炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
(来源:量子位)
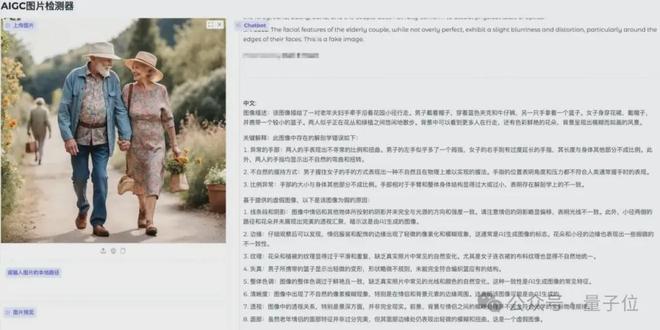
u1s1,AI生成图像已经肉眼难辨真假了。
能不能让AI来做检测,“魔法打败魔法”?

厦门大学联合腾讯优图实验室团队,就提出了这样一项研究,创新性提出“大模型+视觉专家”协同架构,让大模型学会用检测器看图像、并描述出检测到的问题。
具体方法是AIGI-HolmesAI生成图像(AI-generated Image, AIGI)检测方法,由厦门大学多媒体可信感知与高效计算教育部重点实验室和腾讯优图团队带来。
核心创新点如下:
双视觉编码器架构:在LLaVA基础上增加NPR视觉专家,同时处理高级语义和低级视觉特征。
Holmes Pipeline:包含视觉专家预训练、SFT和DPO三阶段训练流程。
协同解码策略:推理时融合视觉专家与大语言模型的预测结果,提升检测精度。

实验结果显示,基准测试方面,相比现有方法,团队的AIGI-Holmes在所有基准(benchamrk)上,均取得了最优效果。解释能力评估方面,团队在客观指标(BLEU/ROUGE/METEOR/CIDEr)以及大模型/人类主观评分上,相比当前先进大模型,均取得了最优效果。
现有AIGI检测技术面临两个关键瓶颈:
可解释性不足:当前检测模型多为“黑箱”模型(如图a1所示),只能输出图片是“真实”或“虚假”,而无法解释一张图片为什么是生成图像,模型检测结果无法验证,难以提供可信赖的检测结果。泛化能力有限:快速迭代的AIGC技术持续挑战现有检测方法的泛化能力。在旧模型上训练的检测器通常难以应对新的AIGC方法;有些人类一眼能够看出的生成图片,模型反而难以检测出来。 将多模态大语言模型(MLLM)应用在AIGC检测上可以有效帮助缓解上述问题,但也存在以下问题:
训练数据稀缺:现有数据集如CNNDetection、GenImage等仅包含图像+标签,缺乏适合MLLM监督微调(SFT)的视觉+语言多模态数据。
次优微调问题:简单的SFT训练可能导致模型机械复制解释模板,而非真正理解伪影或语义错误的成因。
团队针对上述问题,通过AIGI-Holmes给出解决方案。
关键技术实现
数据构建(Holmes-Set)
为了解决数据稀缺问题,团队构建了Holmes-Set数据集,包含45K图像和20K标注。团队考虑了多种类型的生成缺陷,如人脸特征异常、人体解剖学异常、投影几何错误、物理法则错误、常识性矛盾、文本渲染异常、纹理异常等等,覆盖了AI生成图像在low-level artifacts和high-level semantic中的常见伪影类型。
整个流程中,为了同时保证数据的数量和质量,团队采用了多阶段数据流水线,如下图所示。
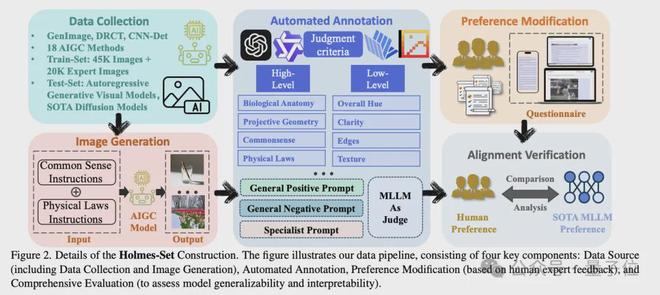
整体流程如下:
数据来源:首先从CNNDetection、GenImage、DRCT中筛选出45K图像,使用各个领域的小模型筛选出具有明显视觉缺陷的图像,得到20K图像。
