炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
新智元报道
编辑:KingHZ 桃子
【新智元导读】强化学习可以提升LLM推理吗?英伟达ProRL用超2000步训练配方给出了响亮的答案。仅15亿参数模型,媲美Deepseek-R1-7B,数学、代码等全面泛化。
强化学习Scaling来了!
刚刚,英伟达团队提出全新训练方法——ProRL,成功将RL扩展到2000步。

论文链接:https://arxiv.org/abs/2505.24864
并且,它通过跨领域训练数据,包括数学、代码、STEM、谜题、指令遵循,实现了泛化能力。
基于此方法,研究团队训出的1.5B模型,性能直接媲美Deepseek-R1-7B!
这证实了,通过长时间训练,RL确实能解锁全新推理能力。

这就是强化学习的Scaling Law:强化学习训练越长,LLM推理能力越强。
黄仁勋很高兴,毕竟在年初他就提出了所谓的“三大AI Scaling Law”。
预训练Scaling Law马上触顶,后训练Scaling Law正在发力。
而强化学习Scaling需要更多的算力,对英伟达而言就是商机和利润。
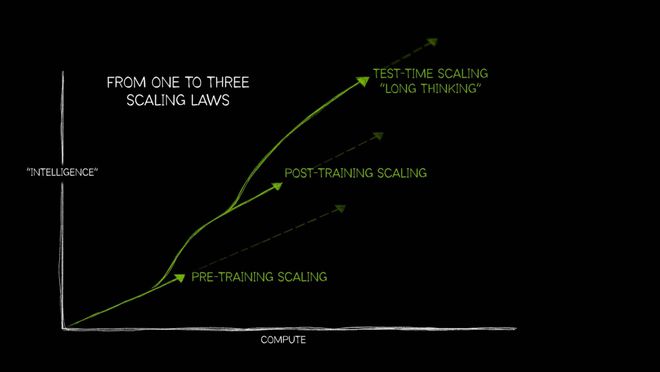
后训练拓展(Post-training scaling)利用微调(fine-tuning)、剪枝(pruning)、蒸馏(distillation)和强化学习等技术,优化预训练模型,从而提升模型的效率和任务适应性。
这次研究的主要发现:
强化学习Scaling
只要2000步
近来,许多人质疑RL是否真正提升模型的推理能力。甚至,有研究声称RL无法为基础模型带来新的推理技能。
这些观点认为,RL的效果受限,主要源自以下问题:
1. 训练领域过于狭窄:比如过度聚焦于数学等特定领域,导致模型难以泛化。
2. 训练时间不足:许多强化学习训练仅在数百步后就停止,远未挖掘出真正的潜力。
这些限制,让人们误以为RL无法突破基础模型的推理边界。但事实证明,并非如此。
英伟达这项突破性研究,带来了振奋人心的答案:
只要将RL训练足够久,AI推理能力就能实现质的飞跃!
