炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!

当前,Agentic RAG(Retrieval-Augmented Generation)正逐步成为大型语言模型访问外部知识的关键路径。但在真实实践中,搜索智能体的强化学习训练并未展现出预期的稳定优势。一方面,部分方法优化的目标与真实下游需求存在偏离,另一方面,搜索器与生成器间的耦合也影响了泛化与部署效率。
我们(UIUC & Amazon)提出的s3(Search-Select-Serve)是一种训练效率极高、结构松耦合、生成效果导向的 RL 范式。该方法使用名为Gain Beyond RAG (GBR)的奖励函数,衡量搜索器是否真的为生成带来了有效提升。实验表明,s3 在使用仅2.4k 训练样本的情况下,便在多个领域问答任务中超越了数据规模大百倍的强基线(如 Search-R1、DeepRetrieval)。

研究动机
RAG 的发展轨迹:从静态检索到 Agentic 策略
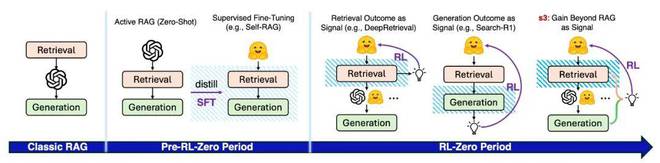
我们将 RAG 系统的发展分为三阶段:
1.Classic RAG:使用固定 query、BM25 等 retriever,生成器对结果无反馈;
2.Pre-RL-Zero Active RAG:引入多轮 query 更新,如 IRCoT、Self-RAG 等,部分通过 prompt 引导 LLM 检索新信息。Self-RAG 进一步通过蒸馏大型模型的行为,训练小模型模拟多轮搜索行为;
3.RL-Zero 阶段:强化学习开始用于驱动检索行为,代表方法如:
尽管 RL 方法在思路上更具主动性与交互性,但在实际落地中仍面临诸多挑战。
当前 RL-based Agentic RAG 落地表现不佳的原因
我们对当前 Agentic RAG 方案效果不稳定、训练难、迁移能力弱的原因,归纳为三点:
1. 优化目标偏离真实下游任务
