炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!

新智元报道
编辑:Aeneas 好困
【新智元导读】谁会第一个到达ASI?SemiAnalysis大佬Dylan Patel脱口而出:OpenAI!最近,这位圈内最懂AI和芯片的大佬,毫不留情地戳穿了GPT-4.5惨败的原因,还揭露了Meta仓促模仿DeepSeek结果大翻车的内幕。
谁会首先到达ASI(超级智能)?OpenAI!
大佬斩钉截铁的回答,让主持人惊呆了几秒。

就在刚刚,AI大V Matthew Berman放出对Dylan Patel长达1小时的访谈,后者爆出不少猛料。
Patel是SemiAnalysis创始人兼CEO。SemiAnalysis的大名,在业内是如雷贯耳,每出一篇关于AI和半导体的重磅分析,都会被业内人士竞相转载,拥有极高的行业影响力。
而Patel本人,对AI领域的认知更是达到了无与伦比的深度和广度。

在访谈中,Patel表示,如今很多全球顶尖AI公司内部,已经是乱成一锅粥了!
看完这个访谈,许多网友表示,信息密度实在太大,全程高能,太值得一听了。

Meta、OpenAI、苹果、英伟达、xAI、微软,这些大科技公司在硅谷的混乱局面中,谁将主宰下一个浮沉?
让我们来看看大佬的犀利分析和预言。

Meta疯狂挣扎,小扎作困兽之斗
借鉴DeepSeek,结果翻车了?
首先,两人讨论的是最近闹出了天价挖人风波的Meta。
Llama 4发布已经有一阵子了,当时大家的期待值非常高,但它却并没有改变世界,随后,Behemoth模型又被推迟了。
而在Patel看来,Behemoth恐怕永远不会发布了。同样命运的还有Maverick和Scout。这些模型的一些训练方式和决策,后来被证明是行不通的。
本来在发布时,有个模型感觉还行,但后来在阿里和DeepSeek发的新模型前,一下子就显得逊色了。
而另一个模型,客观上来讲就是很差劲。Patel表示,我敢打赌,那个模型就是为了应对DeepSeek而赶工出来的。


他们借鉴了DeepSeek的MoE架构,但搞砸了,如果仔细去看,这个模型甚至不会把Token传送到某些专家模块,可以说训练基本就是白费了!
最终结果,就是一堆专家在那里无所事事,显然训练出了问题。
诡异的是,Meta明明拥有全球最顶尖的人才,也不缺算力,怎么就搞砸了?

这一点,他们应该向OpenAI学习。
奥特曼负责搞定所有资源,Greg Brockman和Mark Chen等人则是技术领袖,总之,要有一个懂技术、能做决断、能选对方向的领导。
否则,后果就是这些顶尖研究员会把时间浪费在错误的路线上。

事实上,[品味”非常重要,判断什么值得研究、什么不值得,这本身就是一种艺术。
一个想法当然可以用几十万个GPU跑一次来验证,但事情不会完美地等比放大,这其中需要大量的品味和直觉。
如果错误的人通过一些政治手段,让自己的想法和研究路径被采纳进了模型,结果很可能就是翻车。
小扎为何突然转向AGI
最近,无论是收购Scale AI(本质上是收购Alexandre Wang),还是1000万美元年薪天价挖来OpenAI员工,都让小扎处于争议的风口浪尖。

Patel点评到,Scale AI作为一家公司,现在业务基本上是完蛋了,因为谷歌在内的所有公司,都在取消和他们的合同(据说谷歌今年本来要在Scale AI身上花2.5亿美元的)。
而OpenAI,也已经和Scale AI彻底决裂。没有任何一家公司,希望Meta知道自己的数据在用来干什么。
Patel指出,最近这几个月,小扎的转变十分微妙。
在几个月前的采访中,他还认为ASI短期内不会实现。但如今,他真的信了ASI,所以,要做什么才能追上来?
目前,他还是纯靠砸钱。OpenAI、SSI、Thinking Machines的全明星团队,基本被他挖了个遍。
甚至传闻中,Meta愿意开出上亿美元年薪,挖不动人,就买下整个公司。