ProRL便成为了突破2000步的强化学习新配方,通过KL惩罚和定期参考策略重置,解决了长期以来存在的两大难题——熵崩溃和训练不稳定性。

论文中利用ProRL,作者打造了仅15亿参数推理模型——Nemotron-Research-Reasoning-Qwen-1.5B。
ProRL的核心突破在于,它让模型能够在新颖任务中,发现基础模型完全无法企及的解决方案。
结果显示,在数学、代码、STEM、谜题和指令遵循方面,1.5B模型实现了超强泛化能力,完全不输Deepseek-R1-7B。
另外,在许多测试中,基础模型即使经过大量采样也完全失败,而ProRL训练的模型却能实现100%通过率。
尤其是,在高难度任务和域外任务上,ProRL训练的模型表现出色。这表明了推理能力真正Scaling,并内化了超越训练数据的抽象推理模式。
以Codeforce任务为例,RL后模型的解法发布更加广泛,展现出更高的多样性。
而对于全新的family_relationships任务,模型从几乎全0通过率,跃升至完美准确率,成功发现了全新的解法路径。
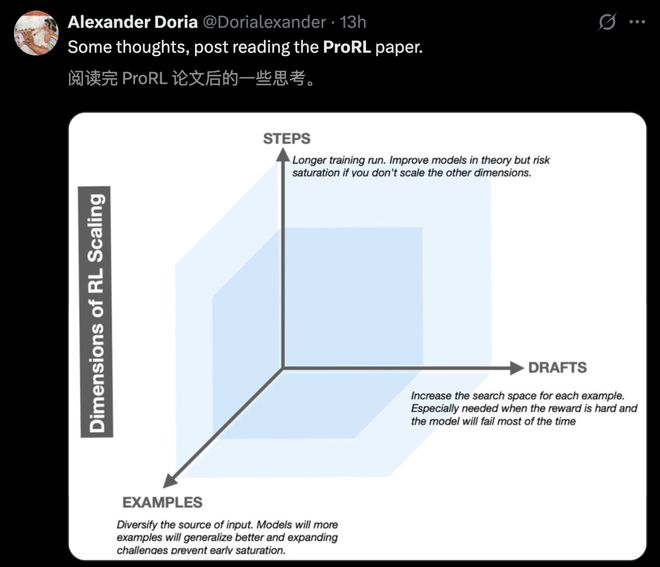
接下来,一起看看ProRL方法如何实现的?为何2000步能带来如此显著变化?
关键在于策略优化的底层机制:GRPO与KL正则的协同进化,为强化学习注入了稳定与多样性。
改造GRPO
“三板斧”解决熵坍缩
在策略优化训练时间较长时,主要难题是熵坍缩。
熵坍缩指的是模型输出的概率分布在训练早期就变得非常集中,导致输出熵迅速下降。
当熵坍缩发生时,策略会过早地固定在少量输出上,严重限制了探索性。
对于GRPO(Group Relative Policy Optimization,组相对策略优化)这样的RL算法来说,多样化的输出样本是估算相对优势的基础,因此探索受限会使学习信号偏差,训练难以继续有效推进。
提高采样的温度,虽然可以延缓熵坍缩的发生,但随着训练的进行,熵仍会持续下降。
这次,研究团队彻底改造了GRPO方法。
GRPO的优化目标如下:
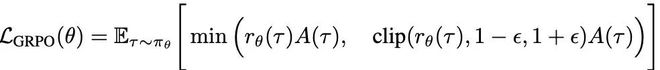
τ是当前策略πθ所采样的响应,rθ(τ)表示当前策略与旧策略的概率比。
GRPO中的优势函数(advantage)不依赖于PPO的价值网络(critic),而是用同一组样本{Ri}的得分来估算基线:
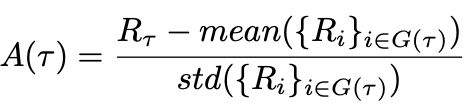
DAPO的启发
开源的DAPO算法中的几个关键组件,启发了研究团队解决熵坍缩问题。

论文链接:https://arxiv.org/abs/2503.14476
