炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
面对扩散模型推理速度慢、成本高的问题,HKUST&北航&商汤提出了全新缓存加速方案——HarmoniCa:训练-推理协同的特征缓存加速框架,突破DiT架构在部署端的速度瓶颈,成功实现高性能无损加速。
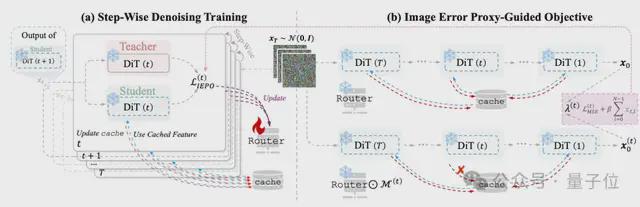 △HarmoniCa整体压缩框架
△HarmoniCa整体压缩框架由于现有指标并不能完全反映图像效果优劣,因此该团队研究人员提供了大量可视化效果对比图,更多对比请看原论文。
 △PIXART-图像生成效果图
△PIXART-图像生成效果图该工作已被ICML 2025接收为Poster,并开源项目代码。

Diffusion 加速难在哪?
Diffusion Transformer(DiT)作为高分辨率图像生成主力架构,在推理阶段仍面临“重复计算多”“耗时严重”的现实瓶颈。例如,使用PIXART-α生成一张2048×2048图像即需14秒,严重影响落地效率。
近期“特征缓存(Feature Caching)”成为加速新思路,但已有方法普遍存在两大关键问题:
前序时间步无感知:训练阶段忽略缓存历史,推理时则高度依赖先前结果,二者逻辑断裂;
训练目标错位:训练对准中间噪声误差,推理关注最终图像质量,优化方向南辕北辙;
这两大错配,导致已有缓存学习方法加速有限、图像失真明显。缓存机制的基本工作原理如下:
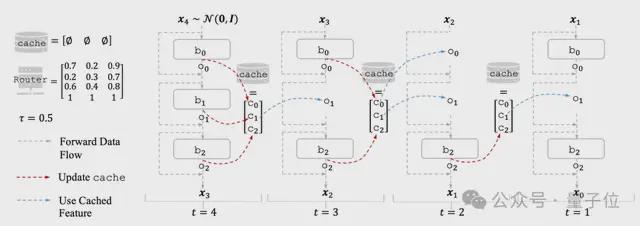 △缓存机制
△缓存机制HarmoniCa缓存学习框架
一句话总结:目标一致、路径同步,训练与推理真正协同优化
该工作提出的HarmoniCa框架通过两个关键机制,从根本上解决了以往学习型特征缓存方法中的训练-推理脱节问题:
一、Step-Wise Denoising Training(SDT)
逐步去噪训练,模拟推理全流程,误差不再层层积累。
传统方法在训练时仅采样某个时间步,缓存是空的,完全跳过了“历史缓存影响”,而推理时,缓存是从头累积的,训练和推理根本不是一回事。
进而该工作提出 SDT 来打破这一不一致:
1)构建完整的 T 步去噪过程,与推理一致;
2)教师-学生结构:学生使用缓存进行去噪,教师不使用缓存作为“理想输出”;3)每一时间步的Router都被独立更新,显式对齐多轮缓存路径下的输出误差;4)学生模型每步将自己的输出作为下一个输入,使得误差传播机制贴近真实推理轨迹。
