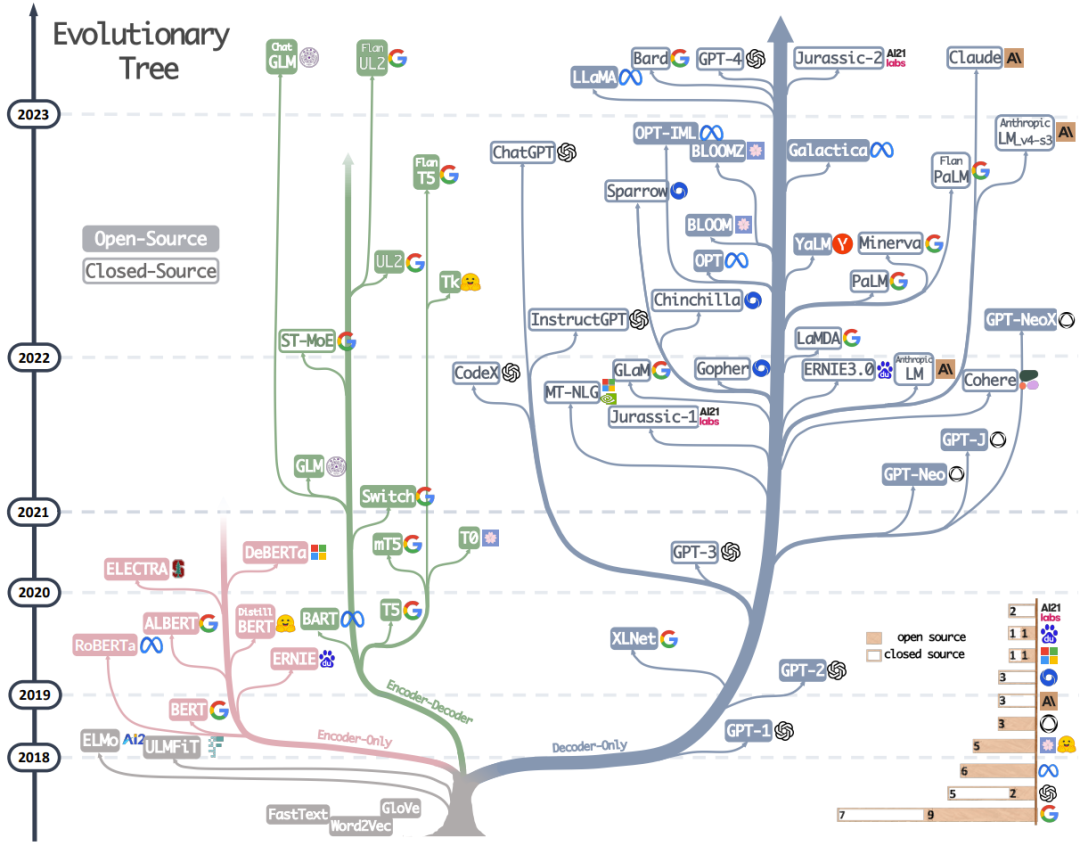
LLM 发展历程。来源:arXiv:2304.13712
核心架构与基本概念
问题 1:Token 化(tokenization)包含哪些内容,为什么它对 LLM 至关重要?
Token 化是将文本分解为更小单元(称为 token)的过程,这些单元可以是单词、词的一部分或字符。例如,单词“artificial”可以被分解为“art”、“ific”和“ial”。
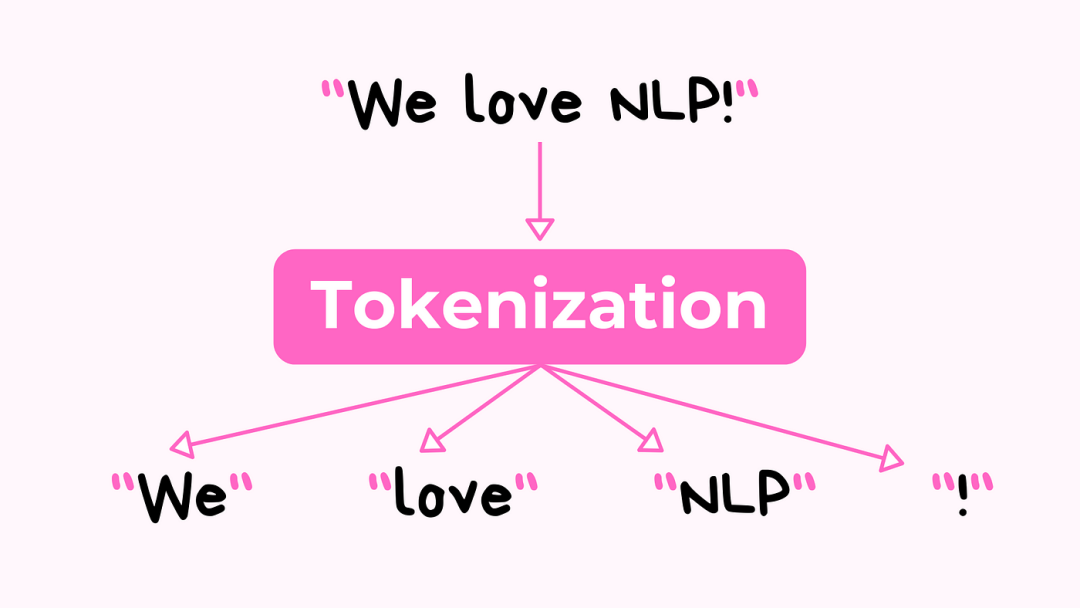
这是一个关键步骤,因为LLM 处理的是这些 token 的数值版本,而不是原始文本。通过 token 化,模型可以处理多种语言,处理稀有词汇或不在其词汇表中的词汇,并保持词汇表大小的可管理性,这反过来提高了计算速度和模型的有效性。
问题 2:注意力机制在 Transformer 模型中如何运作?
注意力机制使 LLM 能够在生成或分析文本时,对序列中的不同 token 分配不同的重要性级别。它通过计算查询(query)、键(key)和值(value)向量之间的相似性分数来确定这些重要性级别,通常通过点积运算来专注于最相关的 token。
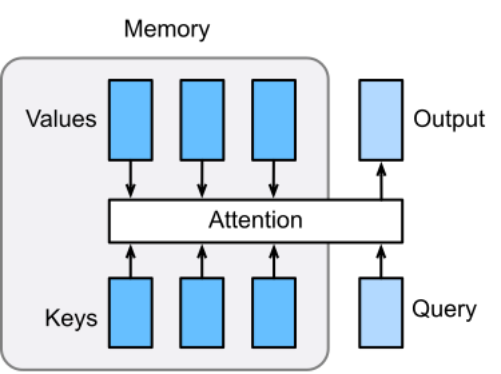
例如,在句子“The cat chased the mouse”中,注意力机制帮助模型将“mouse”与“chased”连接起来。这一功能增强了模型理解上下文的能力,使 Transformer 在自然语言处理任务中非常有效。
问题 3:LLM 中的上下文窗口是什么,为什么它很重要?