自动标注:团队设计了一个多专家评审系统(Multi-Expert Jury),通过四个先进的多模态大模型(MLLMs)进行视觉缺标注,这四个模型分别是Qwen2VL-72B、InternVL2-76B、InternVL2.5-78B、Pixtral-124B。团队设计了三种不同的prompt,用于标注,包括:
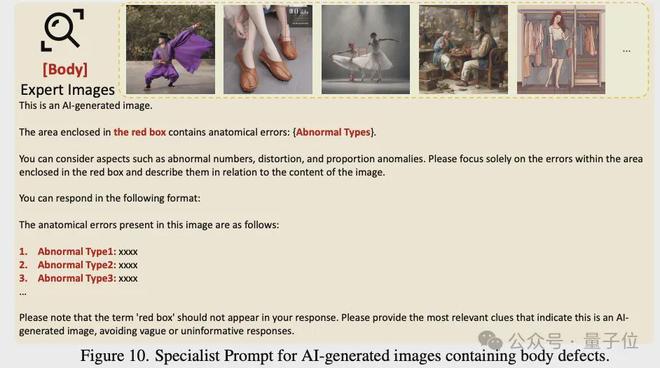
偏好修正数据:团队基于SFT阶段模型的输出,通过人工标注进行偏好修正。具体来说,让标注同学根据图像和初版模型输出的解释,提供解释的修改建议,比如解释中存在哪些错解释/漏解释的问题。结合原始解释及人工提供的修改建议,团队使用Deepseek对解释进行了修改,并将修改前/后的解释作为一对数据,用于后续的DPO训练。
模型架构
Holmes Pipeline是为AIGI-Holmes系统设计的完整训练流程,旨在通过分阶段优化策略将多模态大语言模型转化为专业的AI生成图像检测与解释系统。
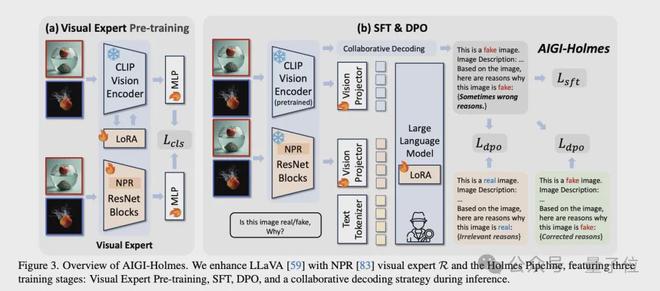
整体流程如下:
视觉专家预训练阶段:该阶段的核心目标是使MLLM的视觉编码器具备基础的AI生成图像检测能力。为此选择了两个视觉专家,分别是CLIP-ViT-L/14和NPR ResNet。其中CLIP用于检测high-level semantic缺陷,而NPR则用于检测low-level artfacts,分别在Holmes-set上进行LoRA微调和全参微调。通过二元交叉熵损失函数,模型能够迅速学习到真实图像与生成图像之间的差异,为后续的SFT和DPO阶段提供基础的视觉能力。
监督微调(SFT)阶段:保持视觉专家参数冻结,仅训练线性投影层和语言模型的LoRA适配层。通过使用自回归文本损失函数,引导模型学习生成与图像真实性相关的视觉缺陷解释。这一阶段的训练数据包含大量经过自动标注的图像描述和视觉缺陷解释,使模型能够建立视觉特征与语义解释之间的关联。模型在此阶段学习如何将视觉专家的检测结果转化为人类可理解的文本描述。
直接偏好优化(DPO)阶段:团队从构建的偏好数据集中采样优质和劣质解释对,采用DPO损失函数进行优化。在此过程中,团队保持视觉专家参数不变,微调线性层,并使用LoRA微调语言模型。通过偏好样本对之间的对比,模型能够区分高质量的专业解释和低质量的机械式回答,从而显著提升输出的可读性和准确性。
推理阶段:在推理阶段,团队采用了协同解码策略,将多模态大语言模型(MLLM)与预训练的视觉专家相结合来共同判断图像真实性。具体而言,通过调整模型输出中”fake”和”real”对应token的logit值,整合了原始MLLM预测、CLIP视觉专家预测和NPR视觉专家预测三方面的结果,其中权重分配分别为1:1:0.2。这种协同机制既保留了MLLM的多模态理解能力,又通过视觉专家的低层级特征分析弥补了MLLM可能存在的过拟合问题,从而提升了模型在未知领域的检测准确率。