这场AI军备竞赛的本质是什么?
说到底,还是对“权力”的争夺:谁能带队造出超级智能、谁就能掌控万亿级公司的AI战略,能把产品推向数十亿用户。
这,是一场产品人、理想主义者和科技巨头之间的全面竞速。
超级智能,已经不是“能不能”,而是“谁先”。




其实要说到底,在超级智能这块,真正引领潮流的还是Ilya。
他总是率先看到一切。可以说,是Ilya引领了这波叙事转向。他先创办了自己的公司SSI(安全超级智能),大概在一年后,所有人都开始相信超级智能了。
而对于预训练规模化、推理、早期的视觉网络,他也是最早开始深入研究的一批人之一。
但对于小扎的收购,他果断拒绝了。可以看出来,Ilya根本不在乎钱,他想要的就是实现ASI,是一个真正的信徒。

而对Meta来说,如果最终目标是超级智能,那么相比Meta目前的市值,以及AI的整个潜在市场,无论是1亿美元,还是10亿美元,都只是沧海一粟而已。
GPT-4.5的失败,究竟是因为什么?
接下来,主持人抛出了这个问题:GPT-4.5到底怎么了?
Patel一句话金句总结:总的来说,它没什么用,而且太慢了。

曾经,GPT-4.5的内部代号是Orion,本来被寄望于成为GPT-5。
为此,OpenAI下了血本,从2024年初就开始训练,全力押注规模。他们用上了所有数据,造出一个大得离谱的模型。
结果呢?Patel表示,虽然它的确是第一个把自己逗笑的模型,但并没有那么好用,速度太慢,也太贵了。
惨败的原因就在于“过度参数化”——
它并不是在建立世界模型,而是在泛化。某种程度上,GPT-4.5就是因为太大、过度参数化,记住了太多东西,所以就不再进步了。

要知道,刚开始,OpenAI内部都觉得它要在基准测试上大杀四方了,然后事实却让所有人失望了。
而且倒霉的是,训练代码里还有个bug,直接持续了几个月。虽然这个bug很小,却搅乱了整个训练。好在最终,研究者们发现并修复了这个PyTorch内部的bug。

另外,他们还不得不频繁地从checkpoint重启训练,原因就在于模型太大、太复杂了,任何环节都可能出错。
而且,就算基础设施、代码都完美无瑕,仍然可能遇到数据的问题。
在2022年,谷歌DeepMind在发表的Chinchilla论文里,提到过模型参数量和Token数的最佳比例(训练数据量大约应该是模型参数量的20倍)。
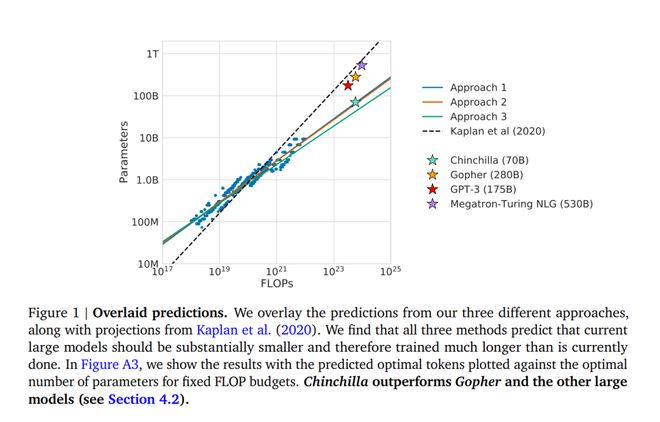
这就是大家公认的Scaling Law——模型做得越大,投入的flops越多,模型就越好。
然而如今,随着模型架构的变化,这篇论文里的结论已经不再适用了。
在2024年初开始训练GPT-4.5时,他们就不得不使用了远超Token数量的参数。
然而与此同时,OpenAI的另一个团队却有了关于推理的神奇发现,就是当时被传得沸沸扬扬的“Strawberry”。
已经投入巨资训练庞然大物的OpenAI才发现,原来完全靠推理,就可以用低得多的成本让模型的效率和质量得到巨大提升。
总之,GPT-4.5之所以失败,就是因为数据不够。而最终,Strawberry证明了推理的魔力。