上下文窗口是LLM 能够同时处理的 token 数量,它本质上定义了模型理解或创建文本的短期记忆。更大的窗口(例如 32000 个 token)让模型能够考虑更多上下文,在摘要等活动中产生更连贯的结果。另一方面,更大的窗口也意味着更高的计算成本。在窗口大小和运行效率之间找到正确的平衡是在实际场景中使用 LLM 的关键。
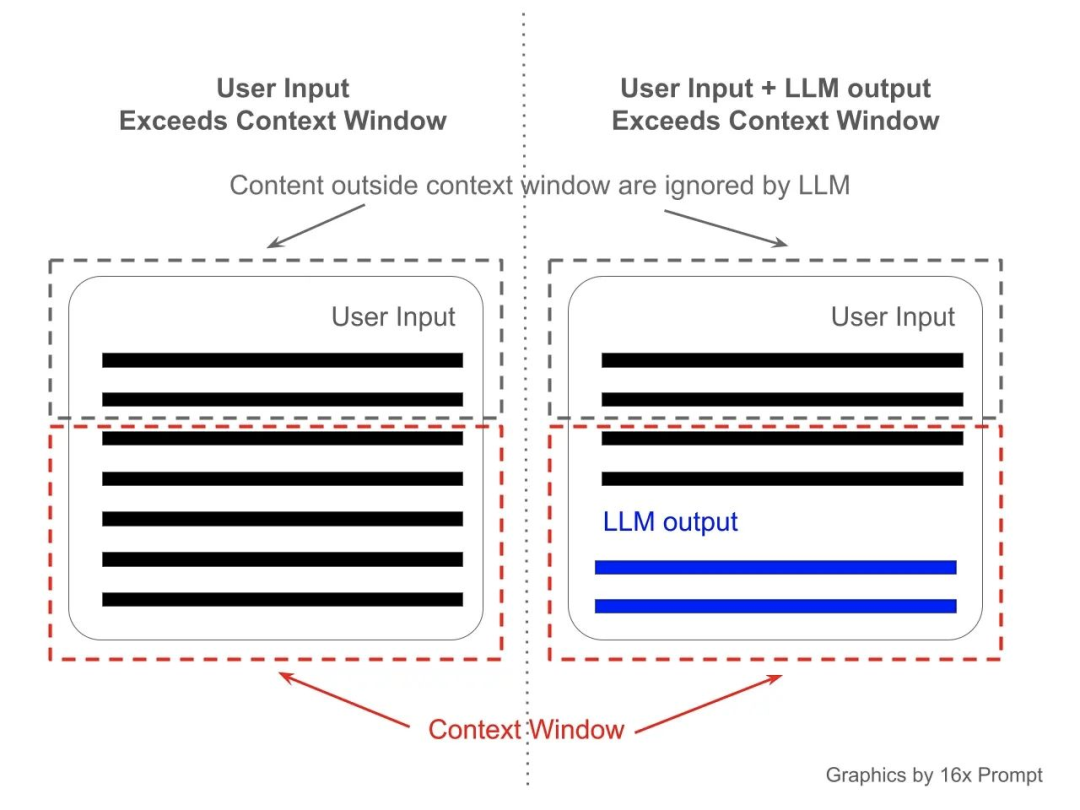
问题 4:序列到序列模型是什么,它们在哪里应用?
序列到序列(Seq2Seq) 模型旨在将输入序列转换为输出序列,输出序列的长度通常可以不同。这些模型由编码器(处理输入)和解码器(创建输出)组成。它们应用于各种场景,如机器翻译(例如,从英语到德语)、文本摘要和聊天机器人,其中输入和输出的长度经常不同。
问题 5:嵌入(embeddings)是什么,它们在 LLM 中如何初始化?
嵌入是在连续空间中代表 token 的紧凑向量,捕获它们的语义和句法特征。它们通常以随机值开始,或者使用像 GloVe 这样的预训练模型,然后在训练过程中进行调整。例如,单词“dog”的嵌入可能会被修改以更好地表示其在宠物相关上下文中的使用,这将提高模型的准确性。
问题 6:LLM 如何处理词汇外(out-of-vocabulary, OOV)单词?
LLM 通过使用子词 token 化方法(如字节对编码,Byte-Pair Encoding)来处理 OOV 单词,将这些单词分解为更小的、熟悉的子词单元。例如,像“cryptocurrency”这样的单词可以被分解为“crypto”和“currency”。这种技术使 LLM 能够处理不常见或新的单词,确保它们能够有效地理解和生成语言。
问题 7:Transformer 如何改进传统的 Seq2Seq 模型?
Transformer 通过几种方式解决了传统 Seq2Seq 模型的缺点:
并行处理:使用自注意力允许同时处理 token,这与 RNN 的序列性质不同。
长距离依赖:注意力机制能够捕获文本中相距较远的 token 之间的关系。
位置编码(Positional Encodings): 这些用于维持序列的顺序。
这些特征导致翻译等任务中更好的可扩展性和性能。
问题 8:位置编码是什么,为什么要使用它们?
位置编码用于向 Transformer 的输入添加关于序列顺序的信息,因为自注意力机制本身没有方法知道 token 的顺序。通过使用正弦函数或学习向量,它们确保像“king”和“crown”这样的 token 能够根据其位置被正确理解,这对翻译等任务至关重要。
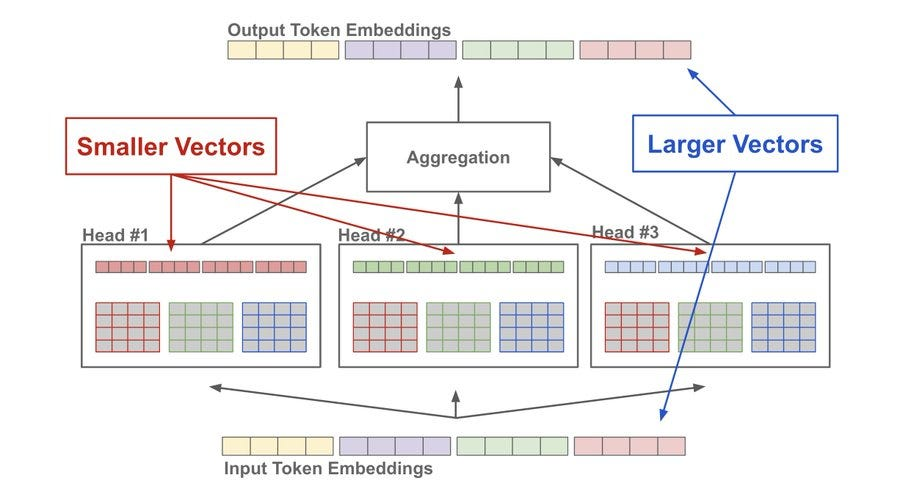
问题 9:多头注意力(multi-head attention) 是什么,它如何增强 LLM?
多头注意力将查询、键和值分成几个较小的部分,这让模型能够同时专注于输入的不同方面。例如,在给定句子中,一个头可能专注于句法,而另一个可能专注于语义。这增强了模型识别复杂模式的能力。
问题 10:Transformer 如何解决梯度消失问题?
Transformer 通过几种机制解决梯度消失问题:
自注意力:这避免了对序列依赖的需要。
残差连接(Residual Connections): 这些为梯度流动创建直接路径。
层归一化(Layer Normalization): 这有助于保持更新的稳定性。
这些特征使得深度模型的有效训练成为可能,这是相对于 RNN 的优势。
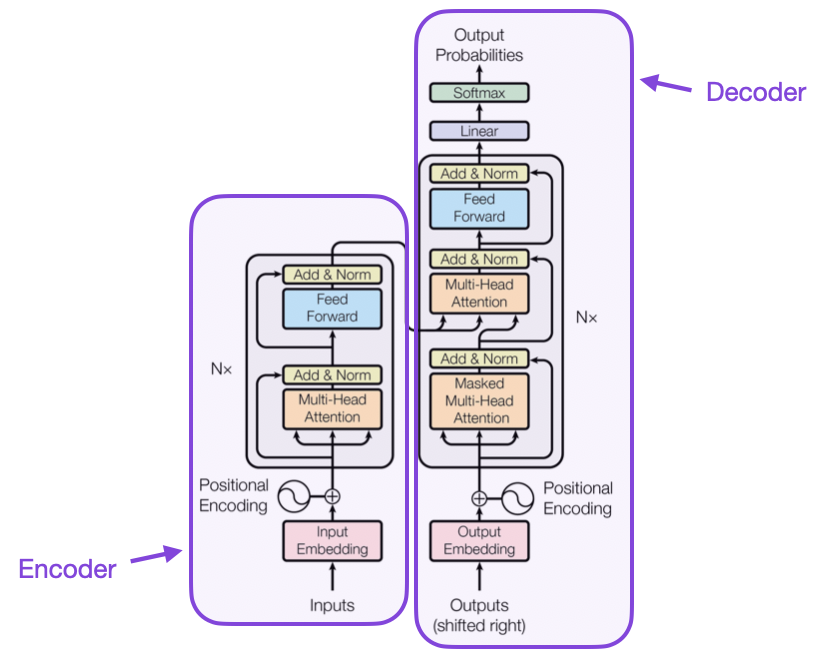
问题 11:在 Transformer 中编码器和解码器有何不同?
