炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!

本文第一作者为北京邮电大学副教授、彩云科技首席科学家肖达,其他作者为彩云科技算法研究员孟庆业、李省平,彩云科技CEO袁行远。
残差连接(residual connections)自何恺明在 2015 年开山之作 ResNet [1] 中提出后,就成为深度学习乃至 Transformer LLMs 的一大基石。但在当今的深度 Transformer LLMs 中仍有其局限性,限制了信息在跨层间的高效传递。
彩云科技与北京邮电大学近期联合提出了一个简单有效的残差连接替代:多路动态稠密连接(MUltiway Dynamic Dense (MUDD) connection),大幅度提高了 Transformer 跨层信息传递的效率。

大规模语言模型预训练实验表明,仅增加 0.23% 的参数量和 0.4% 的计算量,采用该架构的 2.8B 参数量 MUDDPythia 模型即可在 0-shot 和 5-shot 评估中分别媲美 6.9B 参数量(~2.4 倍)和 12B 参数量(~4.2 倍)的 Pythia 模型,表明了 MUDD 连接对 Transformer 的基础能力(尤其是上下文学习能力)的显著提升。
这是该团队继 DCFormer [2](ICML 2024)后又一项大模型底层架构创新工作,已被 ICML 2025 接收,论文、代码和模型权重均已公开。
背景
在 Transformer 中残差流汇集了多层的信息,同时也为 Attention 和 FFN 提供多路信息,比如在 Attention 模块中需要获取 query、key、value 三路信息,残差流本身也可以看作一路信息流(记作 R)。虽然残差连接的引入首次让训练超深度网络成为可能,但在当今的深度 Transformer LLMs 中仍有其局限:
针对上述局限,MUDD 根据当前隐状态动态搭建跨层连接(可视为深度方向的多头注意力),来缓解深层隐状态的表征坍塌,同时针对 Transformer 每层的 query、key、value、残差等不同输入流采用各自的动态连接,来减少多路信息流的相互干扰,缓解残差流的信息过载,这样既大幅度拓宽了跨层信息传输带宽,又保证了非常高的参数和计算效率。
核心架构
如图 1a 所示,为了实现更直接的跨层交互,DenseNet [5] 将当前 Block 和前面所有的 Block 进行稠密连接(Dense Connectivity)。最近 Pagliardini 等人 [6] 将其引入 Transformer,提出了 DenseFormer(NeurIPS 2025),如图 1b 所示。它通过一组可学习但静态的权重(如 w_i,j)来加权求和前面所有层的输出。这种方式虽然拓宽了信息通路,但静态权重使得对于序列中不同 token 都做同样处理,限制了表达能力。
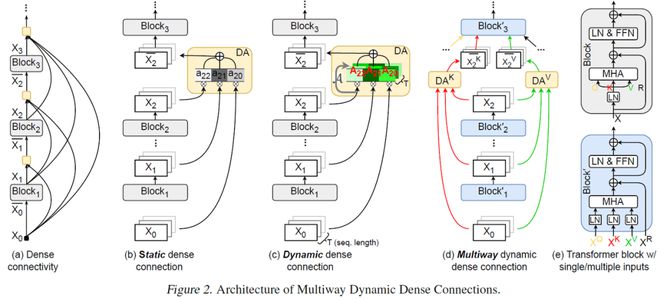 图 1. MUDD 的架构图
图 1. MUDD 的架构图
