炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
每一年的年中或年末,一些科学家、企业家或者行业 KOL 会针对他们活跃的领域做一份总结与预测。在“AI 一天,人间三年”的大模型时代,这样的回顾与前瞻,极具参考价值。
日前,机器学习研究员、艾伦人工智能研究所后训练负责人 Nathan Lambert 便在一篇个人博客中就“o3 的搜索功能”、“agent 与模型进展”,以及“scaling 增长放缓”等主题进行了深入探讨。
他写道,“随着新模型的发布速度放缓,是时候回顾一下今年我们取得了哪些成果,以及未来的发展方向了。”

图|Nathan Lambert
在他看来,o3 展现出的独特搜索能力,证明了 OpenAI 在提升推理模型中搜索和其他工具使用的可靠性方面取得了技术突破。“我听过的对它在寻找特定信息时那种不懈追求的最佳描述,就像一只‘嗅到目标的训练有素的猎犬’。”
他还表示,未来更多的人工智能模型将类似于 Anthropic 的 Claude 4,尽管其基准测试提升很小,但在实际应用中的进步却很大。“对模型进行微小调整即可让像 Claude Code 这样的 agent 显得更加可靠。”
此外,在谈及预训练 scaling law“基本停滞”问题时,他表示“新的规模层级扩展可能每隔几年才会实现,甚至完全无法实现,”这取决于人工智能的商业化是否如预期般顺利。
尽管如此,他并不认为“预训练作为一门科学已不再重要”。Gemini 2.5 就是一个反例。
学术头条在不改变原文大意的情况下,对整体内容做了精编,如下:
https://www.interconnects.ai/p/summertime-outlook-o3s-novelty-coming
夏季一直是科技行业相对平静的时期。OpenAI 似乎完全符合这一趋势,其开源模型“需要更多时间”进行优化,而 GPT-5 的发布也似乎总是被推迟。这些显然将是重大新闻,但我不确定我们是否能在 8 月之前看到它们。
我将利用这段人工智能发布潮的短暂间歇,回顾我们走过的路,展望未来的方向。以下是你需要了解的内容。
o3:超越scaling的技术突破
关于 OpenAI 的 o3 模型,主流观点认为,他们“为强化学习训练扩展了计算资源”,这导致了一些奇怪的、全新的过度优化问题。这种说法是正确的,而发布会的直播内容仍然代表了一种突破——即通过可验证奖励强化学习(RLVR)来扩大数据和训练基础设施的规模。
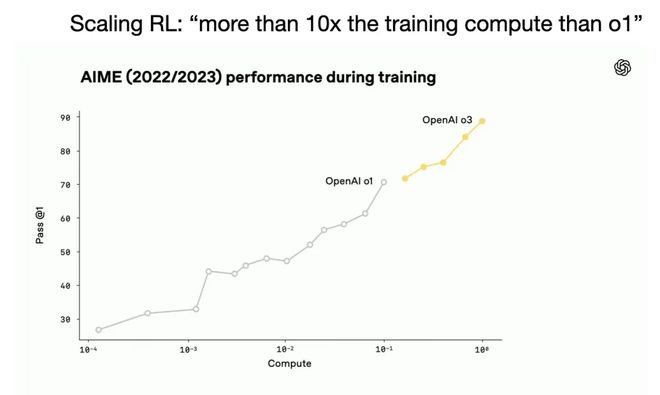
关于 o3,人们对它带来的不同搜索体验讨论不多。对于一个普通的查询,o3 可以查看数十个网站。我听过的对它在寻找特定信息时那种不懈追求的最佳描述,就像一只“嗅到目标的训练有素的猎犬”。o3 给人这样一种感觉,它可以以一种与现有任何模型完全不同的方式找到信息。
值得注意的是,距离其 2025 年 4 月发布已过去数月,而其他领先实验室尚未推出任何类似的模型。在一个在实验室之间(尤其是 OpenAI 和 Google)发布内容似乎完全同步的背景下,o3 中这种持续的搜索能力仍让我印象深刻。
核心问题是,何时会有另一家实验室发布一款同等质量的模型?如果这一趋势持续到夏季结束,这将证实 OpenAI 在提升推理模型中搜索和其他工具使用的可靠性方面取得了技术突破。
作为对比,让我们思考一个开放和学术社区面临的基本问题,即如何构建一个受 o3 启发的模型(实际搜索能力更接近于 GPT-4o 或 Claude 4):
1.找到能够激励模型进行搜索的 RL 数据至关重要。在 RL 实验中,让模型尝试在系统提示中进行搜索很容易,但随着训练的进行,如果工具不够实用,模型应该迅速学会停止使用它。在这一方面,OpenAI 非常擅长,尤其是结合 Deep Research 的 RL 训练经验(我了解到,其训练基于 o3)。另外,一篇展示 DeepSeek R1 风格的扩展 RL 训练且在大数据子集上保持一致工具使用率的研究论文,将会深深打动我。
2.底层搜索索引也非常重要。OpenAI 的模型基于 Bing 后端运行。Anthropic 使用 Brave 的 API,但性能表现不佳(存在大量 SEO 垃圾信息)。使用这些 API 构建学术基线会带来一些额外计算成本。一旦有了可靠的开放基线,我们就可以开展一些有趣的科学研究,例如探讨哪个模型能够最好地泛化到未见过的数据集——这是在本地敏感数据(如医疗或银行业)上部署模型时的一项关键特性。
如果你尚未使用 o3 进行搜索,真的应该尝试一下。
Agent 性能将大幅提升
Claude Code(加之 Claude 4)的产品市场契合度堪称卓越。这是产品的完美组合——运行稳定且高效,用户体验(UX)与领域高度契合...... 使用起来简直是一种享受。
在这种背景下,我一直在寻找更多方式来撰写相关内容。一个问题是,我并非 Claude Code 以及其他编程助手(如 Codex 和 Jules)的核心用户群体。我并非经常在复杂的代码库中进行开发——我更像是组织内的研究经理和问题解决者,而非始终在单一仓库中持续开发的开发者——因此,我没有关于如何充分利用 Claude Code 的实用指南,也没有与之建立深层连接,以帮助你“感受 AGI”的经验。