编码器负责处理输入序列并将其转换为保持上下文的抽象表示。另一方面,解码器通过使用编码器的表示和先前生成的 token 来生成输出。在翻译的情况下,编码器理解源语言,解码器然后在目标语言中创建输出,这使得有效的序列到序列任务成为可能。
问题 12:什么定义了大型语言模型(LLM)?
LLM 是在广泛文本数据集上训练的 AI 系统,能够理解和产生类似人类的语言。它们的特征是拥有数十亿参数,在翻译、摘要和问答等任务中表现出色,因为它们能够从上下文中学习,这给了它们广泛的适用性。
关键论文
Attention Is All You Need
抛弃了传统的循环和卷积结构,首次提出完全基于自注意力机制的 Transformer 模型,成为当今几乎所有主流 LLM 的架构基础。
https://arxiv.org/abs/1706.03762
Sequence to Sequence Learning with Neural Networks
提出了经典的 Seq2Seq 框架,利用一个 RNN(编码器)读取输入序列,另一个 RNN(解码器)生成输出序列,为机器翻译等任务设定了新的标杆。
https://arxiv.org/abs/1409.3215
Efficient Estimation of Word Representations in Vector Space
提出了 Word2Vec 模型(包含 Skip-gram 和 CBOW 算法),高效地学习到了能捕捉语义关系的词嵌入向量,是现代词表示方法的基石。
https://arxiv.org/abs/1301.3781
模型训练与微调
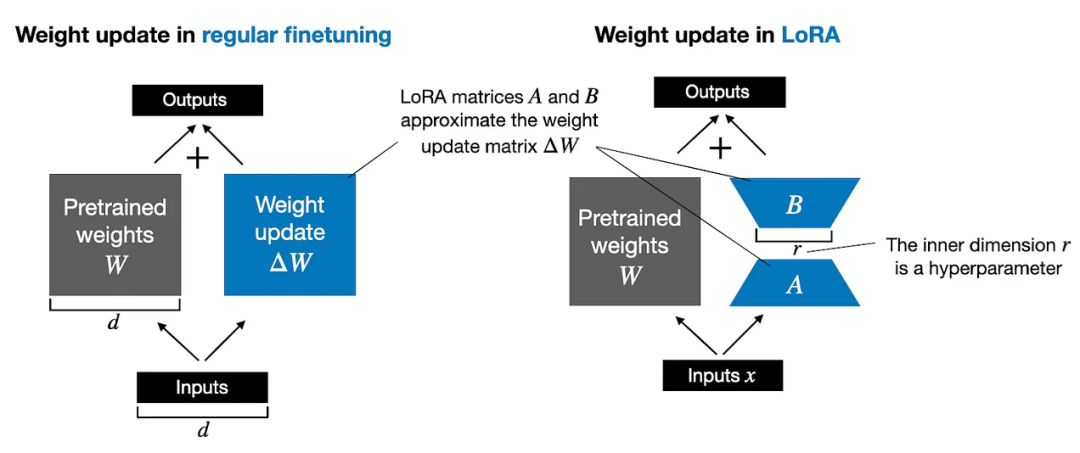
问题 13:LoRA 和 QLoRA 在 LLM 微调中有什么区别?
LoRA(低秩自适应, Low-Rank Adaptation)是一种微调方法,它将低秩矩阵融入模型的层中,允许以极少的内存需求进行高效适应。QLoRA 在此基础上,通过使用量化(例如,到 4 位精度)来进一步减少内存使用,同时仍保持准确性。举例来说,QLoRA 允许在仅一个 GPU 上对拥有 700 亿参数的模型进行微调,这使其成为资源有限情况下的绝佳选择。
问题 14:LLM 如何在微调期间避免灾难性遗忘?
灾难性遗忘是指模型在微调后失去其先前知识的现象。有几种方法可以防止这种情况:
重播(Rehearsal): 在训练过程中将旧数据和新数据混合在一起。
弹性权重整合(Elastic Weight Consolidation): 这种方法优先考虑重要权重以帮助保持现有知识。
模块化架构:为特定任务添加新模块,以防止现有模块被覆盖。
通过使用这些策略,LLM 可以保持多功能性并在各种任务中表现良好。
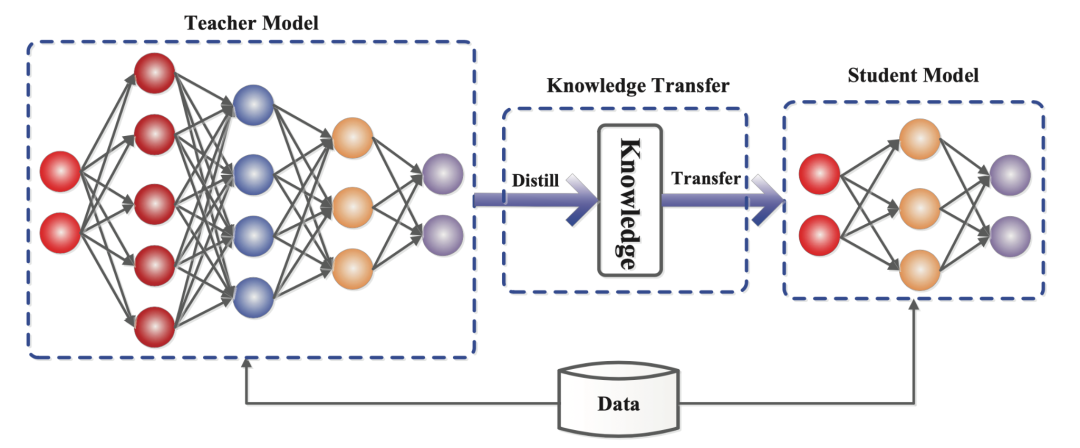
问题 15:模型蒸馏是什么,它如何使 LLM 受益?
模型蒸馏是一个过程,其中较小的“学生”模型被训练来复制较大“教师”模型的输出,通过使用软概率而非严格标签。这种方法减少了所需的内存和处理能力,使得模型能够在智能手机等设备上使用,同时仍能实现接近教师模型的性能,使其非常适合实时应用。
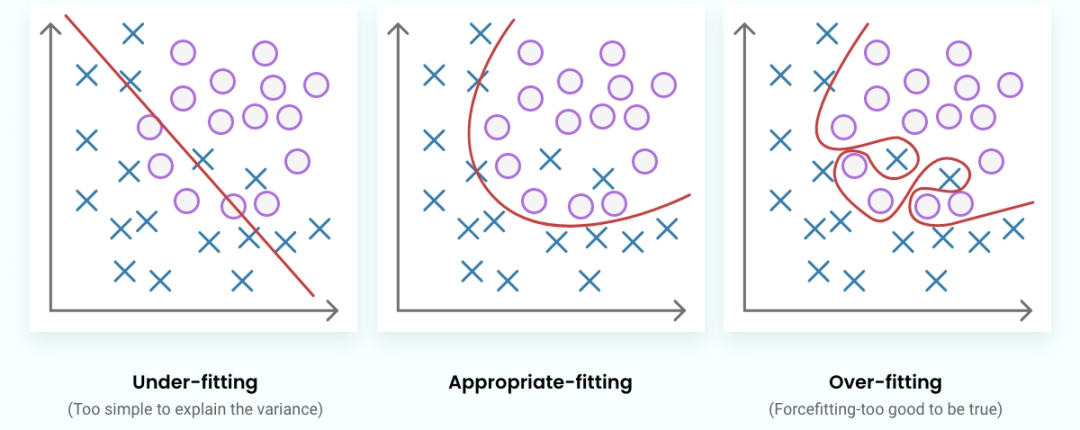
问题 16:什么是过拟合(overfitting),在 LLM 中如何缓解?
