迈向通用人工智能(AGI)的核心目标之一就是打造能在开放世界中自主探索并持续交互的智能体。随着大语言模型(LLMs)和视觉语言模型(VLMs)的飞速发展,智能体已展现出令人瞩目的跨领域任务泛化能力。
而在我们触手可及的开放世界环境中,图形用户界面(GUI)无疑是人机交互最普遍的舞台。想象一下 --- 你的 AI 不仅能看懂屏幕,还能像人一样主动探索界面、学习操作,并在新应用里灵活应对,这不再是幻想!
近期,吉林大学人工智能学院发布了一项基于强化学习训练的 VLM 智能体最新研究《ScreenExplorer: Training a Vision-Language Model for Diverse Exploration in Open GUI World》。它让视觉语言模型(VLM)真正学会了“自我探索 GUI 环境”。

论文地址:https://arxiv.org/abs/2505.19095
项目地址:https://github.com/niuzaisheng/ScreenExplorer
该工作带来三大核心突破:
在真实的 Desktop GUI 环境中进行 VLM 模型的在线训练;
针对开放 GUI 环境反馈稀疏问题,创新性地引入“好奇心机制”,利用世界模型预测环境状态转移,估算环境状态的新颖度,从而有效激励智能体主动探索多样化的界面状态,告别“原地打转”;
此外,受 DeepSeek-R1 启发,构建了“经验流蒸馏”训练范式,每一代智能体的探索经验都会被自动提炼,用于微调下一代智能体。这不仅大幅提升探索效率、减少对人工标注数据的依赖,更让 ScreenExplorer 的能力实现了持续自主进化,打造真正“学无止境”的智能体!论文同时开源了训练代码等。
方法
实时交互的在线强化学习框架
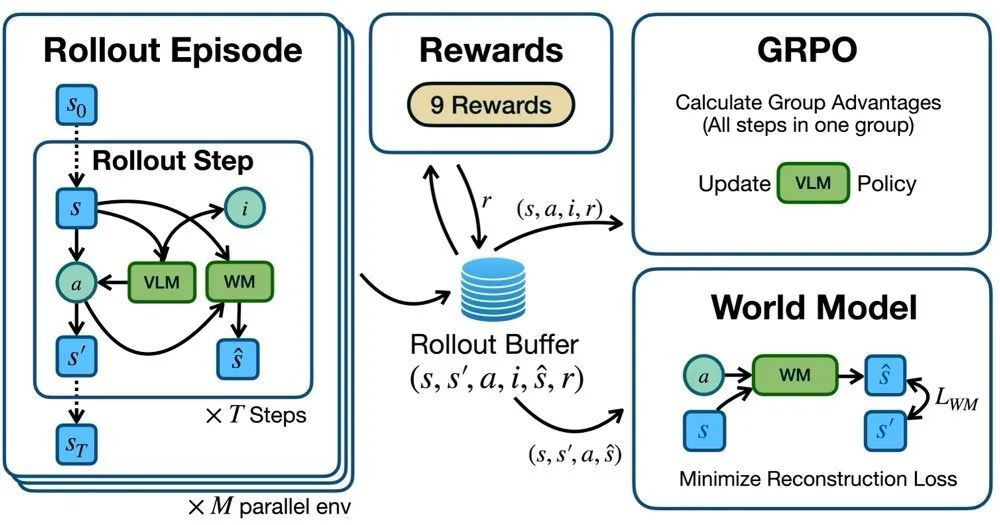
文章首先构建了一个能够与 GUI 虚拟机实时交互的在线强化学习环境,VLM 智能体可以通过输出鼠标和键盘动作函数调用与真实运行的 GUI 进行交互。强化学习环境通过提示词要求 VLM 智能体以 CoT 形式输出,包含“意图”与“动作”两部分。最后,强化学习环境解析函数调用形式的动作并在真实的操作系统中执行动作。在采样过程中,可以并行多个虚拟机环境进行采样,每个环境采样多步,所有操作步都存储在 Rollout Buffer 中。
