炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
(来源:DeepTech深科技)
丰田研究院(TRI,Toyota Research Institute)近日发布了一项关于大行为模型(LBMs,Large Behavior Models)研究成果,这项技术或有望给机器人的学习方式重大变革。研究显示,通过预训练的 LBMs,机器人可以在学习新任务时减少高达80% 的数据需求,单一模型能够掌握数百项不同的操作技能。相关论文以《大行为模型多任务灵巧操作的细致检验》(A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation)发表在arXiv上。
 图丨相关论文(来源:arXiv)
图丨相关论文(来源:arXiv)研究的作者之一,丰田研究院副总裁、美国麻省理工学院教授 Russ Tedrake 在社交媒体上表示:“LBMs 确实有效!随着预训练数据量的增加,我们看到了一致且具有统计学意义的改进。”
 图丨相关推文(来源:X)
图丨相关推文(来源:X)传统的机器人训练方法存在诸多限制:每个任务都需要单独编程,学习过程缓慢且不一致,往往局限于狭窄定义的任务和高度受限的环境。相比之下,LBMs 采用了类似于大语言模型(LLMs,Large Language Models)的架构思路,但专门针对机器人的物理操作行为进行优化。
TRI 此次研究采用的 LBM 架构,是一种基于扩散模型和 Transformer 的复杂神经网络。它能够整合来自多路摄像头(包括机器人手腕和场景摄像头)的视觉信息、机器人自身的姿态和位置等本体感知数据,以及人类通过自然语言下达的任务指令。这个多模态系统通过学习,直接输出机器人需要执行的一系列连贯、精确的动作指令。具体来说,这些模型能够一次性预测未来 16 个时间步(约 1.6 秒)的动作序列,从而实现平滑而具有预见性的操作。
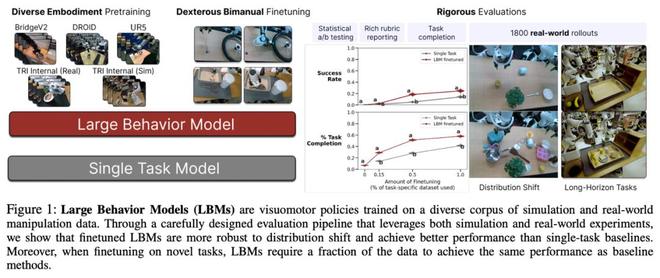 (来源:arXiv)
(来源:arXiv)为了验证 LBMs 的有效性,研究团队在近 1,700 小时的机器人演示数据上训练了多个 LBMs,这些数据包括 468 小时的内部收集双臂机器人遥操作数据、45 小时的仿真收集遥操作数据、32 小时的通用操作接口(UMI,Universal Manipulation Interface)数据,以及约 1,150 小时从 Open X-Embodiment 数据集中精选的互联网数据。
在评估环节,研究团队进行了 1,800 次真实世界评估试验和超过 47,000 次仿真试验,覆盖 29个不同任务。为确保结果的可靠性,他们采用了盲测 A/B 测试方法,并建立了新的统计评估框架来确保跨不同任务和设置的结果置信度。
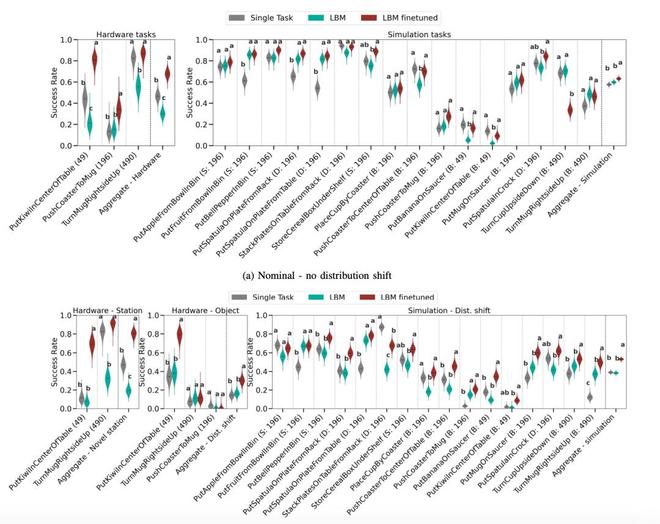 (来源:arXiv)
(来源:arXiv)研究中使用的硬件平台基于 Franka Panda FR3 机械臂的双臂操作系统,配备多达六个摄像头——每个手腕最多两个,以及两个静态场景摄像头。在感知层面,模型使用预训练的 CLIP 视觉变换器提取图像特征,并通过 CLIP 文本编码器处理任务描述的语言特征。这些视觉和语言特征与本体感受信息以及扩散时间步编码相结合,形成观察特征。
在动作生成方面,LBMs 采用去噪扩散隐式模型(DDIM,Denoising Diffusion Implicit Models)来生成连续的机器人动作。通过 K 步迭代去噪过程,从高斯噪声样本开始,逐步生成精确的动作序列。