过拟合是指模型过度学习训练数据,以至于无法泛化到新数据的现象。减少过拟合的方法包括:
正则化:使用 L1/L2 惩罚等技术来简化模型。
Dropout: 在训练过程中随机停用神经元。
早停(Early Stopping): 当模型在验证集上的性能不再改善时停止训练。
这些方法有助于确保模型能够对未见过的数据做出稳健的泛化。
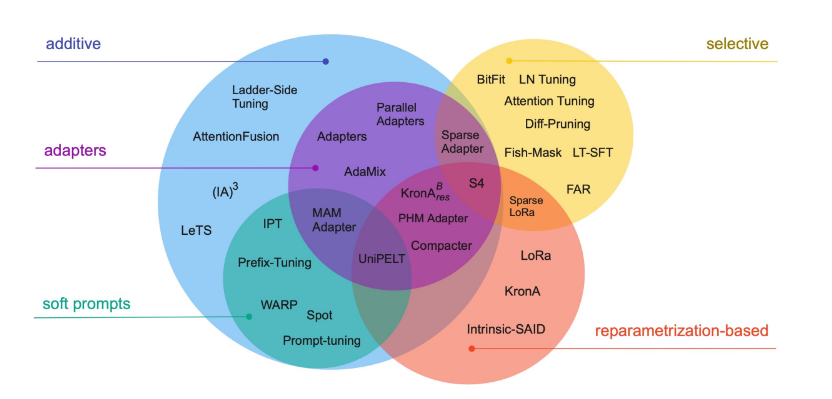
问题 17:PEFT 如何缓解灾难性遗忘?
参数高效微调(PEFT)通过只更新模型参数的一小部分,同时保持其余部分冻结以维持预训练期间获得的知识来工作。诸如 LoRA 等方法允许 LLM 适应新任务而不牺牲其基本能力,有助于确保在不同领域的一致性能。
问题 18:超参数(hyperparameter)是什么,为什么它很重要?
超参数是在训练前设置的值(如学习率或批次大小),它们指导模型的训练过程。这些设置影响模型的收敛性和性能;例如,过高的学习率可能导致不稳定。调整超参数是优化 LLM 效率和准确性的方法。
关键论文
Adam: A Method for Stochastic Optimization
提出了 Adam 优化器,它结合了动量(Momentum)和 RMSprop 的优点,成为训练深度神经网络(包括 LLM)最常用、最有效的默认优化算法。
https://arxiv.org/abs/1412.6980
LoRA: Low-Rank Adaptation of Large Language Models
提出了低秩适配(LoRA)方法,通过仅训练少量注入的、低秩的矩阵来实现参数高效微调(PEFT),极大地降低了微调 LLM 的计算和存储成本。
https://arxiv.org/abs/2106.09685
Distilling the Knowledge in a Neural Network
系统性地提出了“知识蒸馏”的概念,即训练一个小模型(学生)来模仿一个大模型(教师)的行为,从而在保持大部分性能的同时实现模型压缩和加速。
https://arxiv.org/abs/1503.02531
文本生成与推理技术
问题 19:束搜索(beam search)相比贪婪解码如何改善文本生成?
在文本生成过程中,束搜索同时考虑多个可能的词序列,在每个阶段保留前“k”个候选(称为束)。这与贪婪解码形成对比,后者在每步只选择单个最可能的单词。通过使用这种方法(例如 k 值为 5),输出更加连贯,因为它在概率和多样性之间取得平衡,这对机器翻译或对话创建等任务特别有用。
问题 20:温度在控制 LLM 输出中起什么作用?
温度是一个调节在生成文本时 token 选择随机性程度的设置。低温度(如 0.3)使模型偏向高概率 token,导致可预测的文本。相反,高温度(如 1.5)通过使概率分布变得更平坦来提高多样性。温度设置为 0.8 通常用于在故事创作等活动中实现创造性和连贯性的良好平衡。

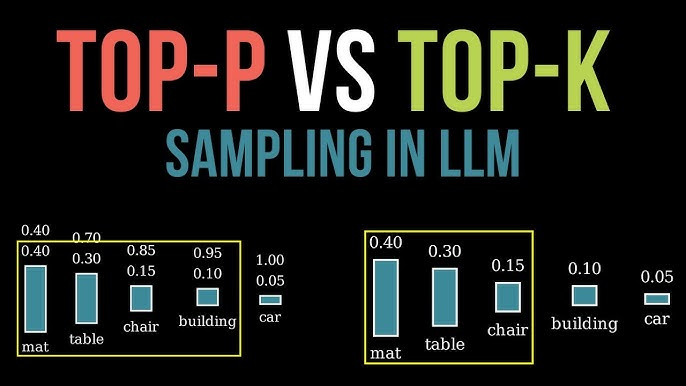
问题 21:top-k 采样和 top-p 采样在文本生成中有何不同?
Top-k 采样将下一个 token 的选择范围缩小到“k”个最可能的选项(例如,k=20),然后从这个较小的群体中采样,这允许受控的多样性。Top-p (或核采样)采样则从概率组合超过某个阈值“p”(如 0.95)的 token 群体中选择,这意味着群体大小可以根据上下文而变化。Top-p 提供更大的适应性,产生既多样又逻辑的输出,这对创意写作有益。
问题 22:为什么提示工程对 LLM 性能至关重要?
提示工程是创建特定输入以从LLM 获得期望响应的实践。定义明确的提示(如“用 100 个单词总结这篇文章”)比模糊的提示产生更相关的输出。这种技术在零样本或少样本场景中特别有用,因为它允许 LLM 在不需要大量微调的情况下执行翻译或分类等任务。
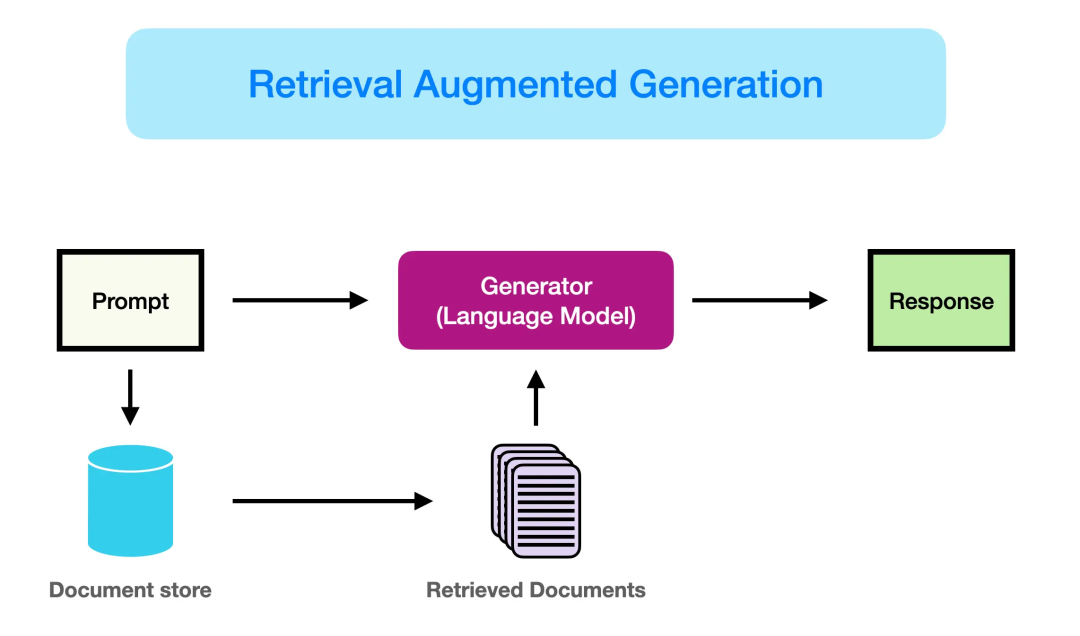
问题 23:检索增强生成(RAG)包含哪些步骤?