OpenAI和微软:昔日CP,分道扬镳
另一方面,曾经的OpenAI和微软这对“AI界最强CP”,显然也过了蜜月期。
过去几年,OpenAI靠着微软的大力投资和Azure算力迅速崛起,然而两家公司的合作协议,实在是太过复杂——
微软没有OpenAI的股权,却拥有它大部分利润的分成权、所有IP使用权,甚至在AGI实现前,能使用OpenAI的所有技术。
也就是说,只要你造出了超级智能,微软就能在头一天把代码全部打包带走。

而且,起初OpenAI还被限制只能用微软的云服务,但随着星际之门的推进,他们也开始和Oracle、CoreWeave合作。
然而,微软虽然放弃了独家权,但保留了“优先承购权”以降低反垄断风险。
问题是,如今的OpenAI野心膨胀,想成为地球上最为资本密集的初创公司,因此烧钱无上限、五年内不打算盈利,还要不断融资;而微软呢,虽然手握代码库,却还没真正动手自己搞模型。
双方都一样,心照不宣地防备彼此。接下来,谁先走出下一步,这种脆弱的平衡,就很可能要打破了。
苹果,在AI上重大失误
而在目前的AI大战中,苹果似乎是显而易见的输家了。
他们既没公开大模型、也没泄露任何研发细节。业内已经普遍认为,这不是“佛系”,而是彻底的结构性落后。
要深究原因的话,就是苹果保守的收购策略、对开源文化的疏离、对GPU巨头英伟达的长期芥蒂,以及自身缺乏AI研究氛围的现状,都让它很难吸引到顶尖的AI人才。
因此,在Meta、OpenAI、Anthropic等公司疯狂抢人的同时,苹果最多只能招到“第二梯队”的人才。

而他们所推崇的端侧AI之路,也没那么容易走通。
虽然苹果在大力强调隐私与低延迟,但现实却是,大模型越来越庞大,手机芯片根本跑不动。
而大多数用户宁可免费用云端AI,也不愿为本地推理多掏几百美元去买硬件。
而且即便是能在设备上跑通一些轻量任务(比如键盘预测),真正复杂的AI服务——搜索、日程规划、订票助手,依然还是需要依赖云端数据与算力。
苹果也清楚这一点。
所以,他们正悄悄建造超大数据中心,部署Mac芯片做云端AI推理,还挖来了谷歌TPU团队的关键人物,希望自研AI加速器。
可见,虽然表面强调的是“本地AI”,但他们真正押注的,其实还是云端。
别家都在卷大模型,但苹果已经另辟蹊径,开始为AI时代的“云大战”做准备了。
超级智能,靠烧钱能到达?
所以最终,在Meta、谷歌、OpenAI、微软、特斯拉这些公司中,如果必须选一家来赌谁会率先实现ASI,你会选谁?
Dylan Patel的答案是——OpenAI。
原因在于,他们是每个重大突破的先行者,几乎主导了每一个关键技术突破——从预训练到推理,再到多模态能力,始终走在最前面。
而且,单靠推理可能并不会带我们进入下一代AI,最终一定还得有别的东西。OpenAI给人感觉,还在酝酿着更大的技术野心。
而第二名,就是Anthropic。
不过,虽然他们技术强大、团队深厚,但风格却太保守了——无论在模型发布、研究透明度、安全策略上。都是步步为营,小心谨慎。
不过可以看到,现在他们也逐渐放开了,Claude 4的发布节奏就明显比Claude 3快很多,招聘也开始招“正常人”了。
而第三名,就是谷歌、Meta 和xAI之争。
其中,谷歌技术底子雄厚,xAI有马斯克资源加持,而Meta则是不吝砸巨资挖人。
如今,这场超级智能之战才刚刚开始,谁都有可能先到终点。
而这过程中比拼的可不仅仅是技术,而是意志与资源的全面博弈。
参考资料:
https://www.youtube.com/watch?v=cHgCbDWejIs