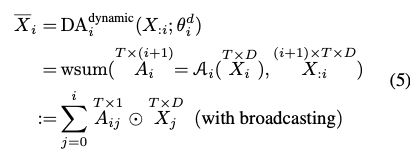

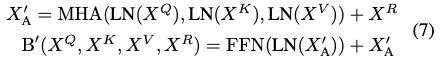
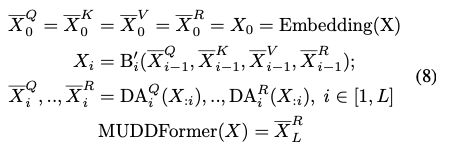
实验评估
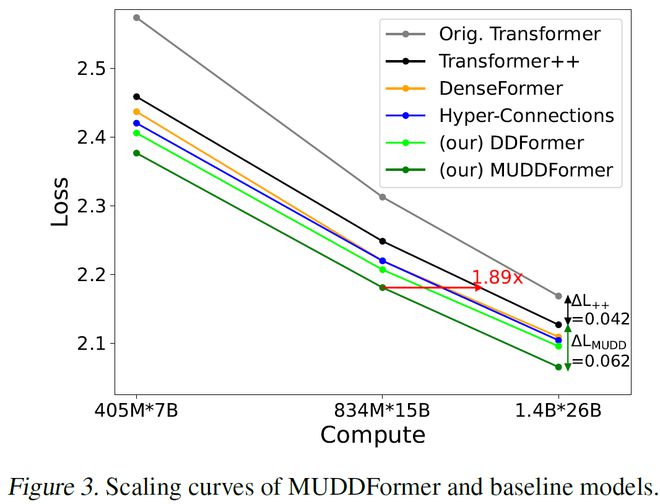 图 2. MUDDFormer 和基线模型的扩展实验
图 2. MUDDFormer 和基线模型的扩展实验研究者在 Pile 数据集上测试了 MUDDFormer 和其他基线模型的扩展能力,如图 2 所示。Hyper-Connections [8] 也是字节跳动 Seed 最近一个发表在 ICLR 2025 的改进残差连接的工作,图 2 中可见 DynamicDenseFormer 已经比 DenseFormer 和 Hyper-Connections 都表现好,而且在解耦多路信息流后,MUDDFormer 又有明显的效果提升。
在所有模型尺寸下 MUDDFormer 都显著领先 Transformer++ 和其他基线模型 (Loss 越低越好),并且其领先优势随着模型增大并未减小。MUDDFormer-834M 的性能,已经超越了需要 1.89 倍计算量的 Transformer++ 基线模型,展现了惊人的计算效率提升。
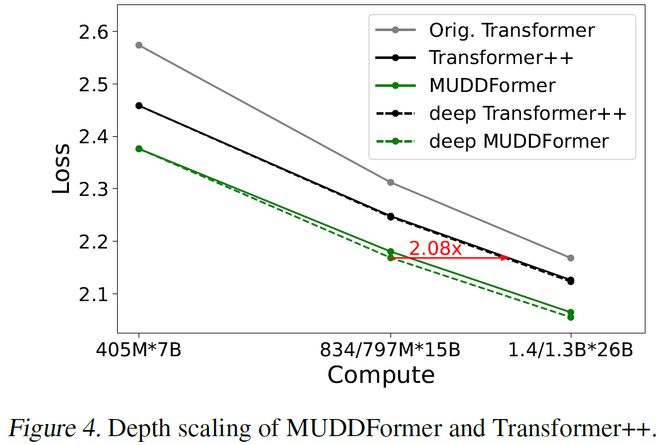 图 3. MUDDFormer 和 Transformer++ 的深度扩展实验
图 3. MUDDFormer 和 Transformer++ 的深度扩展实验为了验证 MUDDFormer 在更深层模型上的有效性,研究者在不增加参数量的前提下增加模型的深度,并进行了扩展实验,如图 3。Transformer++ 在超过 24 层后收益递减(缩放曲线几乎重合),而 deep MUDDFormer 在高达 42 层时仍能保持收益,使得在 797M 下达到了2.08倍 Transformer++ 的性能。这进一步验证了 MUDD 连接可以通过增强跨层信息流来缓解深度引起的瓶颈。
研究者将 MUDD 架构与开源的 Pythia 模型框架结合,在 300B tokens 的数据上进行训练,并与从 1.4B 到 12B 的全系列 Pythia 模型进行比较,如图 4。
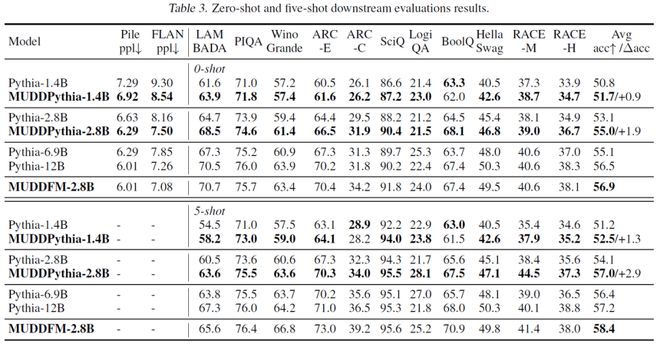 图 4. 下游任务对比测评
图 4. 下游任务对比测评首先,MUDDPythia 在 0-shot 和 5-shot 任务上的平均准确率,都明显高于同等计算量下的 Pythia 模型,而且在 5-shot 下的提升效果更明显,说明上下文能力得到了额外的增强。
从图 5 中可以看出在 0-shot 下,2.8B 的 MUDDPythia 的性能媲美了 6.9B 的 Pythia,实现了 2.4 倍的计算效率飞跃;在 5-shot 下,2.8B 的 MUDDPythia 的性能,甚至追平了 12B 的 Pythia,实现了 4.2 倍计算效率提升!