RAG 过程包含以下步骤:
检索:使用查询嵌入找到相关文档。
排序:根据相关性对检索到的文档进行排序。
生成:最后,使用检索文档的上下文创建准确答案。
RAG 用于提高问答等任务中答案的事实正确性。
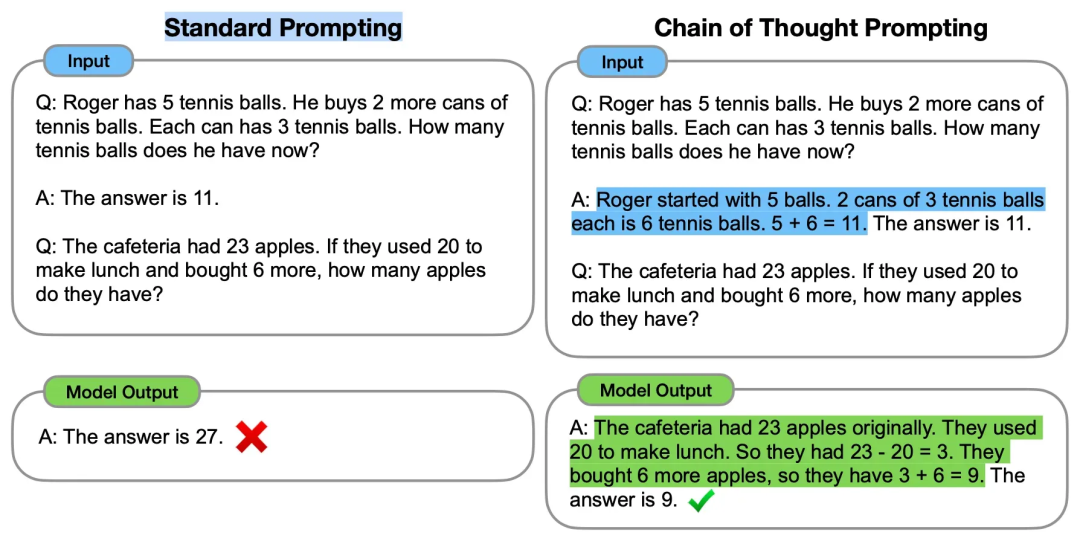
问题 24:思维链提示是什么,它如何帮助推理?
CoT 提示是一种引导 LLM 以类似人类推理的逐步方式处理问题的技术。例如,在解决数学问题时,它将计算分解为一系列逻辑步骤,这在逻辑推理或需要多步骤的查询等复杂任务中产生更好的准确性并使推理过程更容易理解。
关键论文
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
提出了思维链(CoT)提示法,通过引导模型在回答前先生成一步步的推理过程,显著提升了 LLM 在算术、常识和符号推理任务上的表现。
https://arxiv.org/abs/2201.11903
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
提出了 RAG 框架,将预训练的语言模型与非参数化的外部知识库(通过检索器访问)相结合,有效减少了模型幻觉,并能轻松更新知识。
https://arxiv.org/abs/2005.11401
The Curious Case of Neural Text Degeneration
深入分析了传统解码策略(如束搜索)为何会产生重复、乏味和不合逻辑的文本,并提出了核采样(Nucleus Sampling,或 top-p),成为一种主流的高质量文本生成解码策略。
https://arxiv.org/abs/1904.09751
训练范式与学习理论
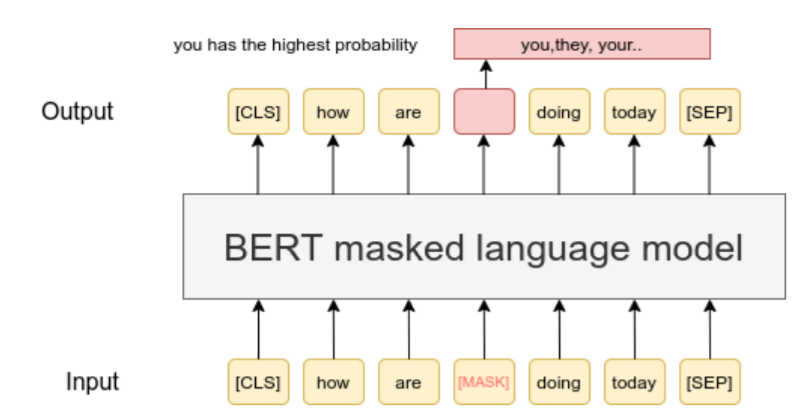
问题 25:掩码语言建模是什么,它如何帮助预训练?
掩码语言建模(MLM)是一种训练技术,其中文本序列中的随机 token 被隐藏,模型需要基于周围上下文来预测它们。这种方法被用于像 BERT 这样的模型中,鼓励对语言的双向理解,使模型能够更好地理解语义连接。这种预训练为 LLM 准备了各种任务,包括情感分析和问答。
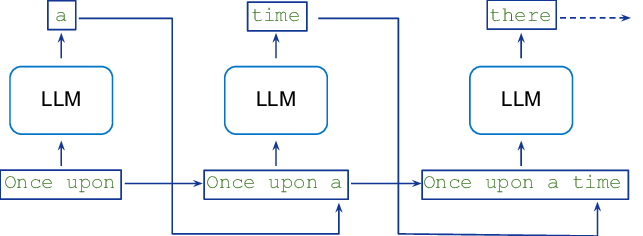
问题 26:自回归模型和掩码模型在 LLM 训练中有何不同?
自回归模型(如 GPT)基于之前的 token 逐个生成 token,这使它们在完成文本等创造性任务中表现出色。相反,掩码模型(如 BERT)通过观察双向上下文来预测隐藏的 token,这使它们更适合像分类这样的理解任务。这些模型的训练方式决定了它们在生成或理解方面的不同优势。
问题 27:下句预测是什么,它如何增强 LLM?
下句预测(NSP)是一种训练方法,其中模型学习判断两个句子是否逻辑上连续或不相关。在预训练阶段,像 BERT 这样的模型被教导对句子对进行分类,一半是连续的(正例),另一半是随机的(负例)。NSP 通过使模型理解句子间的关系,帮助改善对话系统和文档摘要等应用中的连贯性。
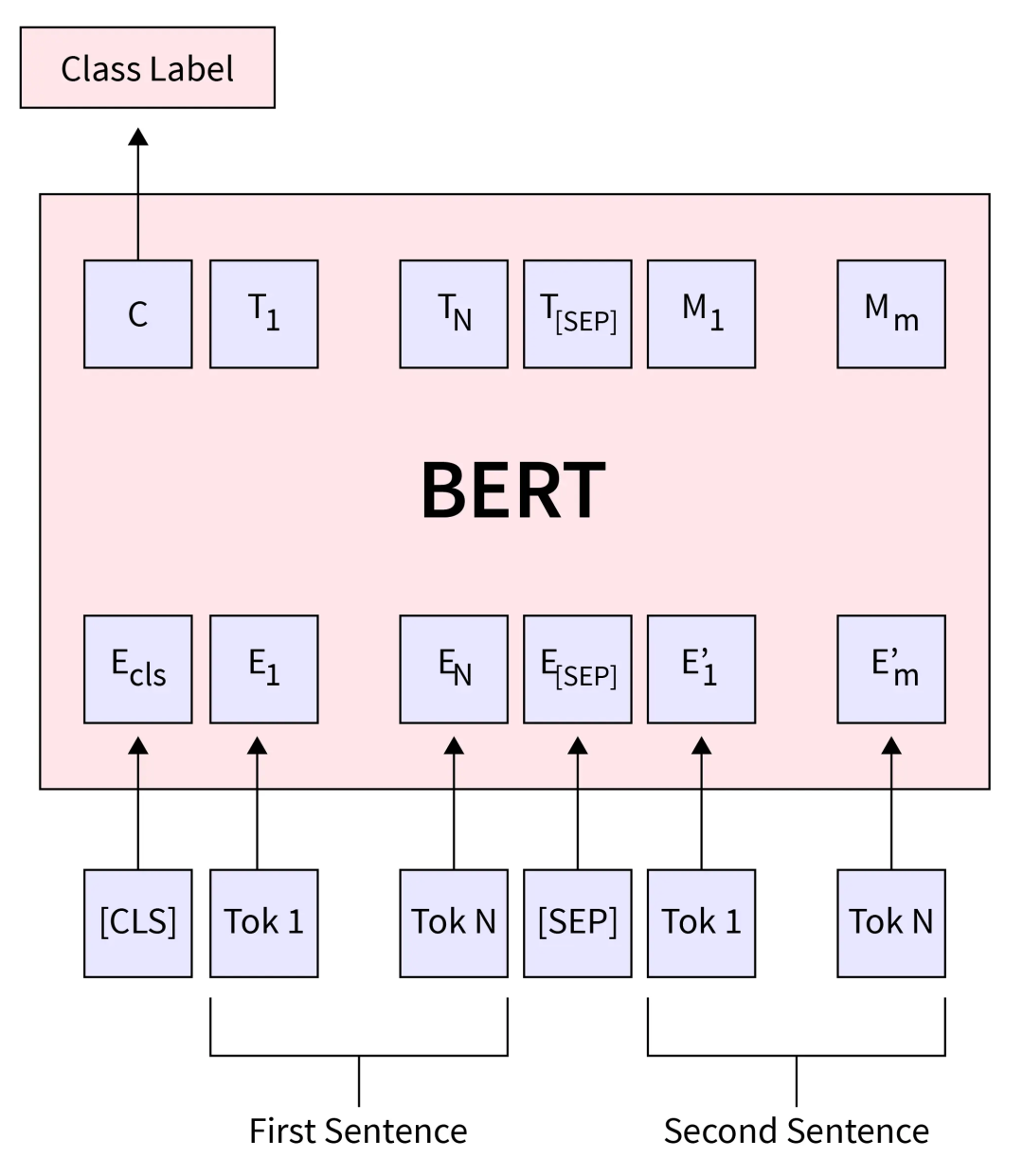
问题 28:在 NLP 中生成式模型与判别式模型有何区别?