Search-R1 等方法采用Exact Match (EM)作为主要奖励指标,即答案是否与参考答案字面一致。这一指标过于苛刻、对语义变体不敏感,在训练初期信号稀疏,容易导致模型优化“答案 token 对齐”而非搜索行为本身
例如,对于问题“美国第 44 任总统是谁?”,
这种不合理的信号会诱导模型在生成阶段做格式补偿,从而无法反映搜索策略本身是否有效
2. 检索与生成耦合,干扰搜索优化
将生成纳入训练目标(如 Search-R1),虽然可以提升整体答案准确率,但也会带来问题:
3. 现有评价标准无法准确衡量搜索贡献
EM、span match 等传统 QA 指标主要关注输出结果,与搜索质量关联有限。而 search-oriented 指标(如 Recall@K)虽可度量 retriever 性能,却无法体现这些信息是否真的被模型“用好”。这些偏差直接导致现有 RL Agentic RAG 方法在评估、训练和泛化上均存在瓶颈。
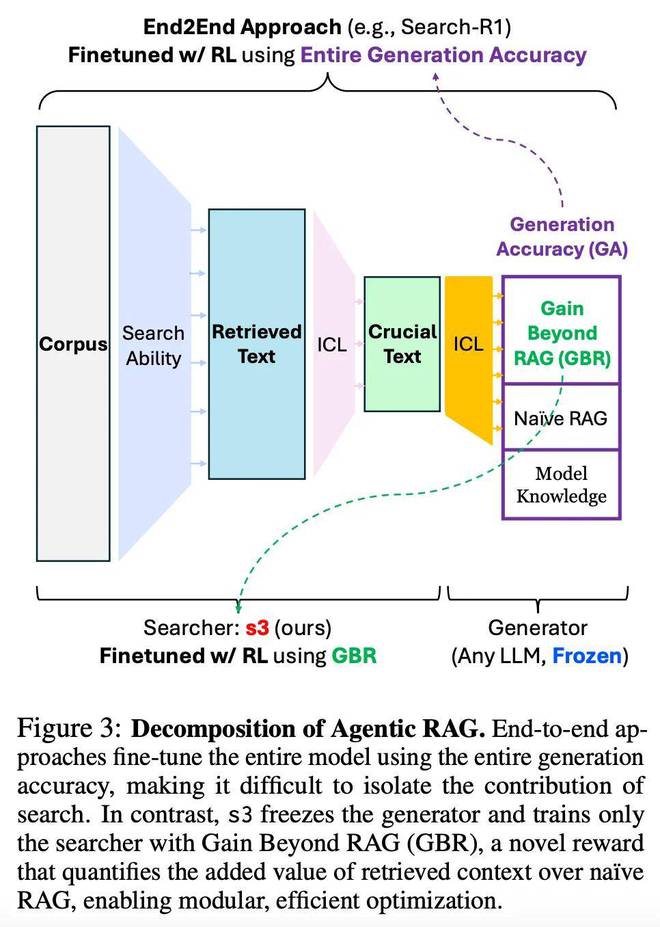
s3 - 专注搜索效果优化的 search agent RL 训练框架
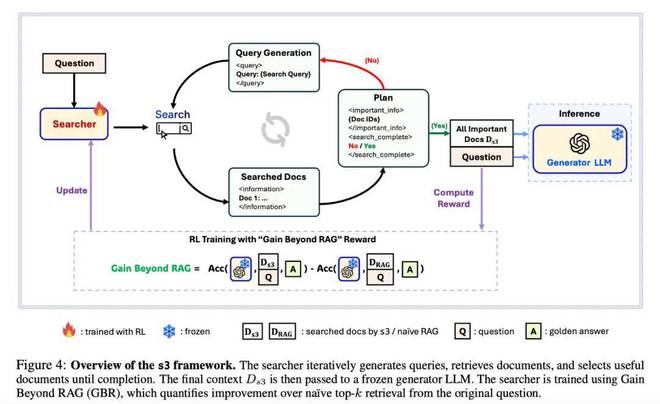
s3 的出发点很简单
如果我们真正关心的是“搜索提升了生成效果”,那就应该只训练搜索器、冻结生成器,并以生成结果提升为奖励
这便是“Gain Beyond RAG(GBR)”的定义:
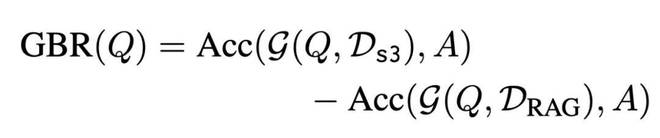
即:用 s3 搜索到的上下文喂给 Frozen Generator 之后的生成效果,相比初始的 top-k 检索结果是否更好。值得注意的是,s3 训练时始终初始化于相同的原始 query,从而能清晰对比 s3 检索对结果带来的真实“增益”。
准确率(Acc)评估标准
我们采用了更语义友好的Generation Accuracy(GenAcc)指标。它结合了两种机制:
两者只要任意一个通过,则视为正确。这一指标在人工对比中与人类判断一致率高达96.4%,相比之下,EM 仅为15.8%