首先,DAPO引入了“解耦剪辑”机制,在PPO的目标函数中将上下剪辑边界视为两个独立的超参数:
通过将ϵ_high设置为较高值,算法鼓励“向上剪辑”(clip-higher),即提升原本概率较低的token的生成概率,从而扩大模型的探索范围。
他们发现,这种调整有助于保持输出熵,并减少过早的模式坍缩现象。
此外,DAPO还采用了“动态采样”策略,即过滤掉那些模型总是成功(准确率为1)或总是失败(准确率为0)的提示语。这些示例无法提供有效的学习信号。
相反,训练更集中在“中等难度”的样本上,有助于保持多样化的学习信号,推动模型持续进步。
显式正则化:更强、更稳定
尽管DAPO机制和调整采样温度可以在一定程度上减缓熵坍缩,但引入显式正则化方法KL散度惩罚项,能够提供更强、更稳定的解决方案。
具体而言,研究团队在当前策略πθ和参考策略πref之间加入KL散度惩罚:
这个惩罚项不仅有助于维持策略的熵,还起到了正则化的作用,防止当前策略过度偏离一个稳定的参考策略,从而提升训练稳定性,避免模型过拟合于某些虚假的奖励信号。
此外,随着训练推进,KL惩罚项可能在损失函数中占比过高,从而抑制策略更新的步幅。
为了解决这个问题,研究团队引入了一种简单但有效的方法:参考策略重置(Reference Policy Reset)。
具体做法是:定期将参考策略πref硬性重置为当前策略πθ的最近快照,并重新初始化优化器的状态。
这种机制既能让模型继续改进,又能保留KL正则化带来的稳定性。在整个训练过程中反复应用这种重置策略,以防模型过早收敛,同时鼓励更长时间的有效训练。
全面泛化
1.5B刷新SOTA
借助稳定的奖励计算机制、改进版GRPO算法以及延长的训练过程,在不同任务上,新模型Nemotron-Research-Reasoning-Qwen-1.5B都展现出强大的泛化能力。
项目链接:https://huggingface.co/nvidia/Nemotron-Research-Reasoning-Qwen-1.5B
在以下领域,新模型均显著优于基础模型DeepSeek-R1-Distill-Qwen-1.5B:
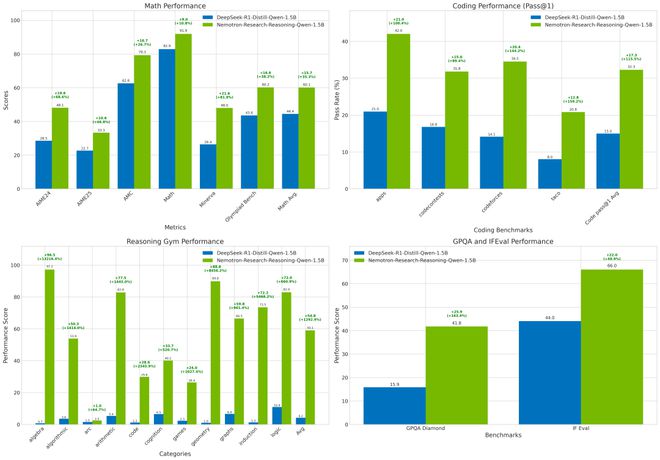
此外,在数学(+4.6%)和编程(+6.5%)两个领域,新模型也超越了专门针对特定任务训练的领域专用基线模型,充分体现了通用型强化学习(Prolonged RL)训练方法的有效性。
实验设置
为了验证假设,研究团队构建了多样化且可验证的训练数据集,共包含约13.6万个样本,涵盖五个任务领域:数学(math)、编程(code)、理工类(STEM)、逻辑谜题(logical puzzles)和指令遵循(instruction following)。
