(来源:机器之心)

GTA 工作由中国科学院自动化研究所、伦敦大学学院及香港科技大学(广州)联合研发,提出了一种高效的大模型框架,显著提升模型性能与计算效率。一作为自动化所的孙罗洋博士生,研究方向为:大模型高效计算与优化,通讯作者为香港科技大学(广州)的邓程博士、自动化所张海峰教授及伦敦大学学院汪军教授。该成果为大模型的优化部署提供了创新解决方案。
Grouped-head latent Attention (GTA) 震撼登场!这项创新机制通过共享注意力矩阵和压缩潜在值表示,将计算量削减 62.5%,KV 缓存缩减 70%,prefill 和 decode 速度提升 2 倍。无论是处理海量数据(维权)构成的长序列任务,还是在计算资源极为有限的边缘设备上运行,GTA 都展现出无与伦比的效率和卓越的性能,无疑将成为大型语言模型优化领域的新标杆。
大型语言模型面临的效率困局
近年来,Transformer 架构的横空出世极大地推动了自然语言处理领域的飞速发展,使得大型语言模型在对话生成、文本摘要、机器翻译以及复杂推理等多个前沿领域屡创佳绩,展现出令人惊叹的能力。然而,随着模型参数量从数十亿激增至上千亿,传统多头注意力机制 (Multi-Head Attention, MHA) 所固有的弊端也日益凸显,成为制约其广泛应用和进一步发展的瓶颈。
首当其冲的是计算冗余问题。在 MHA (多头注意力) 架构中,每个注意力头都像一个独立的 “工作单元”,各自独立地计算查询 (Query)、键 (Key) 和值 (Value) 向量,这导致了大量的重复计算。特别是在处理长序列任务时,浮点运算次数 (FLOPs) 会呈平方级增长,严重拖慢了模型的处理效率,使得原本复杂的任务变得更加耗时。
其次是内存瓶颈。每个注意力头都需要完整存储其对应的键值对 (KV) 缓存,这使得内存需求随序列长度和注意力头数量的增加而快速膨胀。例如,在处理长序列时,KV 缓存的规模可以轻松突破数 GB,如此庞大的内存占用极大地限制了大型模型在智能手机、物联网设备等边缘设备上的部署能力,使其难以真正走进千家万户。
最后是推理延迟问题。高昂的计算和内存需求直接导致了推理速度的显著下降,使得像语音助手实时响应、在线翻译无缝切换等对延迟敏感的实时应用难以提供流畅的用户体验。尽管业界的研究者们曾尝试通过 Multi-Query Attention (MQA) 和 Grouped-Query Attention (GQA) 等方法来优化效率,但这些方案往往需要在性能和资源消耗之间做出艰难的权衡,难以找到理想的平衡点。面对这一系列严峻的挑战,研究团队经过不懈努力,最终推出了 Grouped-head latent Attention (GTA),以其颠覆性的设计,重新定义了注意力机制的效率极限,为大型语言模型的未来发展开辟了全新的道路。

论文标题: GTA: Grouped-head latenT Attention
论文链接: https://arxiv.org/abs/2506.17286
项目链接: https://github.com/plm-team/GTA