我所了解的是模型和系统,而前沿模型的一些基本事实使得这些 agent 的能力发展轨迹显得相当乐观。
基于 LLM 的 agent 的新颖之处在于,它们涉及多次模型调用,有时甚至需要多个模型和多种 prompt 配置。此前,人们在聊天窗口中使用的模型都是为完成线性任务并将其结果返回给用户而设计的,而无需管理复杂的记忆或环境。
为模型添加真实环境使得模型需要完成更多任务,且任务范围往往更为广泛。在构建这些 agentic 系统时,存在两种类型的瓶颈:
(1)模型无法解决我们希望 agent 执行的任何任务,以及(2)模型在部署任务的某些细微环节上出现故障。
对于已经取得初步进展的 agent,如 Claude Code 和 Deep Research,表现出的问题大多属于第二类。实验室的解决方式是,在实际应用场景中找到反复出现的异常故障。这可能表现为某些长尾日常任务的可靠性仅为 50%。在这种情况下,实验室通常可以轻松生成新的数据,将其纳入模型续训练中,从而将该子任务的可靠性提升至近 99%。由于实验室当前主要通过后训练而非大规模预训练来实现性能提升,因此这些改进被整合所需的时间远短于近几年。
关键在于这一切如何一起发挥作用。许多复杂任务可能因某些小故障而受阻。在这种情况下,对模型进行微小调整即可让像 Claude Code 这样的 agent 显得更加可靠,尽管模型峰值性能并未发生显著变化。Deep Research 的情况也是如此。
因此,我预计我们当前使用的这些 agent 将实现随机且大幅的性能提升。
我目前不确定的是,新的 agent 平台何时会出现。一个影响因素是产品问题,另一个影响因素则是性能瓶颈问题。看似已经实现产品市场契合(PMF)的新 agent 平台,其发展路径可能会有些随机,但已经实现 PMF 的平台则可以像我们习惯的那样,通过前沿模型实现显著提升。
这是该行业的一条新路径,将采用与以往不同的信息传递方式。未来更多的人工智能模型将类似于 Anthropic 的 Claude 4,尽管其基准测试提升很小,但在实际应用中的进步却很大。这一趋势将带来政策、评估和透明度方面的影响。要判断技术进步是否持续,需要更加细微的分析,尤其是当批评者抓住评估指标停滞不前的机会、声称人工智能已不再有效时。
与 o3 类似,即使你不经常编程,也应该尝试使用 Claude Code。它能够快速创建有趣的演示和独立网站。与 Codex 等完全自主的 agent 相比,它目前在易用性方面有着很大优势。
模型 scaling 速度变缓
2025 年,由领先的人工智能实验室发布的模型,在总参数规模上大多不再继续增长。以 Claude 4 为例,其 API 定价与 Claude 3.5 保持一致。OpenAI 仅发布了 GPT-4.5 的研究预览版。Gemini 尚未发布其 Ultra 版本。这些实验室内部还有更多未公开的模型,其规模更大。
需要注意的是,其中许多模型可能在规模上略有减小,例如 Claude 4 Sonnet 可能比 Claude 3.5 Sonnet 稍小,这是由于预训练阶段的效率提升。这种边际技术进步在价格和推理速度上具有重大影响,尤其从长期来看,但这并非我论点的核心。
重点在于,GPT-5 的能力提升主要通过推理时扩展实现,而非单纯依赖“更大的单一模型”。多年来,我们一直被告知“拥有最大训练集群的实验室将赢得竞赛,因为它们在扩展方面具备优势”。这就是马斯克打造 xAI 巨型集群的原因。如今,最大集群仅在整体研发进度上具备优势。
在用户需求层面,扩展已基本不具有吸引力。未来,当实验室遇到用户需要解决的极具挑战性的问题时,他们可能会重新关注这一领域。尽管 GPT-4.5 的训练计算成本约为 GPT-4 的 100 倍,其在常规用户指标上的提升仅略微显著。
我们看到的是,针对用户喜爱模型规模进行的大规模效率提升。行业内也已形成了几项标准:
1.微型模型(Tiny models),如 Gemini Flash Lite 或 GPT 4.1 Nano;
2.小型模型(Small models),如 Gemini Flash 和 Claude Haiku;
3.标准模型(Standard models),如 GPT-4o 和 Gemini Pro,
4.大型模型(Big models),如 Claude Opus 和 Gemini Ultra。
这些模型具有相对可预测的价格点、延迟和能力水平。随着行业成熟,此类标准至关重要!
随着时间推移,效率的提升将催生新的标准。我们将看到 Gemini Ultra 和 GPT-4.5(GPT-5)等模型的广泛普及,但后续发展方向尚不明确。目前,新的规模层级扩展可能“每隔几年”才会实现,甚至完全无法实现,这取决于人工智能的商业化是否如预期般顺利。
Scaling,作为产品差异化的一个因素,在 2024 年已不再有效。然而,这并不意味着预训练作为一门科学已不再重要。最近的 Gemini 2.5 报告就明确地指出:
整理:学术君