每种任务类型都配有清晰的奖励信号(可为二值或连续值),从而在训练过程中提供可靠反馈。

表4:这次研究中使用的训练数据概览
为了实现有效的长周期强化学习训练,他们在融合的验证集(从评估基准集中抽样)实时监控训练进展。
当验证集表现停滞或下降时,他们会对参考模型和优化器进行硬性重置,以恢复训练稳定性,并允许策略进一步偏离初始基础模型。
在训练的大部分时间里,响应长度被限制在8000个token内,保证生成结果简洁稳定。
在训练的最后阶段(约200个步骤),上下文窗口token总数扩大到16000。
研究团队观察到模型能够迅速适应,并取得了可观的性能提升。
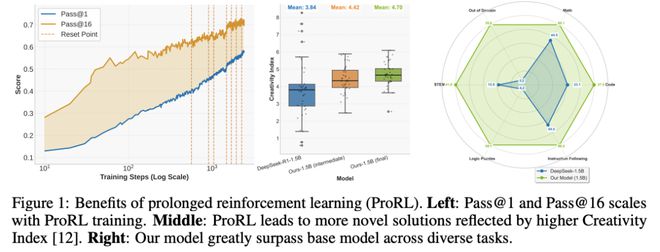
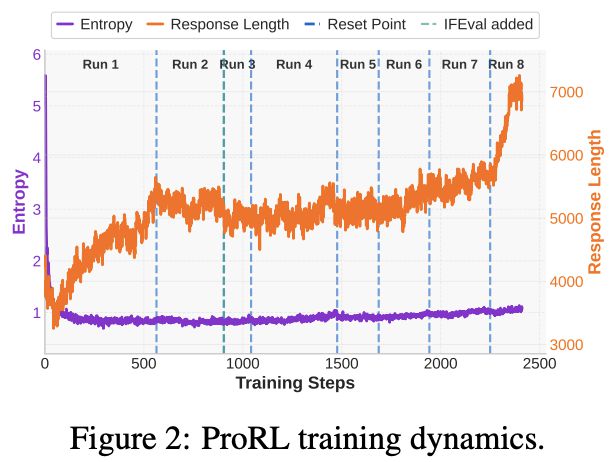
图2展示了在多阶段扩展强化学习过程中,训练动态的关键统计数据。
DAPO的多项增强策略,结合KL散度损失,有效防止了模型出现熵坍缩现象。
尽管观察到平均响应长度与验证集得分之间存在一定的正相关关系,但这一因素并非决定性,因为在某些训练阶段,即使响应长度没有明显增加,性能依然有所提升。
与此同时,验证性能(通过pass@1和pass@16指标衡量)持续改善,并随着训练计算量的增加而稳步提升。
 下图8展示了整个训练过程中KL散度的变化情况。
下图8展示了整个训练过程中KL散度的变化情况。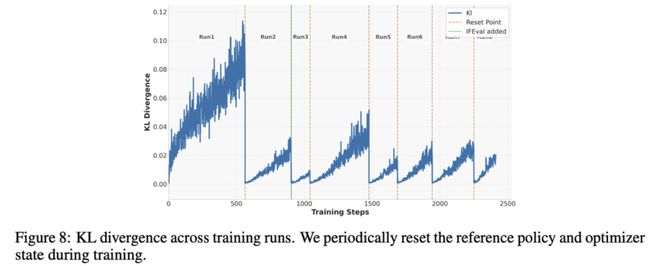
实验利用开源项目reasoning-gym进行。
项目链接:https://github.com/open-thought/reasoning-gym
评测结果分析
在多个领域对DeepSeek-R1-Distill-Qwen-1.5B基础模型与Nemotron-Research-Reasoning-Qwen-1.5B,研究团队进行了全面对比。
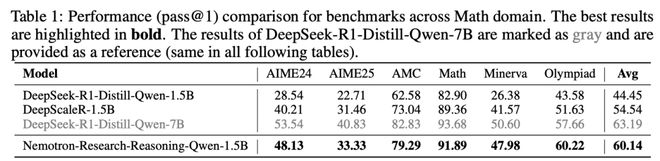
新模型在所有数学推理基准测试中均稳定超越基础模型,平均提升15.7%(见表1)。
在复杂数学推导任务中展现出更强的逻辑连贯性。
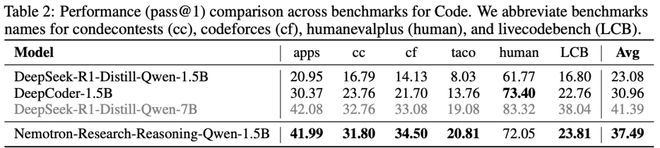
在竞技编程任务(pass@1准确率)中提升14.4%,尤其擅长处理算法优化与边界条件判断(见表2)。
在STEM推理与指令跟随测试中,GPQA Diamond基准成绩提升25.9%;IFEval指令理解任务提升22.0%(见表3左侧)。