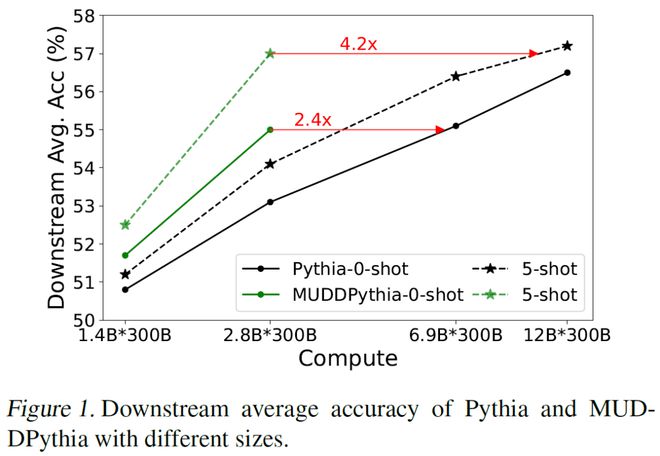 图 5. 下游任务准确率对比曲线
图 5. 下游任务准确率对比曲线这表明,MUDD 所构建的高效信息通路,极大地增强了模型在上下文中动态构建复杂推理回路的能力。
分析
图 6 展示了模型注意力头激活比例随层数的变化,在标准的 Pythia 模型中,随着层数加深大量注意力头都只关注少数几个 token(attention sink [9])并未激活。
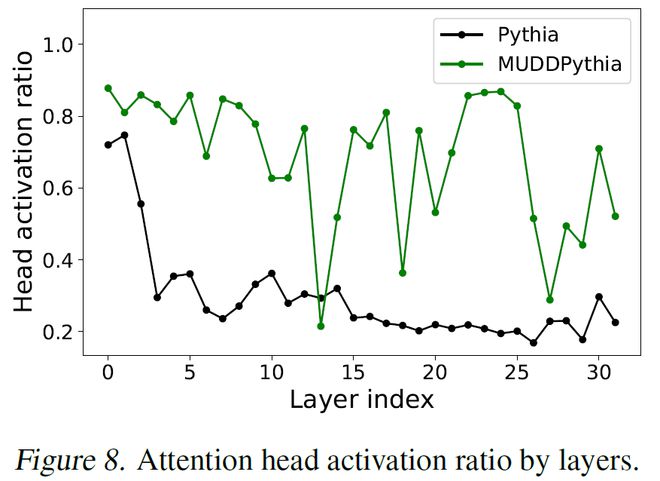 图 6. 注意力头激活比例的逐层变化曲线
图 6. 注意力头激活比例的逐层变化曲线然而,在 MUDDPythia 中,几乎在所有层的注意力头激活率都远高于 Pythia,平均高出约 2.4 倍。这说明 MUDD 连接加强了对 Attention 的利用,也部分解释了上下文能力的增强。
结语
MUDDFormer 通过简单高效的实现改进了残差连接,为 Transformer 内部不同的信息流(Q、K、V、R)建立各自独立的动态跨层连接,不仅增强了 Transformer 模型的跨层交互,而且进一步提升了模型的上下文学习能力。实验证明这种新的连接机制能以微弱的代价,换来模型性能和计算效率的巨大飞跃。MUDDFormer 所展示的潜力,使其有望成为下一代基础模型架构中不可或缺的新基石。
参考文献
[1] He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp. 770–778, 2016.
[2] Xiao, Da, et al. "Improving transformers with dynamically composable multi-head attention." Proceedings of the 41st International Conference on Machine Learning. 2024.
[3] Liu, L., Liu, X., Gao, J., Chen, W., and Han, J. Understanding the difficulty of training transformers. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020b.
[4] Gromov, A., Tirumala, K., Shapourian, H., Glorioso, P., and Roberts, D. A. The unreasonable ineffectiveness of the deeper layers. arXiv preprint arXiv:2403.17887, 2024.
[5] Huang, G., Liu, Z., Van Der Maaten, L., and Weinberger, K. Q. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp. 4700–4708, 2017.
[6] Pagliardini, M., Mohtashami, A., Fleuret, F., and Jaggi, M. Denseformer: Enhancing information flow in transformers via depth weighted averaging. In Proceedings of the Thirty-Eighth Annual Conference on Neural Information Processing Systems (NeurIPS), 2024.
[7] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I. Attention is all you need. Advances in neural information processing systems, 30, 2017.
[8] Zhu, D., Huang, H., Huang, Z., Zeng, Y., Mao, Y., Wu, B., Min, Q., and Zhou, X. Hyper-connections. In Proceedings of the Thirteenth International Conference on Learning Representations (ICLR), 2025
[9] Xiao, G., Tian, Y., Chen, B., Han, S., and Lewis, M. Efficient streaming language models with attention sinks. In The Twelfth International Conference on Learning Representations (ICLR), 2024b.