研究得出了三个关键发现。首先,微调后的 LBMs 在已见任务上的表现始终优于单任务基线模型。在名义条件和分布偏移条件下,无论是在仿真还是真实世界环境中,微调的 LBM 都表现出统计学上的显著优势。
其次,LBMs 展现出更强的鲁棒性。当引入分布偏移时,虽然整体任务性能有所下降,但微调的 LBMs 比从零开始训练的策略表现出更强的适应能力。在仿真环境中,LBMs 在分布偏移条件下统计上优于单任务策略的比例从名义条件下的 3/16 提升到 10/16。
第三,也是最重要的发现是,LBMs 能够显著减少学习新任务所需的数据量。研究表明,要在仿真中达到相似的性能水平,需对 LBM 进行微调。所需的数据量不到从零开始训练所需数据的 30%。在真实世界任务中,这一优势更加明显——LBM 仅用 15% 的数据就能超越使用全部数据训练的单任务基线模型。
研究还验证了 LBM 的 Scaling Law。通过使用不同比例的预训练数据,研究人员发现随着预训练数据量的增加,模型性能稳步提升。即使在当前的数据规模下,研究人员也没有发现性能的不连续性或急剧拐点,这表明人工智能扩展在机器人学习领域同样有效。
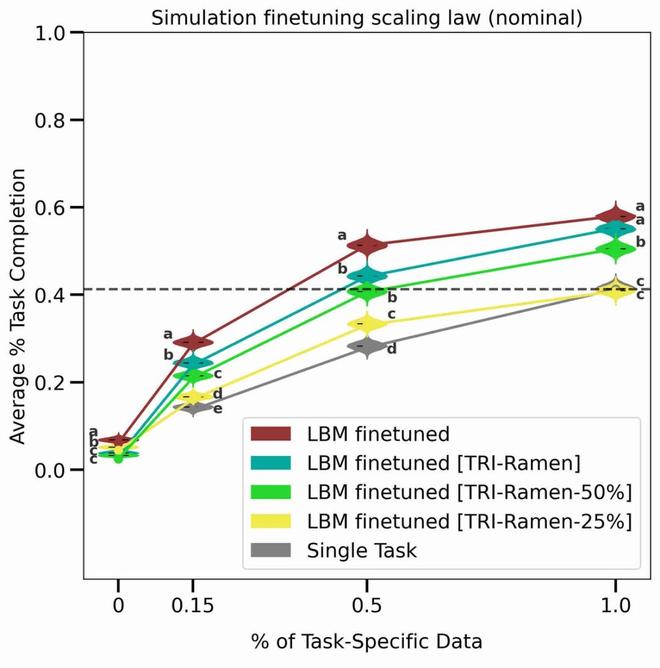 图丨LBM 上的 Scaling Law(来源:arXiv)
图丨LBM 上的 Scaling Law(来源:arXiv)为了测试 LBMs 的能力极限,研究团队还设计了多种复杂的长期任务。例如,“切苹果”任务要求机器人使用苹果取芯器给苹果去核,从器具架中取出刀具,拔出刀鞘将苹果切成两半,再将两半切成片,最后用布擦拭刀具并重新装鞘放回器具架。在这类复杂任务中,LBMs 同样展现出了优于传统方法的性能。
这项研究的一个重要贡献是强调了统计严格性在机器人学习评估中的重要性。研究团队指出,许多机器人学习论文可能由于统计功效不足而测量的是统计噪声而非真实效果。他们展示了在不同试验次数和真实成功率下的置信区间宽度:以 50 次试验为例,得到的置信区间宽度通常为 20%-30% 的绝对成功率,这使得除了最大规模的效应之外,其他效应都无法可靠测量。
为了解决这一问题,研究团队采用了贝叶斯分析方法,使用均匀 Beta 先验计算成功率的后验分布,并通过紧凑字母显示(CLD,Compact Letter Display)方法指示统计显著性。这种方法为机器人学习领域设立了新的评估标准。
研究结果表明,即使在数据规模相对较小的情况下,预训练也能带来一致的性能提升。这使得建立数据获取和性能提升的良性循环得以可能。随着更多任务被纳入预训练混合数据中,LBM 的整体性能将持续平稳改善。然而,研究也发现了一些局限性。非微调的预训练 LBMs 表现参差不齐,这部分归因于模型语言引导能力的局限性。
研究团队表示,在内部测试中,更大的视觉-语言行为原型在克服这一困难方面显示出良好前景,但需要更多工作来严格验证这一效果。此外,数据标准化等看似次要的设计选择对下游性能有重大影响,往往超过架构或算法改进的影响,提醒研究者在比较方法时需要仔细隔离这些设计选择,避免混淆性能变化的来源。
参考资料:
1.https://arxiv.org/pdf/2507.05331
2.https://toyotaresearchinstitute.github.io/lbm1/
3.https://x.com/RussTedrake/status/1942931808422875640
运营/排版:何晨龙