在逻辑谜题(Reasoning Gym)测试中,在基础模型普遍受困于格式解析与复杂子任务的场景下,奖励分数提升54.8%。
新模型展现出优异的非结构化问题分解能力(见表3左侧)。
即便与参数量更大的DeepSeek-R1-Distill-Qwen-7B相比,1.5B新模型在多数领域表现相当甚至更优,验证了ProRL方法的高效性。
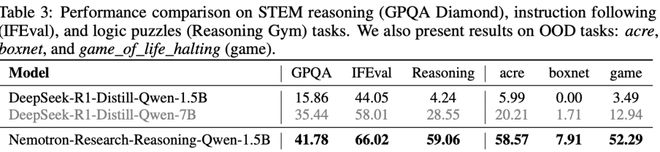
关键发现:强化学习训练不仅全面提升模型在各专业领域的表现,更在基础模型原本失效的任务上实现突破性进展,证实了该方法对模型本质推理能力的拓展作用。
分布外任务(OOD)泛化能力
表3(右侧)展示了新模型在Reasoning Gym中多个分布外(OOD)任务上的表现。
模型在三项OOD任务中均取得显著提升,展现出强大的泛化能力。这表明新的训练方法有助于模型应对未知挑战。
与领域专用模型的对比
研究团队对比了Nemotron-Research-Reasoning-Qwen-1.5B与两个专门面向某一领域的基准模型:DeepScaleR-1.5B(数学推理)、DeepCoder-1.5B(编程任务)。
下表2显示,基于ProRL训练的模型具备强泛化能力,在:
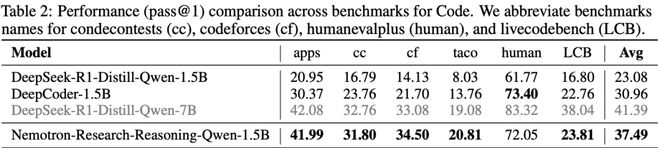
此外,ProRL使模型能在较短响应长度内完成更深入的推理与优化,相比之下,现有方法往往过早增加响应长度,导致“过度思考”(overthinking)并生成冗长啰嗦的推理内容。
实验分析
这次的主要分析结论如下:
(1)强化学习在扩展模型推理边界(以pass@128衡量)方面的效果,与 基础模型的初始能力 密切相关。
(2)强化学习确实能够显著扩展模型的推理能力,尤其是在那些超出基础模型原有能力范围的高难度任务上。
(3)强化学确实可以扩展LLM推理边界,能够推广到训练中未见的分布外任务。
(4)新方法ProRL不仅提高了平均pass@1,还足以弥补训练中可能带来的输出方差增加,从而整体提升pass@k上限,推动推理能力的实质跃升。
起点越弱,收益越大
这次研究的一个关键发现是:强化学习在扩展模型推理边界(以pass@128衡量)方面的效果,与基础模型的初始能力密切相关。
如图3所示,研究团队观察到基础模型的推理边界越弱,其在经过RL训练后的推理提升越显著,二者呈现出明显的负相关关系。
具体来说:
为进一步验证这种现象,他们引入了“创造力指数”(creativity index),衡量基础模型在每个任务中的响应与最大规模开源预训练语料库DOLMA之间的重合度。
结果表明,那些在RL训练后几乎没有提升的任务,其创造力指数普遍较低——