生成式模型(如 GPT)通过建模数据的联合概率来创建文本或图像等新内容。另一方面,判别式模型(如用于分类的 BERT)建模条件概率来区分类别,如情感分析中的情况。生成式模型最擅长创造新事物,而判别式模型专注于做出准确的分类。
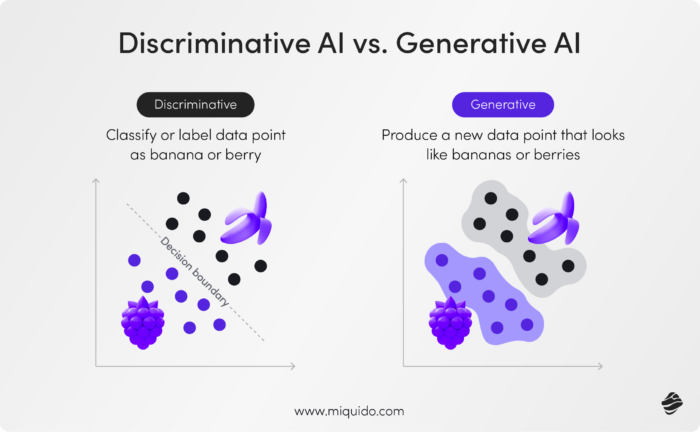
问题 29:判别式 AI 和生成式 AI 有何不同?
判别式AI(如情感分类器)通过基于输入特征预测标签来工作,涉及建模条件概率。另一方面,生成式 AI(如 GPT)通过建模联合概率来创建新数据,使其非常适合文本或图像生成等任务并提供创造性自由。
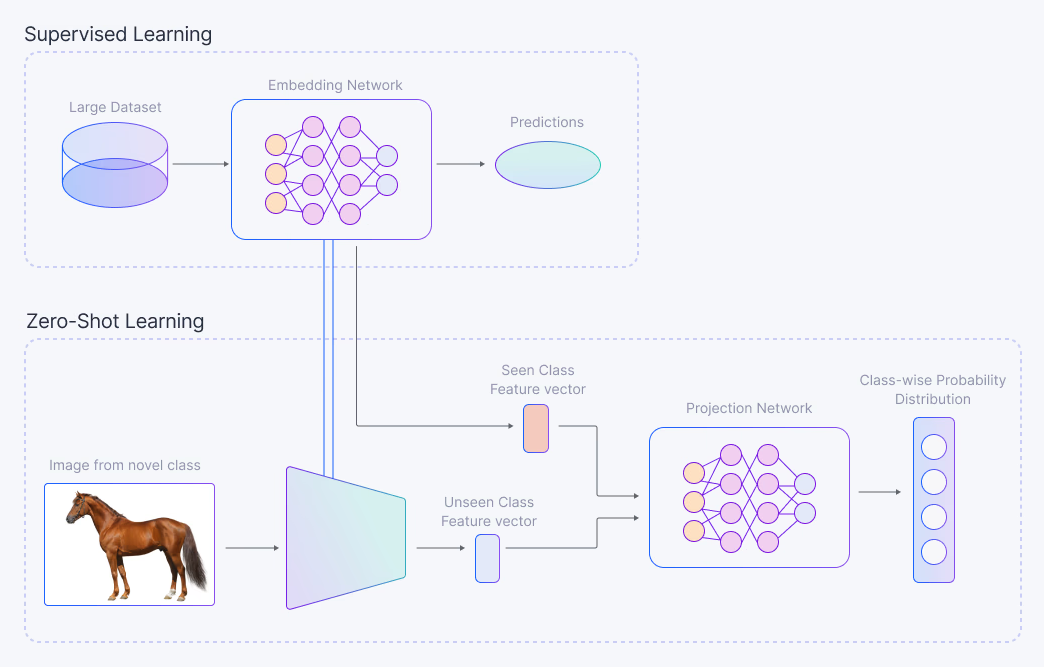
问题 30:零样本学习是什么,LLM 如何实现它?
零样本学习是LLM 通过利用预训练期间获得的一般知识来执行未经专门训练的任务的能力。例如,如果向 LLM 提示“将这个评论分类为积极或消极”,它可以在没有针对该特定任务训练的情况下确定情感,这展示了其适应性。
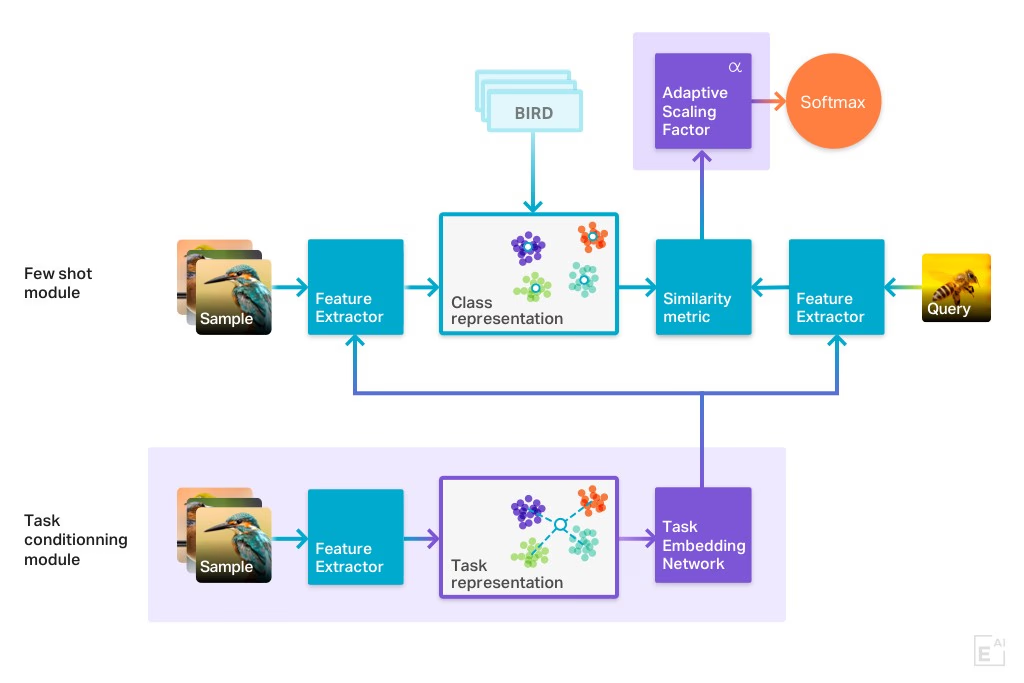
问题 31:少样本学习是什么,它有什么好处?