启发式 + 世界模型驱动的奖励体系
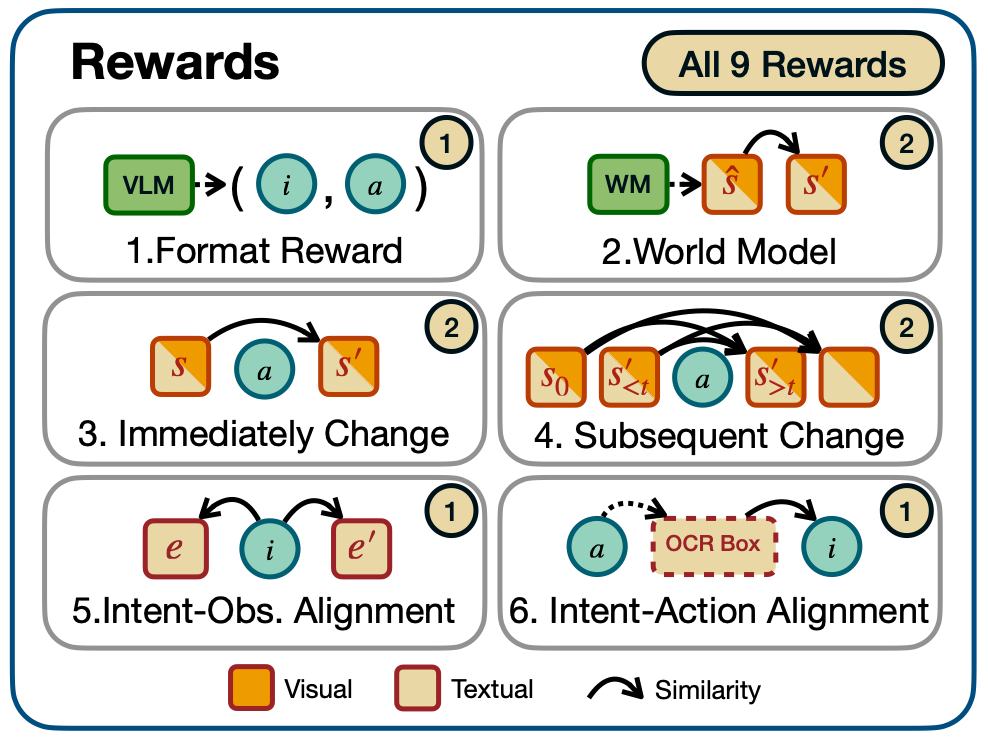
文中构建了启发式 + 世界模型驱动的探索奖励,启发式探索奖励鼓励轨迹内画面之间差异度增大。世界模型可以导出每一个动作的好奇心奖励,鼓励模型探索到越来越多的未见场景,此外还有格式奖励和意图对齐奖励。综合以上奖励,为每一步动作赋予即时奖励,进而鼓励模型与环境开展有效交互的同时不断探索新环境状态。
计算 GRPO 的组优势函数计算
在获得每一步输出的奖励后,文中采用与 Deepseek-R1 相同的 GRPO 算法对 VLM 进行强化学习训练。作者将同一个 Rollout Buffer 中所有动作视为一个组,首先根据 GRPO 的优势函数计算每一步动作的优势值:
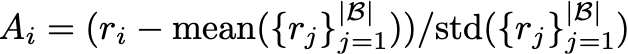
再使用 GRPO 损失函数更新 VLM 参数:
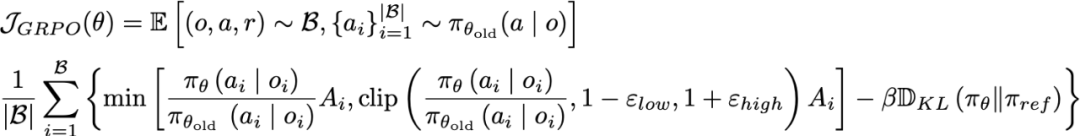
由此可实现每个回合多个并行环境同步推理、执行、记录,再用当批数据实时更新策略,实现“边操作边学”的在线强化学习。
