炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
Agent能“看懂网页”,像人类一样上网?
阿里发布WebDancer,就像它的名字一样,为“网络舞台”而生。
只要输入指令,它就可以帮你上网搜索、做攻略,实现自主信息检索代理和类似深度研究模型的推理。
传统模型只能按固定流程思考,而WebDancer作为一个端到端的自主信息搜索智能体,具备多步推理、工具使用和泛化能力。
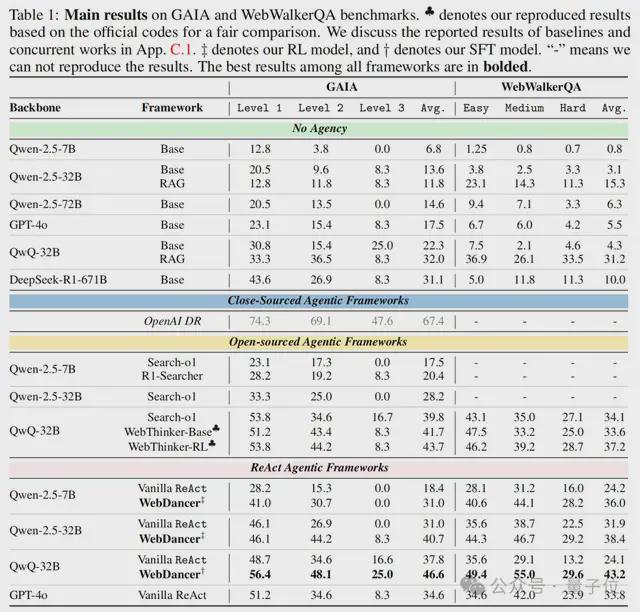
WebDancer在GAIA和WebWalkerQA上分别取得了61.1%和54.6%的Pass@3分数,优于基线模型和部分开源框架。
模型和方法均已开源,网友直呼想试:
WebDancer的秘密武器
不同于其它的推理问答模型,WebDancer要像人类一样思考、理解并操作,可不是一件简单的事情。
使用GAIA、WebWalkerQA和日常使用情况对WebDancer进行演示,可以看到,WebDancer能够执行多步骤和复杂推理的长期任务,例如网页遍历、信息搜索和问答。
它的“秘密武器”是一种四阶段训练范式,包括浏览数据构建、轨迹采样、针对有效冷启动的监督微调以及用于改进泛化能力的强化学习。
阿里开源了这个训练框架,使除了WebDancer以外的智能代理也能够自主获取自主搜索和推理技能:
1、浏览数据构建
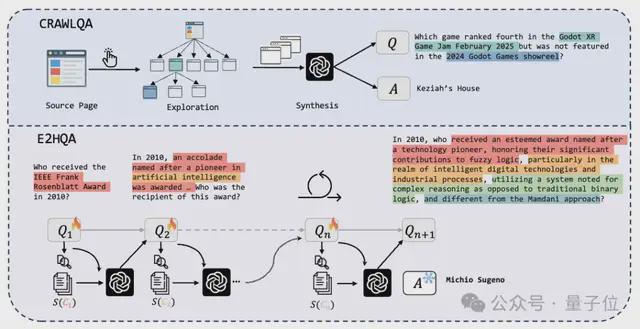
这一步的目标是创建覆盖真实的网页环境、需要多步交互的复杂QA对。
可以分为两个网络数据生成流程,如上图所示。
在CRAWLQA中,需要先收集知识性网站(ArXiv、GitHub、Wiki等)的主URL,然后在主页上系统地点击和收集通过子链接可访问的子页面,模拟人类行为。
使用预定义规则,就可以利用GPT4o根据收集到的信息生成QA对(1.0版)了。
对于E2HQA(Easy-to-Hard QA)来说,将初始的简单问题Q1通过实体检索→信息扩展→问题重构的步骤,使任务在复杂性上逐步扩展,从简单的实例到更具挑战性的实例。
依然是使用GPT-4o重写问题,直到迭代达到n,QA对足够成熟。
2、轨迹采样
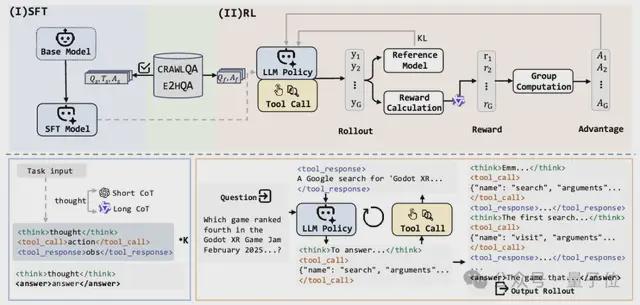
这一步要从QA对中生成高质量的思维-动作-观察(Thought-Action-Observation)执行轨迹。
WebDancer的代理框架基于ReAct,这是语言代理最流行的方法,一个ReAct轨迹由多个思维-动作-观察轮次组成:
在思维阶段,模型会根据输入生成推理链,然后在动作阶段将参数为结构化JSON,最后在观察阶段返回结果(如网页摘要或搜索片段)。
思维阶段生成的思维链对智能体执行十分重要,WebDancer采用了双路径采样的方法,可分为短思维链和长思维链两条路径:

因为LRM、QwQ-Plus在训练过程中没有接触过多步推理输入,在进一步推理时,WebDancer排除了之前的思维,但它们作为有价值的监督信号保留在了生成的轨迹中。
随后,WebDancer采用了一个基于漏斗的三阶段轨迹过滤框架,仅保留满足以下三个标准的轨迹:信息非冗余、目标一致性以及逻辑推理准确性。
3、有监督微调
在获得ReAct格式的优质轨迹后,就可以将其无缝整合到智能体的有监督微调(Supervised Fine-Tuning,SFT)训练阶段,这个步骤可以教会模型基础的任务分解与工具调用能力,同时尽可能保留其原有的推理能力。
在SFT阶段,要先将轨迹转换为标记化输入,明确分隔符,然后计算Thought和Action部分的损失(忽略Observation噪声),损失公式如下:
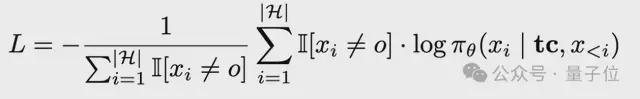
其中tc
是任务上下文,
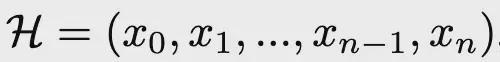
为完整的智能体执行轨迹,每个

代表思考/行动/观察,
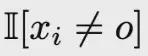
过滤掉对应外部反馈的标记,确保损失是在代理的自主决策步骤上计算的。
SFT阶段为后续的RL阶段提供了强大的初始化。
4、强化学习
这一步的目标是优化代理在真实网络环境中的决策能力和泛化能力。
在SFT阶段的基础上,本阶段采用解耦裁剪动态采样策略优化算法(Decoupled Clip and Dynamic Sampling Policy Optimization,DAPO)来精调策略模型。
DAPO是一种基于奖励模型R的策略优化算法,其工作原理如下:
首先,对于每个包含部分答案
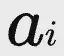
的阶段轨迹
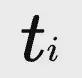
,算法生成一组候选执行序列
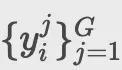
。通过最大化以下目标更新策略:
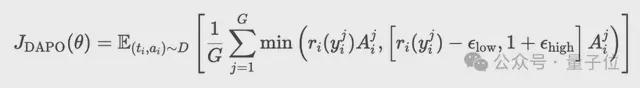
随后,过采样并过滤准确率为1或0的提示(prompts),确保智能体聚焦于高质量信号的学习。
最后,采用新旧策略的概率比替代固定KL惩罚项:
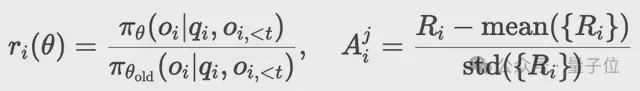

奖励设计在RL训练过程中起着至关重要的作用,WebDancer的奖励机制主要由两种类型的奖励组成,分别为格式奖励和答案奖励,权重分别为0.1和0.9。
最终奖励函数为:
有效性分析
在GAIA和WebWalkerQA这两个成熟的基准数据集上测试WebDancer,结果显示,WebDancer在GAIA上达到46.6%的平均准确率,WebWalkerQA上达到43.2%,优于基线模型和部分开源智能体框架。
可以看到,不具备代理能力的框架(No Agency)在GAIA和WebWalkerQA基准测试中均表现不佳,这突出了主动信息搜索和代理决策对于这些任务的重要性。
闭源代理系统OpenAI DR通过端到端强化学习训练实现了最高分,在开源框架中,基于原生强推理模型(如QwQ-32B)构建的代理方法始终优于非代理对应方法,证明了在代理构建中利用推理专用模型的有效性。
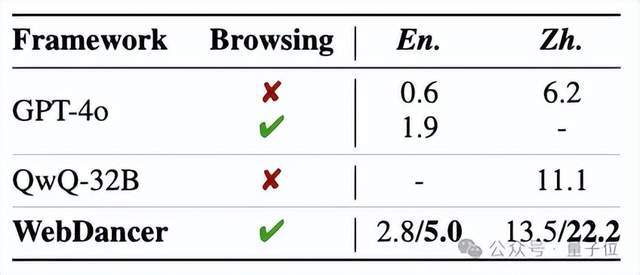
在两个更具挑战性的数据集BrowseComp(英文)和BrowseComp-zh(中文)上测试WebDancer,均表现出持续强劲的性能,突显了其在处理困难推理和信息搜索任务中的鲁棒性和有效性。
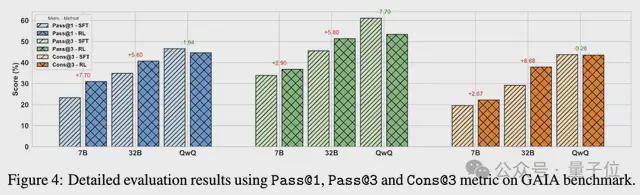
鉴于智能体环境的动态性和复杂性,以及GAIA测试集相对较小且变化较大的特点,对Pass@3和Cons@3进行细粒度分析。
值得注意的是,经过RL后的Pass@1性能与SFT基线的Pass@3相当,表明RL能够更有效地采样正确响应。
对于语言推理模型(LRMs),虽然经过RL后Pass@1、Pass@3或Cons@3没有显著提升,但在一致性方面有明显的改善;这可能是过长轨迹导致的稀疏奖励信号所致。
参考链接:
https://x.com/_akhaliq/status/1937997314737553873
论文:https://arxiv.org/abs/2505.22648
github:https://github.com/Alibaba-NLP/WebAgent/tree/main/WebDancer
模型:https://huggingface.co/Alibaba-NLP/WebDancer-32B