少样本学习允许LLM 通过利用其预训练知识仅用少数例子就能承担任务。这种方法的优势包括减少对数据的需求、更快适应新任务和节省成本,这使其成为特定类型文本分类等专业任务的绝佳选择。
关键论文
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
提出了BERT 模型及其核心训练任务“掩码语言模型”(MLM),通过双向上下文来预训练模型,极大地提升了模型对语言的深层理解能力,成为理解任务的里程碑。
https://arxiv.org/abs/1810.04805
Improving Language Understanding by Generative Pre-Training
提出了生成式预训练(Generative Pre-Training, GPT)范式,即先在海量无标签数据上进行自回归预训练,再针对下游任务进行微调,奠定了 GPT 系列模型的基础。
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
Language Models are Unsupervised Multitask Learners
这篇是GPT-2 的论文,它证明了通过在更大、更多样的数据集上训练一个足够大的自回归模型,可以使其在没有明确监督的情况下执行多种任务(零样本学习)
,展示了语言模型强大的泛化能力。
https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
数学原理与优化算法
问题 32:Softmax 函数如何应用于注意力机制?
Softmax 函数使用公式
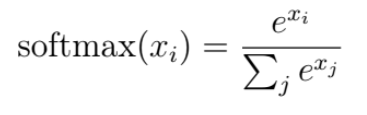
将注意力分数转换为概率分布。在注意力的上下文中,它将来自查询和键的点积的原始相似性分数转换为权重,有助于更强调相关的 token。这确保模型专注于对上下文重要的输入部分。
问题 33:点积如何对自注意力起作用?
在自注意力机制中,查询(Q)和键(K)向量的点积用于计算相似性分数,如公式
所示。高分数意味着token 彼此相关。虽然这种方法是高效的,但它对长序列具有
的二次复杂度,这导致了对稀疏注意力等其他选择的研究。
问题 34:为什么在语言建模中使用交叉熵损失(cross-entropy loss)?
交叉熵损失用于衡量模型预测的token 概率与实际概率之间的差异,根据公式
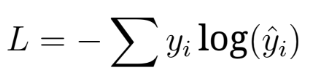
它通过惩罚错误的预测来工作,推动模型做出更准确的token 选择。在语言建模中,这确保模型给正确的下一个 token 高概率,有助于优化其性能。
问题 35:在 LLM 中如何计算嵌入的梯度?
嵌入的梯度在反向传播过程中使用链式法则计算,遵循方程式
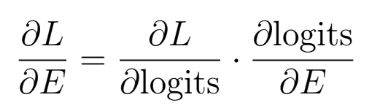
这些梯度然后用于修改嵌入向量,以减少损失,从而细化它们的语义表示并在任务中获得更好的性能。
问题 36:雅可比矩阵(Jacobian matrix)在 Transformer 反向传播中的作用是什么?
雅可比矩阵用于表示输出相对于输入的偏导数。在 Transformer 中,它对于计算多维输出的梯度起关键作用,确保权重和嵌入在反向传播期间得到正确更新。这对复杂模型的优化至关重要。
问题 37:特征值和特征向量如何与降维相关?
特征向量显示数据变化的主要方向,特征值表示这些方向上的变化量。在 PCA 等方法中,选择具有高特征值的特征向量允许在保持大部分方差的同时进行降维,这为 LLM 处理提供了更高效的数据表示。
问题 38:KL 散度(KL divergence)是什么,它在 LLM 中如何使用?
KL 散度是衡量两个概率分布之间差异的度量,计算为
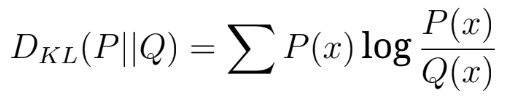
在LLM 的上下文中,它用于评估模型的预测与真实分布的吻合程度,有助于指导微调过程以增强输出质量及其与目标数据的对齐。
问题 39:ReLU 函数的导数是什么,为什么它很重要?
ReLU 函数定义为
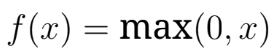
其导数当x > 0 时为 1,否则为 0。其稀疏性和非线性特征有助于避免梯度消失问题,使 ReLU 成为 LLM 中计算高效且流行的稳健训练选择。
问题 40:链式法则(chain rule)如何应用于 LLM 中的梯度下降?
链式法则用于找到由其他函数组成的函数的导数,遵循公式
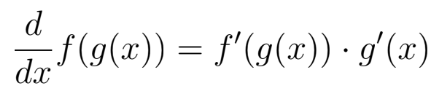
在梯度下降中使用时,它通过允许逐层计算梯度来促进反向传播,从而实现参数的高效更新以最小化深度 LLM 架构中的损失。
问题 41:在 Transformer 中如何计算注意力分数?
注意力分数的计算由公式
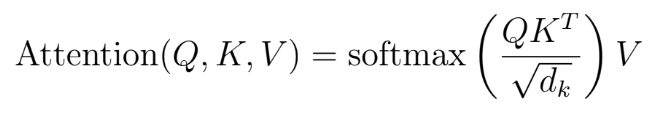
给出。缩放点积用于确定token 的相关性,Softmax 函数然后将这些分数归一化以专注于最重要的 token,这改善了摘要等任务中的上下文感知生成。
问题 42:自适应 Softmax 如何优化 LLM?
自适应 Softmax 通过根据词汇出现频率对其进行分类来提高效率,减少不常见词汇所需的计算。这种方法降低了管理大型词汇表的成本,导致更快的训练和推理时间,同时保持准确性,在资源有限的环境中特别有用。
关键论文
Deep Residual Learning for Image Recognition
提出了残差网络(ResNet),通过引入“残差连接”(Shortcut Connections)有效解决了深度神经网络中的梯度消失问题,使得训练数百甚至上千层的网络成为可能。这一思想被 Transformer 架构所借鉴。
https://arxiv.org/abs/1512.03385
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
提出了批量归一化(Batch Normalization),一种稳定和加速神经网络训练的强大技术。Transformer 中使用的层归一化(Layer Normalization)也源于类似的思想。
https://arxiv.org/abs/1502.03167
高级模型与系统设计
问题 43:GPT-4 在功能和应用方面与 GPT-3 有何不同?
GPT-4 在几个方面改进了 GPT-3:
多模态输入:它可以处理文本和图像。
更大的上下文:它可以处理多达25000 个 token,相比之下 GPT-3 只能处理 4096 个。
增强的准确性:由于更好的微调,它犯的事实错误更少。
这些进步使其能够用于更广泛的应用,包括视觉问答和复杂对话。
问题 44:Gemini 如何优化多模态 LLM 训练?
Gemini 通过几种方式提高效率:
统一架构:它集成文本和图像处理以更高效地使用参数。
先进注意力:它利用更先进的注意力机制来增强跨模态学习的稳定性。
数据效率:它采用自监督方法来减少对标注数据的依赖。
这些特征使Gemini 相比 GPT-4 等模型成为更稳定和可扩展的选择。
问题 45:存在哪些类型的基础模型(foundation models)?