实验结果
模型探索能力表现
文中的实验使用了 Qwen2.5-VL-3B 和 Qwen2.5-VL-7B 作为基础模型,如果不经训练,直接让 3B 的小模型与环境进行交互,模型只会在屏幕上“乱按一通”,未能成功打开任何一个软件:
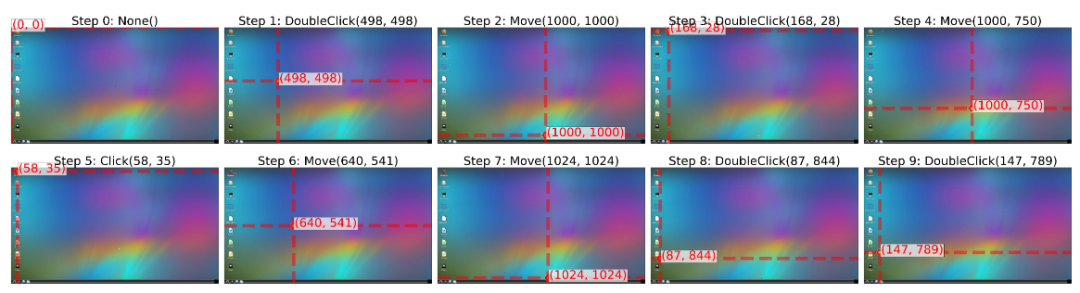
但是稍加训练,模型就能成功打开一些桌面上的软件:
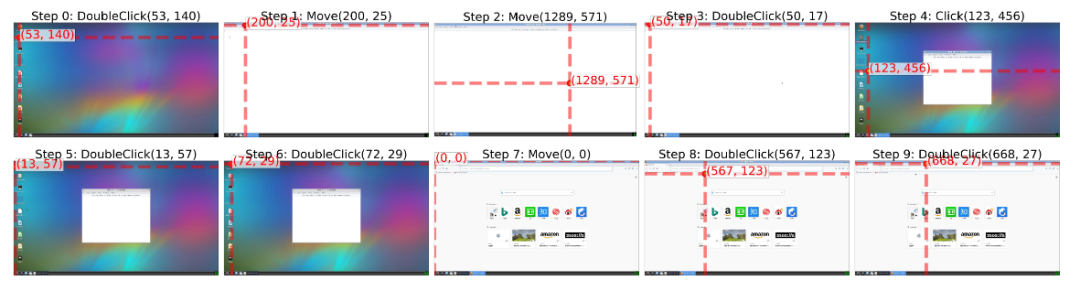
再进行一段时间的探索,模型学会探索到更深的页面:

Qwen2.5-VL-7B 的模型表现更好,在一段时间的训练后甚至能够完成一次完整的“加购物车”过程:
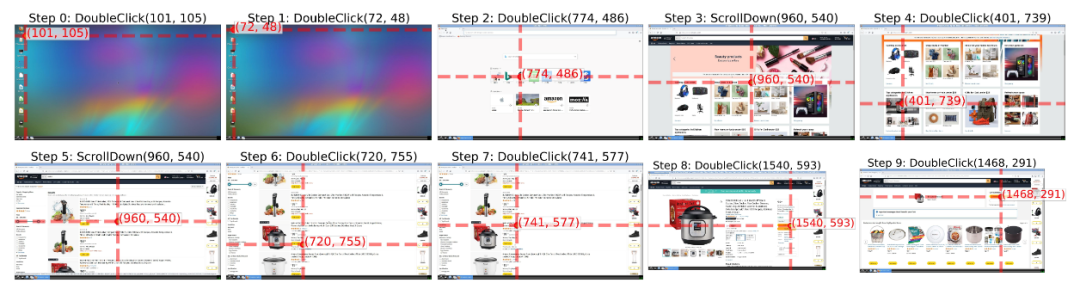
基于启发式和从世界模型导出的奖励都非常易得,因此无需构建具体的任务奖励函数,就能让模型在环境中自己探索起来。动态训练的 ScreenExplorer 能够更加适应当前的环境,与调用静态的 VLM 甚至专门为 GUI 场景训练的模型相比,能够获得更高的探索多样性:
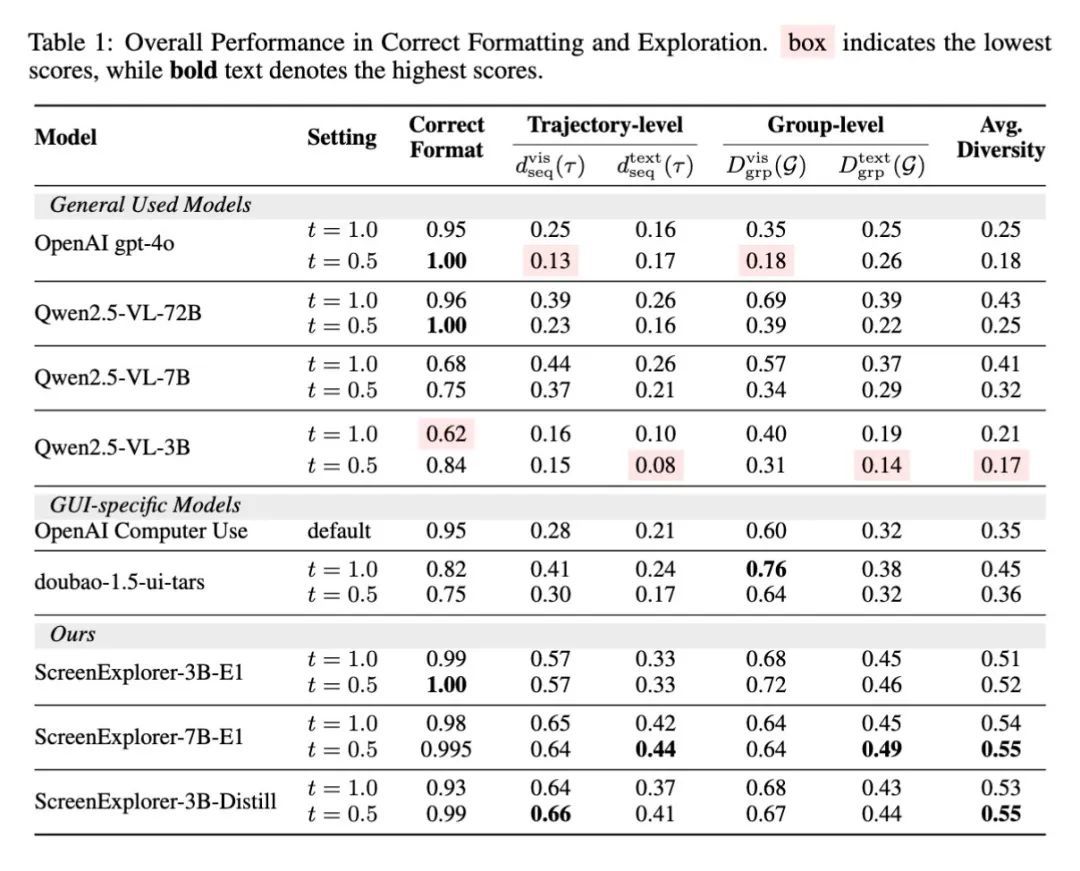