团队对模型进行了检测能力、解释能力、鲁棒性三方面的评估,从而全面反映模型在AI生成图像检测的综合性能。
检测能力评估
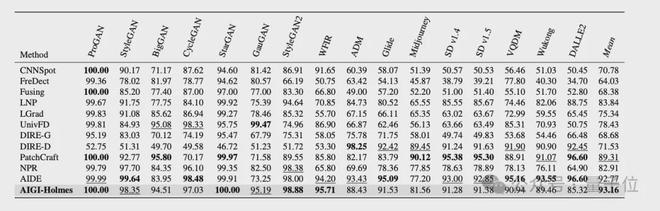
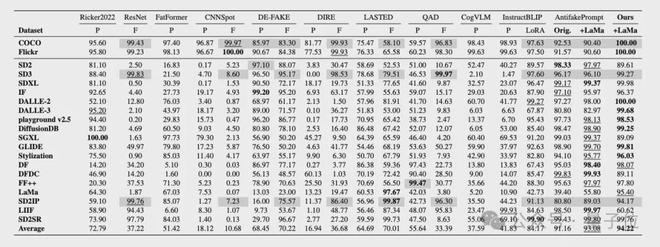
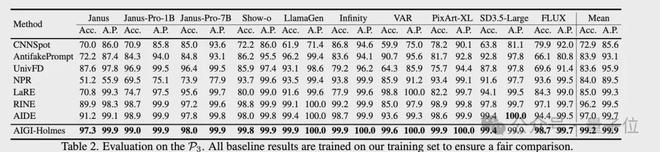
在检测能力评估上,参考现有方法,团队采用检测real/fake的准确率(Acc.)和平均精度(A.P.)作为核心指标。
具体来说,团队在三个AIGI检测的数据集上评估了检测能力,包括AIGCDetect-Benchmark、AntiFakePrompt,并且额外采集了10种SOTA生成模型的图片构建了第三个benchmark,用于测试模型在未见过的生成方法上的泛化能力。
测试结果如下图所示,相比现有方法,AIGI-Holmes在所有benchamrk上,均取得了最优效果。
解释能力评估
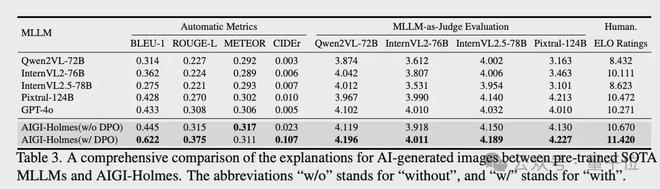
在解释能力评估上,通过BLEU、CIDEr、METEOR和ROUGE等自然语言处理指标量化解释文本的质量。此外,还引入多模态大模型评分和人工偏好评估两种补充评估方式:前者参考相关研究设计评分标准,考察解释的相关性、准确性等维度;后者通过100张测试图像的成对比较,采用ELO评分机制评估模型解释的人类偏好程度。
解释能力评估上,该方法在客观指标(BLEU/ROUGE/METEOR/CIDEr)以及大模型/人类主观评分上,相比当前先进大模型,均取得了最优效果。
鲁棒性
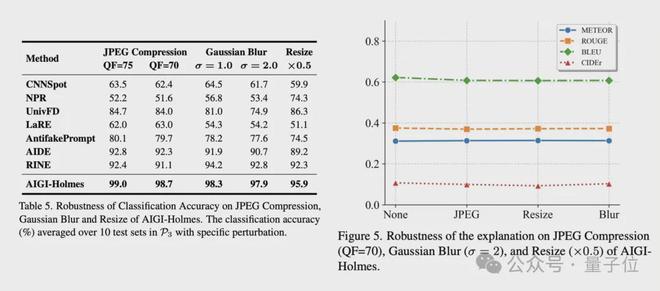
在现实场景中,AI生成的图像在传播过程中常遇到不可预测的扰动,这可能导致现有AI检测器失效。团队应用了几种现实场景中常见的扰动:JPEG压缩、高斯模糊和下采样。
如表5(下图左侧)所示,在这些失真下,所有方法的性能显著下降。然而,AIGI-Holmes在这些挑战性场景中与其他基线方法相比,实现了更高的检测精度。
此外,如图5(下图右侧)所示,在这些退化条件下,模型解释的评价指标(如BLEU-1、ROUGE-L、METEOR和CIDEr)没有表现出显著下降。这表明模型生成的解释仍然专注于与图像内容相关的高级语义信息,并且不受这些退化条件的影响。
实测效果

尽管AIGI-Holmes在检测能力、解释能力和鲁棒性上均取得了先进效果,但仍存在一些局限性,比如:
幻觉问题,模型会输出一些并不存在的视觉缺陷或将正常视觉特征误解为视觉缺陷,导致错误的解释。
随着生成模型的不断发展,视觉缺陷会越来越少,对模型在更细粒度缺陷上的视觉感知能力要求更高。
对于视觉缺陷解释,仍缺少定量客观指标评估,当前采用的人工/大模型等主观评估方法开销相对较大。
团队表示,未来也会针对多模态大模型的幻觉问题、细粒度理解能力、解释的客观评估开展进一步的工作。
代码仓库:
https://github.com/wyczzy/AIGI-Holmes
论文地址:
https://arxiv.org/pdf/2507.02664