基础模型可以分类为:
语言模型:包括BERT 和 GPT-4 等模型,用于基于文本的任务。
视觉模型:例如ResNet,用于图像分类等任务。
生成模型:DALL-E 是用于创建新内容的模型示例。
多模态模型:CLIP 是同时处理文本和图像的模型。
这些模型利用广泛的预训练来适用于各种用途。
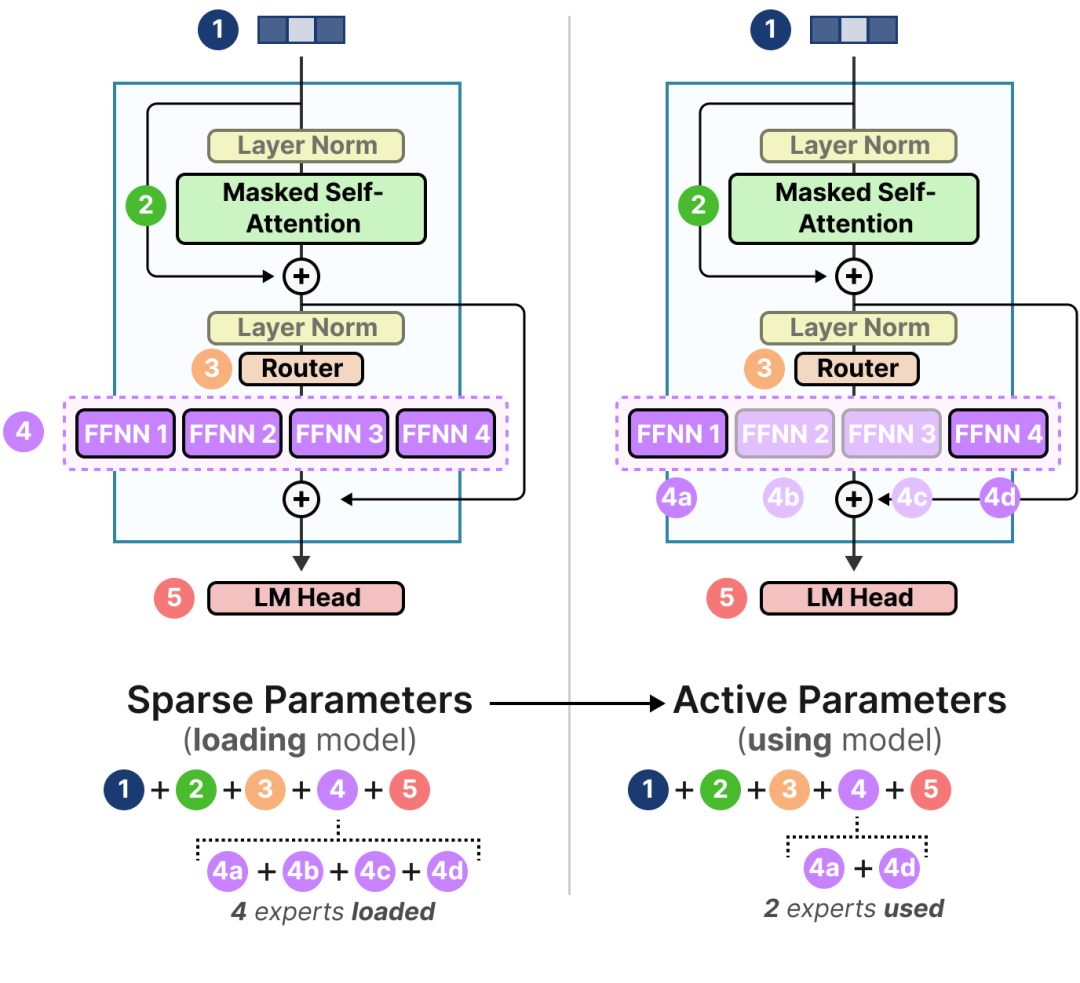
问题 46:专家混合(MoE)如何增强 LLM 的可扩展性?
MoE 使用门控函数将每个输入导向特定的专家子网络,有助于降低计算需求。例如,对于任何给定查询,可能只有 10% 的模型参数被激活,这允许拥有数十亿参数的模型高效运行,同时仍提供高性能。
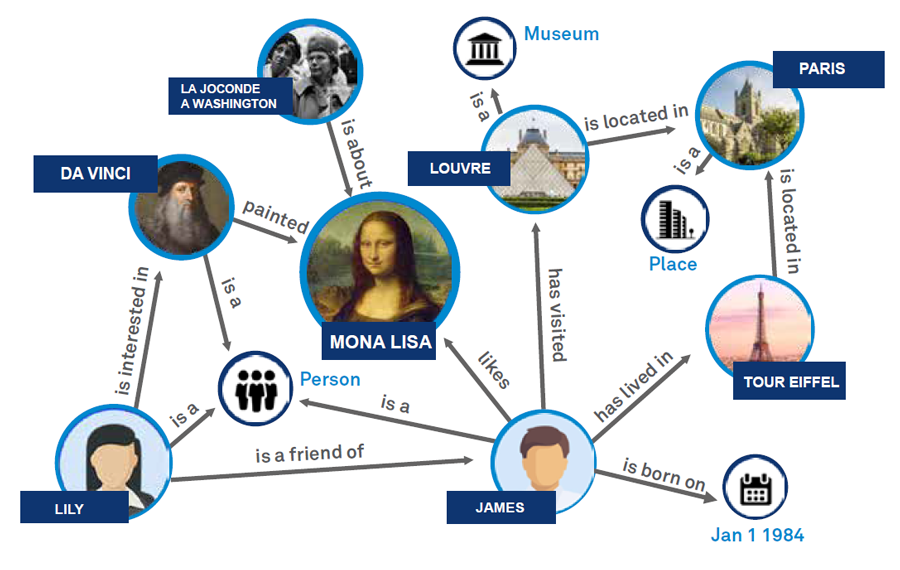
问题 47:知识图谱集成如何改善 LLM?
知识图谱以几种方式为LLM 提供结构化的事实信息:
减少幻觉(Hallucinations): 它们允许根据图谱验证事实。
改善推理:它们利用实体间的关系来改善推理。
增强上下文:它们提供结构化上下文,产生更好的响应。
这对问答和实体识别等应用特别有益。
关键论文
Language Models are Few-Shot Learners
这篇是GPT-3 的论文,它通过将模型参数扩展到前所未有的 1750 亿,展示了 LLM 强大的少样本(Few-Shot)甚至零样本(Zero-Shot)上下文学习能力,用户只需在提示中给出少量示例即可完成任务。
https://arxiv.org/abs/2005.14165
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
提出了稀疏门控的专家混合(MoE)层,允许模型在保持每个输入计算成本不变的情况下,将参数量扩展到万亿级别,是实现当今最高效、最大规模 LLM 的关键技术。
https://openreview.net/pdf?id=B1ckMDqlg
Gemini: A Family of Highly Capable Multimodal Models
作为技术报告,它介绍了原生多模态模型Gemini 的设计。Gemini 从一开始就被设计为可以无缝地理解和处理文本、代码、音频、图像和视频等多种信息类型。
https://arxiv.org/abs/2312.11805
应用、挑战与伦理
问题 48:如何修复生成有偏见或错误输出的 LLM?
要纠正LLM 的有偏见或不准确输出,您需要采取以下步骤:
分析模式:寻找数据或所使用提示中偏见的来源。
改进数据:使用平衡的数据集并应用技术来减少偏见。
微调:使用策划的数据重新训练模型或采用对抗方法。
这些行动有助于改善公平性和准确性。
问题 49:LLM 与传统统计语言模型有何不同?
LLM 基于 Transformer 架构构建,在庞大数据集上训练,并使用无监督预训练,而统计模型(如 N-grams)依赖于更简单的监督技术。LLM 能够管理长距离依赖,使用上下文嵌入,执行广泛的任务,但它们也需要大量的计算能力。
问题50:LLM 在部署中面临哪些挑战?
部署LLM 相关的挑战包括:
资源密集性:它们有很高的计算需求。
偏见:存在它们可能延续训练数据中存在的偏见的风险。
可解释性:它们的复杂性使它们难以解释。
隐私:数据安全存在潜在问题。
处理这些挑战对于确保LLM 的道德和有效使用是必要的。
关键论文
On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?
这篇论文引发了广泛的讨论,它批判性地审视了大规模语言模型存在的偏见、环境成本、不可解释性等风险,并对未来发展方向提出了警示。
https://dl.acm.org/doi/pdf/10.1145/3442188.3445922
Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings
系统性地揭示并量化了词嵌入中存在的社会偏见(如性别偏见),并提出了消除这些偏见的算法,是研究 AI 公平性和偏见的早期关键工作。
https://arxiv.org/abs/1607.06520
Survey of Hallucination in Natural Language Generation
作为一篇综述性论文,它全面地总结和分类了LLM 中的“幻觉”(即生成与事实不符或无意义内容)现象,分析了其成因、评估方法和缓解策略。
https://arxiv.org/abs/2202.03629