训练与优化 - 仅需 2.4k 样本即可完成 ppo 训练:
我们采用 PPO 进行策略优化。为了提升训练效率:
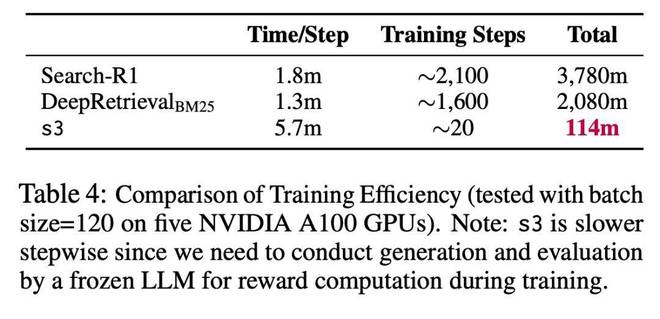
s3 训练总时间只需 114 分钟(vs Search-R1 的 3780 分钟),数据也减少约 70 倍。
实验分析
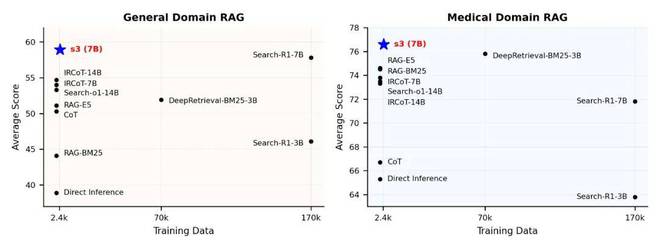
General QA w/ RAG
实验一:通用 QA 任务,s3 优于 Search-R1 和 DeepRetrieval。
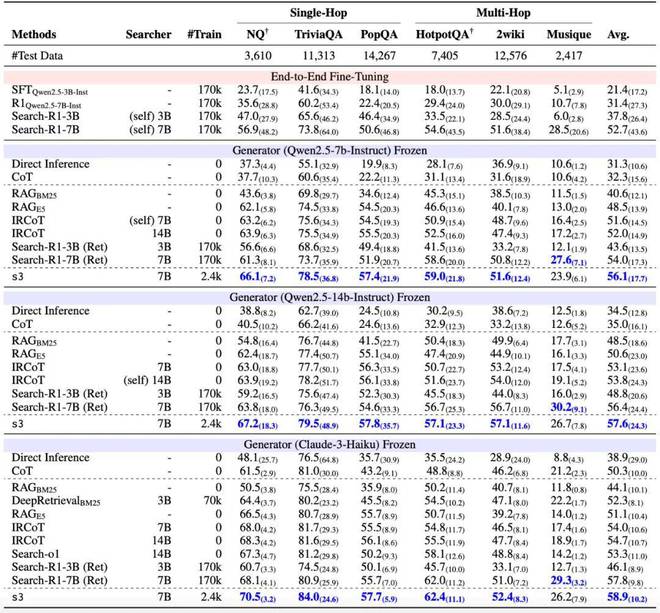
我们在六个通用数据集上评估了 Direct Inference、Naive RAG、IRCoT、DeepRetrieval、Search-o1、Search-R1 以及 s3 的性能。实验中,我们使用了不同的下游 LLM,包括 Qwen2.5-7B-Instruct,Qwen2.5-14B-Instruct 和 Claude-3-Haiku。
尽管 s3 仅使用了 2.4k 条 NQ+HotpotQA 训练数据(training source 和 Search-R1 一样),它在其中五个数据集上实现了最优表现,展现出显著的泛化能力。
Medical QA w/ RAG
实验二:医学 QA 任务,s3 展现惊人的跨领域能力
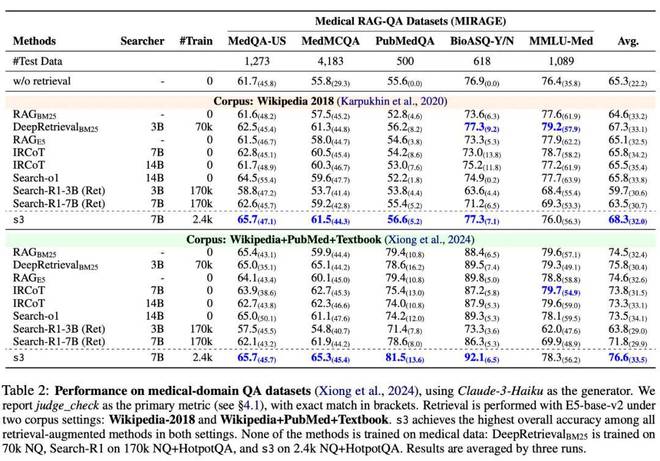
我们随后在五个医学领域的 QA 数据集上进一步评估了模型性能,测试使用了两个语料库:Wikipedia2018(与通用测试一致)和 MedCorp(ACL 2024)。结果显示,Search-R1 在其训练语料上表现良好,但在语料变更后显现出过拟合趋势;相比之下,s3 能稳定迁移至不同的数据集与语料库,凸显出其基于 searcher-only 优化策略的强泛化能力。
reward 优化曲线