经强化学习训练,原本探索能力最弱的基础模型 Qwen 2.5-VL-3B 成功跃升为探索表现最佳的 ScreenExplorer-3B-E1。更高的探索多样性意味着智能体能够与环境开展更有效的交互,自驱地打开更多软件或探索更多页面,这为接下来训练完成具体任务,或是从屏幕内容中学习新知识,提供了最基础的交互和探索能力。
在训练过程中,各分项的奖励值不断升高。此外,World Model 的重建损失一直保持在较高的水平,这也反应了模型一直在探索新的状态。
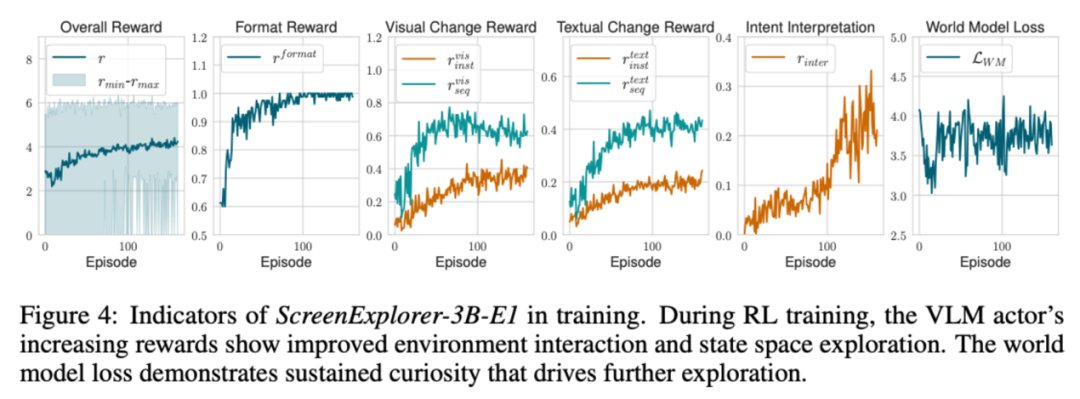
为什么需要世界模型?
文中通过消融实验对比了各类奖励的必要性,尤其关注来自世界模型的好奇心奖励对探索训练的影响。实验发现,一旦去掉来自世界模型的好奇心奖励,模型就很难学习如何与环境进行有效交互,各项奖励都未显现提升的趋势。
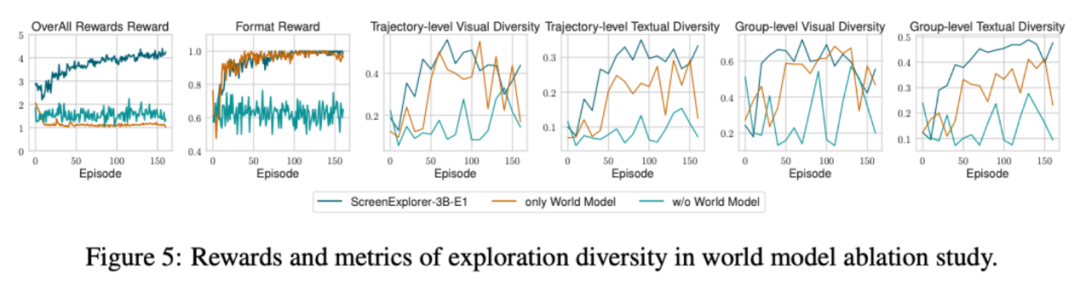
为了进一步了解来自世界模型好奇心奖励给训练带来的影响,文中展示了各种消融设定下 GRPO Advantage 的变化趋势。