尤其是一些数学和编程任务(图中用圆圈标出)。
这表明基础模型在预训练期间已经接触过大量相似内容,因而对这些任务“熟悉”,也更难通过RL获得进一步提升。
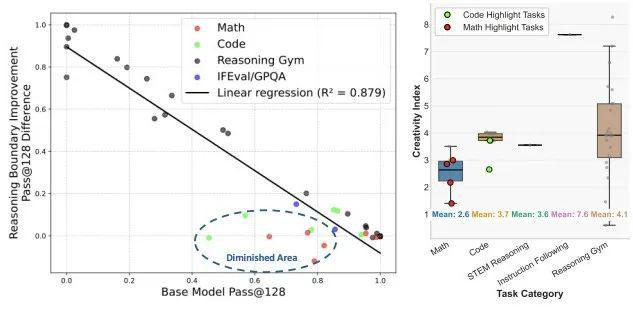
图3:左:在基础模型最初难以应对的任务上,ProRL最能有效地扩展模型的推理边界。右:圆圈中标出的那些经过强化学习(RL)后收益最小的任务通常具有较低的创造力指数
解构ProRL的推理边界
他们逐一分析了各个评估基准任务的训练表现,并根据训练过程中pass@k的变化趋势,把它们分类。
结果表明,强化学习确实能够显著扩展模型的推理能力,尤其是在那些超出基础模型原有能力范围的高难度任务上。
具体来说:
最显著的例子是代码生成任务,在这一领域,ProRL能够带来持续性的性能提升。这表明,延长训练时间使模型有机会深入探索,并逐步内化更复杂的推理模式。
整体来看,这些结果说明:在合适的训练条件下,ProRL不仅能优化模型当前的表现,还能突破基础模型的推理上限,推动模型在推理能力上的持续进步。
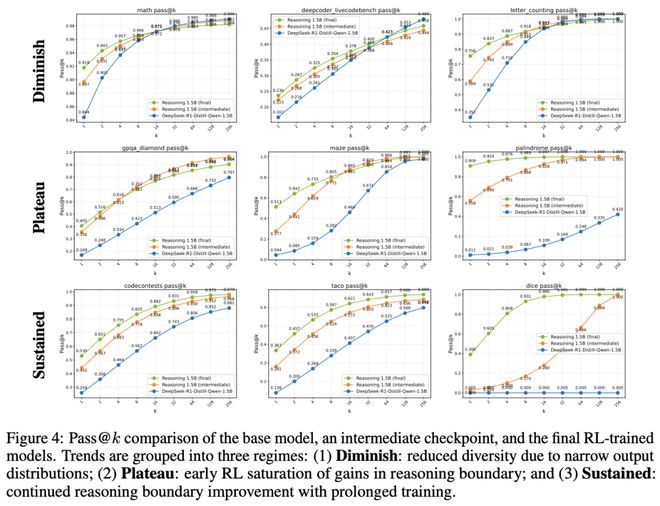
在评估过程中发现,ProRL对不同任务的推理边界影响存在显著差异,主要可分为以下三类情况:
1.推理边界退化(Diminished Reasoning Boundary)
在部分任务中(尤其是数学领域),Nemotron-Research-Reasoning-Qwen-1.5B的推理能力相比基础模型有所下降或保持不变,这一现象也与先前研究中的观察结果一致。
2.RL收益早期饱和(Gains Plateau with RL)
对于这一类任务,RL训练确实提升了pass@1和pass@128,说明推理能力有所增强。但这种提升大多出现在训练初期。
比较中间训练检查点与最终模型可以看出,ProRL在训练后期几乎不再带来额外收益,表明模型对这类任务的学习潜力已很快达到饱和。
3.持续收益(Sustained Gains from ProRL)
与上述情况相反,部分任务——尤其是更复杂的任务,如代码生成——在经过长时间ProRL训练后,推理能力持续提升。
这些任务通常需要模型在训练过程中对多样化问题进行充分探索,才能有效泛化到测试集。在此类任务上,ProRL显著拓展了模型的推理边界,展现出延长训练在复杂任务上的巨大潜力。
ProRL提升分布外推理能力
ProRL如何增强模型在分布外(Out-of-Distribution, OOD)任务上的泛化能力?
延长强化学习训练是否能够显著扩展模型的推理边界,尤其是在面对结构上新颖或语义上具有挑战性、且在初始训练阶段未曾接触过的任务时?