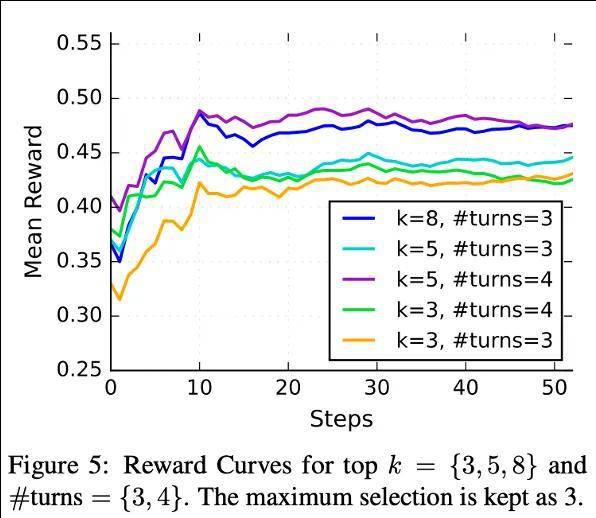
图 5 展示了我们的 reward 曲线,可以看出 s3 在接近 10 个训练步骤(batch size 为 120)内便迅速“收敛”。这一现象支持两个推断:(1)预训练语言模型本身已具备一定的搜索能力,我们只需通过合理的方式“激活”这种能力;(2)在一定范围内,适当增加每轮搜索的文档数量和最大轮次数,有助于提升最终性能。
消融实验
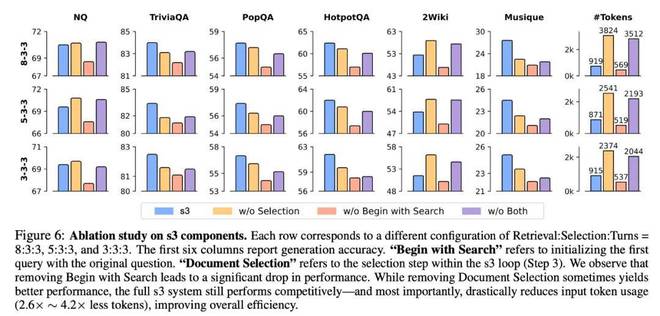
在不同配置下,移除组件对性能的影响(平均准确率)。我们使用了三组设定进行对比,结果表明 s3 的设计在准确性与效率之间达到了最优平衡。
我们进一步通过消融实验,验证了 s3 框架中两个关键设计的必要性:
总体来看,s3 设计中的“起点初始化 + 动态选择”是支撑其高效、强泛化性能的关键。即使在某些数据集上通过增加输入内容能获得短期增益,s3 原始结构在训练效率、推理速度与生成准确率上依然展现出更稳定的优势。
FAQ
Q1:为什么我们报告的 Search-R1 结果与原论文不一致?
A1:Search-R1 原文使用 Exact Match(EM)作为 reward 和评估指标,并对模型进行了针对性微调。将这种针对 EM 优化的模型,与其他 zero-shot 方法比较,略显不公平,也难以衡量搜索本身的效果。因此我们采用更语义友好的 Generation Accuracy(GenAcc),结合 span 匹配和 LLM 判断,与人类评估一致率达 96.4%。相比之下,EM 只能捕捉字面一致,反而容易误导模型优化方向。
Q2:s3 为什么不训练生成器?这样是否限制了模型性能?
A2:我们设计 s3 的核心理念是:如果我们想真正优化搜索效果,不应让生成器被训练,否则会混淆“搜索变好”与“语言模型变强”带来的增益。冻结生成器不仅提升了训练效率(节省大模型微调成本),也便于模型迁移到不同任务与生成器,真正做到“搜索能力即插即用”。