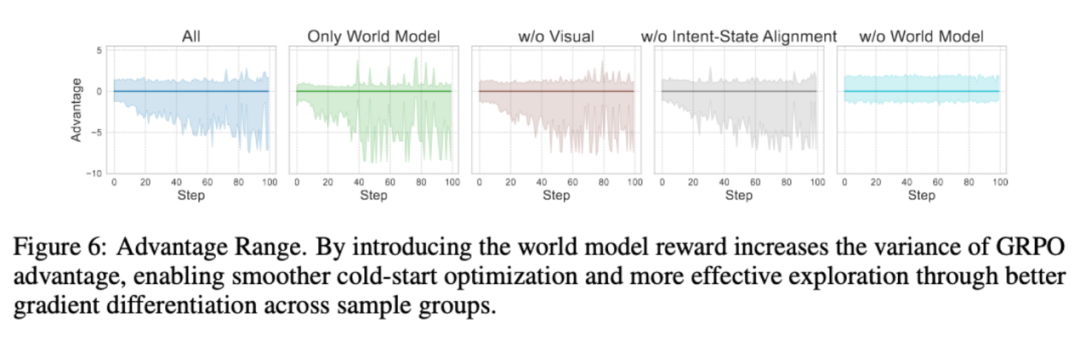
可以发现,来自世界模型的好奇心奖励加大了 Advantage 的方差,这一点变化使得探索过程渡过了冷启动阶段。而没有世界模型奖励的消融组却一直困于冷启动阶段,很难开展有效的探索。
新技能涌现
此外,文中还展示了模型在经过强化学习训练后涌现出的技能,例如:
跨模态翻译能力:
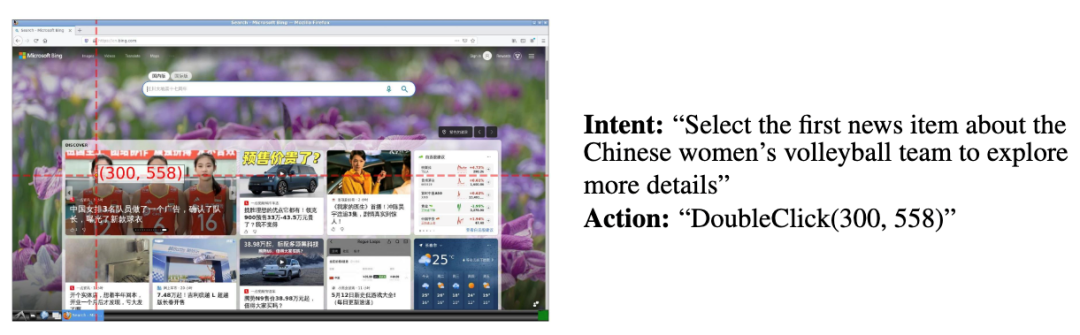
根据现状制定计划能力:

复杂推理能力:
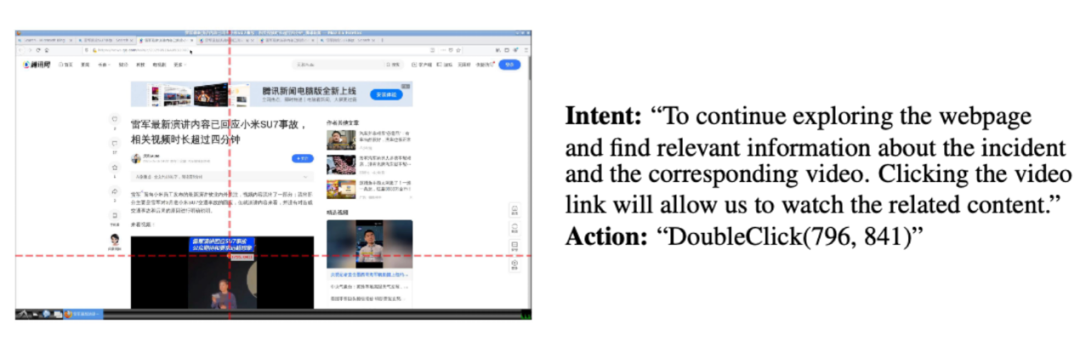
探索产生的样本中,“意图”字段可以视为免费的标签,为之后构造完成具体任务提供数据标注的基础。
结论
本研究在开放世界 GUI 环境中成功训练了探索智能体 ScreenExplorer。通过结合探索奖励、世界模型和 GRPO 强化学习,有效提升了智能体的 GUI 交互能力,经验流蒸馏技术则进一步增强了其探索效率。该智能体通过稳健的探索直接从环境中获取经验流,降低了对人类遥控操作数据的依赖,为实现更自主的智能体、迈向通用人工智能(AGI)提供了一条可行的技术路径。