这次研究试图单独评估长期RL更新的作用,观察其是否能促使模型学习到更抽象、通用的推理策略,从而在陌生任务中也能表现出色。这是验证ProRL是否具备“超出经验学习”能力的重要指标。
分布外(OOD)任务评估
在Reasoning Gym中选取了boxnet任务进行评估,该任务在训练阶段从未出现过,用于测试模型在完全陌生任务上的泛化能力。
如图5所示:
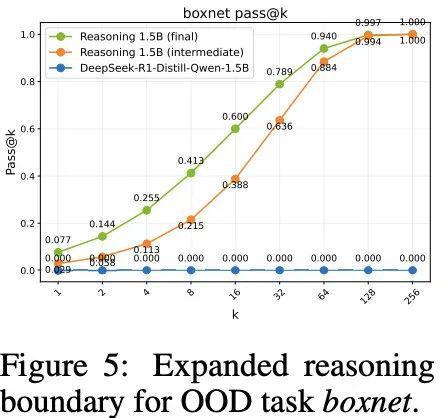
进一步对比中期RL检查点和最终延长训练后的模型,研究者发现随着训练持续,模型在boxnet上的表现稳步增强,且在所有pass@k值上均有提升。
这一结果强有力地支持了以下结论:ProRL不仅提升模型在已知任务上的表现,更促使模型内化抽象的推理模式,具备超越具体训练数据与任务复杂度的泛化能力。
难度提升下的泛化能力评估
研究者进一步在graph_color任务中评估模型在不同任务难度下的表现。
具体做法是通过生成不同节点数的图结构问题来调节任务难度:
图6展示了不同模型在各个图规模下的表现(pass@1为实线,pass@128为虚线)。结果显示:
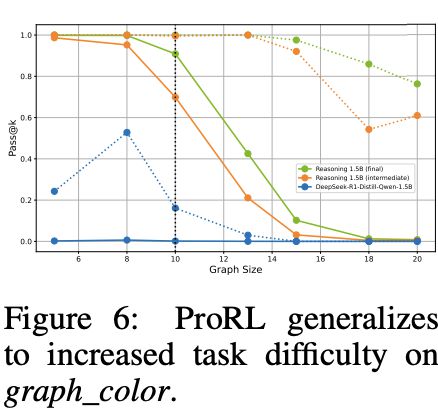
这一发现表明:
训练过程中pass@1分布如何演化?
已有研究表明:
 与已有研究中观察到的“训练过程中pass@k随时间下降”的现象不同,这次的实验结果(图1)显示:
与已有研究中观察到的“训练过程中pass@k随时间下降”的现象不同,这次的实验结果(图1)显示:ProRL方法在多个任务上带来了显著的性能提升。
图7(a)和图7(b)展示了在代码任务和逻辑谜题任务中的pass@1分布变化:
具体案例:
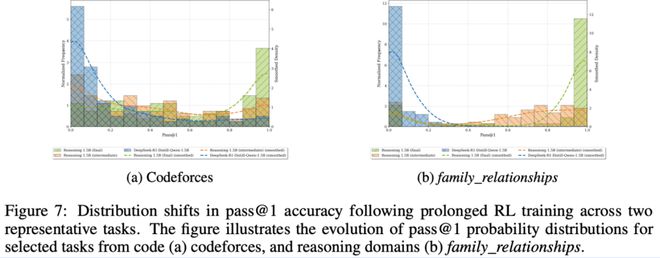
这些明显的分布变化由延长RL训练驱动,说明:
ProRL不仅提高了平均pass@1,还足以弥补训练中可能带来的输出方差增加,从而整体提升pass@k上限,推动推理能力的实质跃升。
作者简介
Mingjie Liu,现任英伟达研究科学家,专注于电子设计自动化(EDA)领域的前沿研究。
他的研究领域主要涵盖:人工智能与机器学习、模拟与混合信号集成电路。
他于2022年获得德克萨斯大学奥斯汀分校UT-Austin电子与计算机工程博士学位。
在2018年,他获得密歇根大学电子与计算机工程硕士学位。
2012年-2016年,他就读于北京大学微电子专业。
参考资料:
https://x.com/_AndrewZhao/status/1929376147957076447