效果:SDT显著降低了时间步间误差积累,提升最终图像清晰度与稳定性。
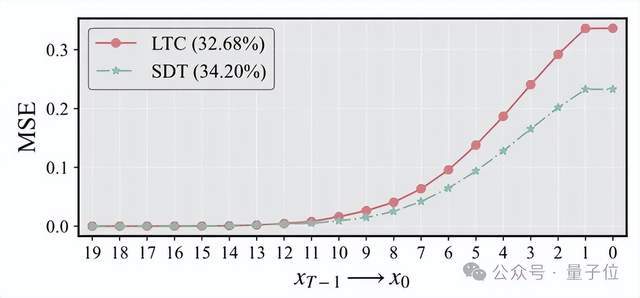 △SDT 有效抑制误差蔓延(红色为旧方法,蓝色为 SDT)
△SDT 有效抑制误差蔓延(红色为旧方法,蓝色为 SDT)二、Image Error Proxy Objective(IEPO)
一句话总结:不是“中间好”,而是“最后图像好”,优化目标就是结果本身。
以往方法训练时只对齐每一步的噪声误差,而推理的目标是最终图像质量,两者目标严重错配,导致缓存Router学出来“看似合理”但效果很差。
该工作提出 IEPO 机制,核心思想是:
通过代理项 λ(t) 来估算“使用缓存 vs 不使用缓存”在时间步 t 对最终图像 x₀ 的影响;
越关键的时间步,其 λ(t) 越大,引导 Router 减少该步缓存复用,保留精度;
每隔若干轮重新生成一批图像,动态更新 λ(t),保证目标始终贴合训练状态。
IEPO 的优化目标为:
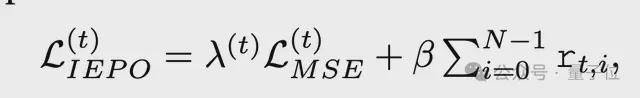
即在“图像质量”与“加速率”之间实现可控权衡。
实验结果
该工作在两个典型任务场景中验证了HarmoniCa的有效性:
对比方法包括当前最佳的缓存学习方法 Learning-to-Cache (LTC)、启发式缓存方法 FORA / ∆-DiT,以及多种加速器设置(DDIM 步数缩减、量化剪枝等)。
分类条件生成(DiT-XL/2 256×256)
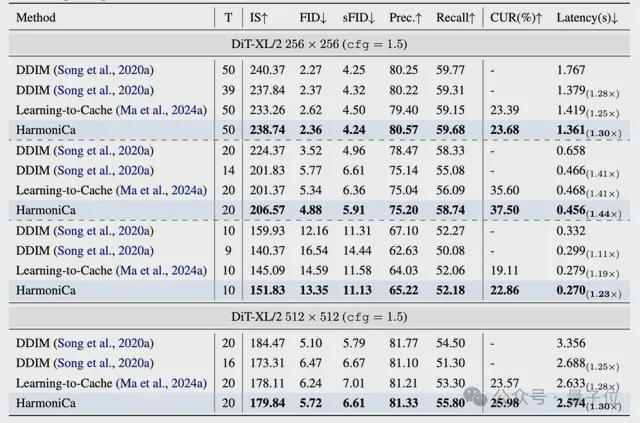
重点结论:
文本生成图像(PIXART-α 256×256)
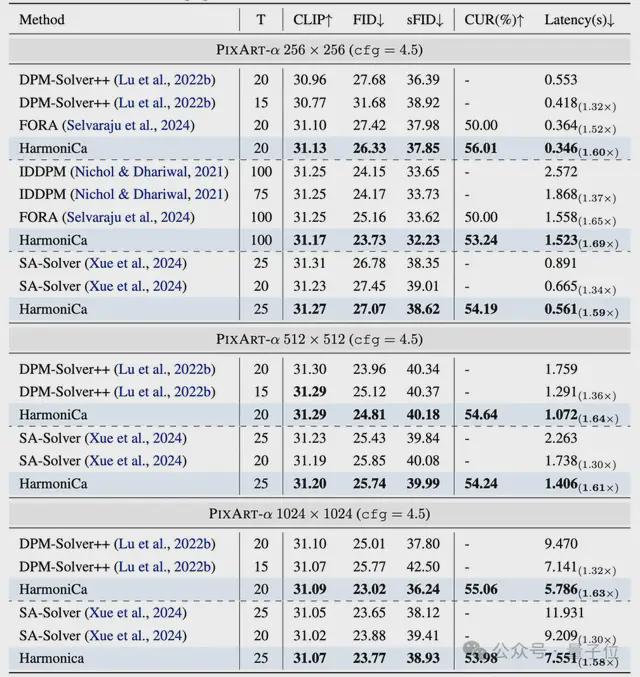
重点结论:
量化/剪枝VS HarmoniCa
除了与主流缓存方法的对比,该工作也评估了HarmoniCa相比剪枝和量化等压缩技术的表现。在统一的 20 步采样设置下,传统方案如 PTQ4DiT、EfficientDM等虽然模型更小,但实际加速依赖硬件支持,特别是一些定制CUDA内核在H800等新架构上表现并不稳定。更重要的是,量化模型在小步数采样时往往精度下降严重,PTQ4DiT就出现了明显的性能下滑。而HarmoniCa不依赖底层魔改,无需专用硬件,在各种主流采样器和设备上都能稳定提速,保持图像质量,是当前更通用、更稳妥的部署选择。
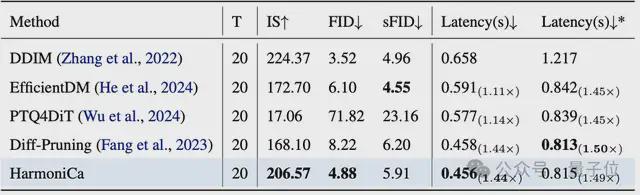 △与量化/剪枝方法的比较
△与量化/剪枝方法的比较与量化结合
该工作还验证了HarmoniCa与模型量化技术的高度兼容性。在 PIXART-α 256×256 场景下,将HarmoniCa应用于4bit量化模型(EfficientDM),推理速度从1.18×提升至1.85×,FID仅略增0.12,几乎无感知差异。说明HarmoniCa不仅可独立提速,也能作为“加速插件”叠加于量化模型之上,进一步释放性能潜力。未来,该工作也计划探索其与剪枝、蒸馏等技术的组合能力,为DiT模型的轻量部署开辟更多可能。
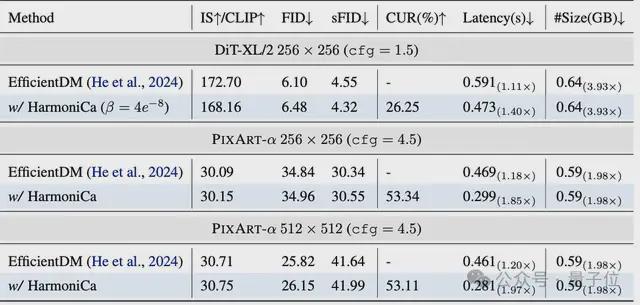 △HarmoniCa和量化方法的组合
△HarmoniCa和量化方法的组合开销分析
除了推理提速和质量提升,HarmoniCa 在训练与推理开销上也展现出极强优势,是真正能用、敢用、易部署的工业级方案。
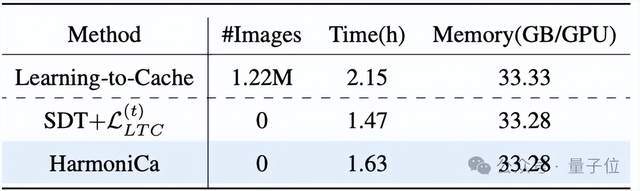 △训练开销对比
△训练开销对比训练侧:
HarmoniCa 采用无需图像的训练策略,仅基于模型和噪声即可完成优化,不依赖任何额外数据。在同等训练轮次下,其训练时间比主流方案 LTC 缩短约 25%,显存占用相近,可在单卡稳定运行,适合闭源模型加速和快速迭代。
推理侧:
推理端新增 Router 极其轻量,参数仅占 0.03%,计算开销低于总 FLOPs 的 0.001%,几乎不影响吞吐。配合特征缓存,HarmoniCa 在 PIXART-α 上可实现理论加速比2.07×、实测加速1.69×,具备优越的部署效率与工程可行性。
总结:缓存加速的新范式,训练推理协同才是正解!
当前Diffusion加速路径中,缓存机制正逐渐成为主流方案,但传统做法要么依赖手工规则、要么训练目标错位,无法在真实部署中兼顾性能、效率、适应性。
该工作提出的HarmoniCa框架,首次通过:
在PIXART、DiT、LFM等多个模型上,HarmoniCa都实现了更快的推理、更高的质量、更低的训练门槛,为缓存加速技术注入“可落地”的关键支撑。
论文地址:https://arxiv.org/abs/2410.01723
代码地址:https://github.com/ModelTC/HarmoniCa