GTA 的核心创新机制
GTA 的卓越成功源于其两大核心技术突破,它们精妙地协同作用,使得大型语言模型即使在严苛的资源受限场景下,也能展现出前所未有的高效运行能力。
分组共享注意力矩阵机制
在传统的 MHA 架构中,每个注意力头都被视为一个独立的 “独行侠”,各自计算并维护自己的注意力分数。这种分散式的计算模式虽然赋予了模型捕捉多种复杂依赖关系的能力,但同时也带来了显著的计算冗余。以一个包含 16 个注意力头的 MHA 为例,当每个头独立处理输入时,会生成 16 组独立的注意力矩阵,这使得总体的计算开销随注意力头数量的增加而呈线性增长,效率低下。
与此形成鲜明对比的是,GTA 采用了全新的 “团队协作” 策略。该机制将注意力头巧妙地划分为若干个逻辑组,例如,每 4 个注意力头可以组成一个小组,而这个小组内部的成员将共享一张统一的注意力矩阵。这种创新的共享设计意味着,我们仅需对注意力分数进行一次计算,然后便可将其高效地分配给组内所有注意力头使用,从而大幅度减少了浮点运算次数 (FLOPs)。
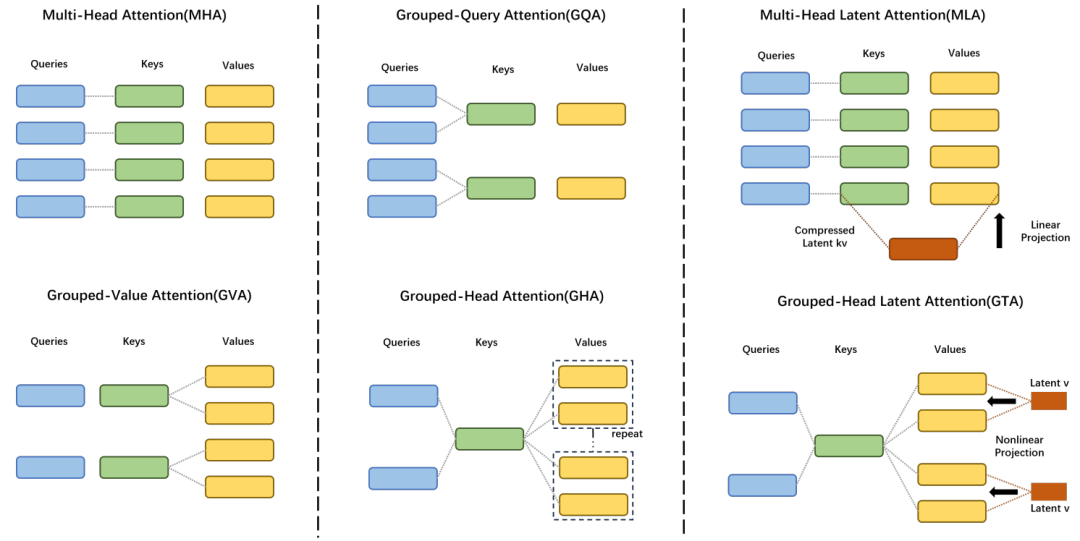
实验数据有力地证明,这一精巧的设计能够将总计算量削减,为处理超长序列任务带来了显著的推理加速效果。这恰如一位经验丰富的主厨,统一备齐所有食材,再分发给不同的助手进行精细加工,既极大地节省了宝贵的时间,又确保了最终产出的高质量和一致性。
压缩潜在值表示技术
MHA 架构的另一个关键痛点在于其 KV 缓存对内存的巨大占用。由于每个注意力头的值 (Value) 向量都需要被完整地存储下来,导致模型的内存需求会随着输入序列长度和注意力头数量的增加而快速膨胀,成为部署大型模型的严重障碍。GTA 通过其独创的 “压缩 + 解码” 巧妙设计,彻底解决了这一难题。
这项技术首先将所有注意力头的值向量高效地压缩为一个低维度的潜在表示 (Latent Representation),从而极大地减少了所需的存储空间。随后,通过一个轻量级且高效的 WaLU (Weighted additive Linear Unit) 非线性解码器,模型能够根据每一组注意力头的具体需求,从这个紧凑的潜在表示中动态地、定制化地生成所需的完整值向量。
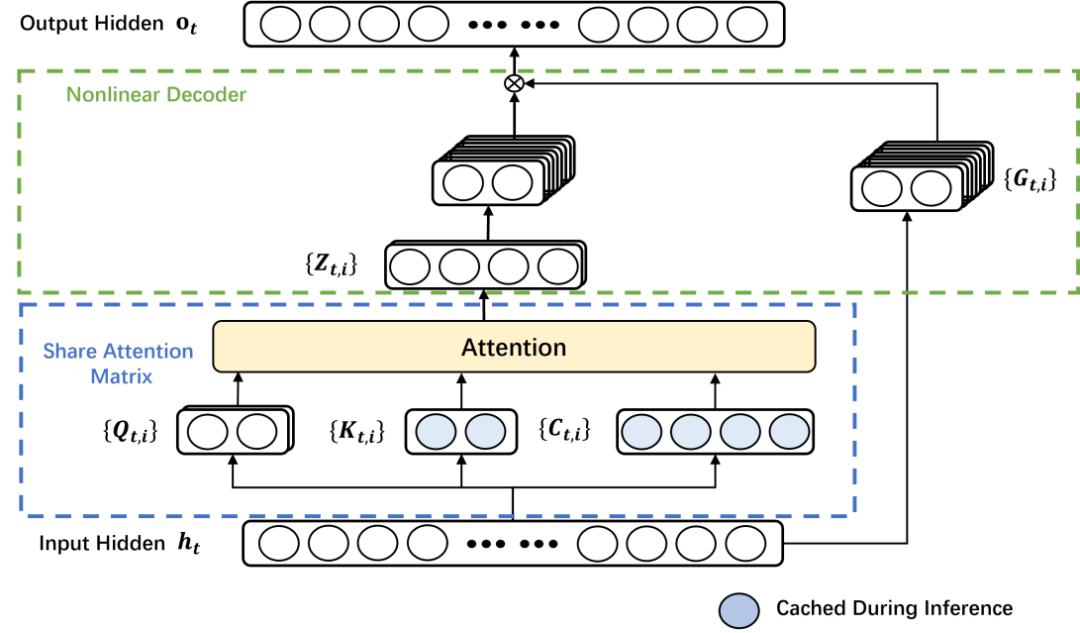
这种创新的方法不仅显著节省了宝贵的内存资源,同时还巧妙地保留了每个注意力头所特有的独特表达能力,避免了信息损失。实验结果令人鼓舞,GTA 的 KV 缓存规模成功缩减了 70%,这一突破性进展为大型语言模型在性能受限的边缘设备上的广泛部署铺平了道路,使其能够更普惠地服务于各类应用场景。
实验验证:GTA 的卓越性能与效率
研究团队通过一系列严谨而全面的实验,对 Grouped-head Latent Attention (GTA) 在不同模型规模、输入序列长度以及多样化硬件平台上的性能和效率进行了深入评估。实验结果令人信服地表明,GTA 在大幅度提升计算效率和内存利用率的同时,不仅成功保持了,甚至在某些关键指标上超越了现有主流注意力机制的模型性能,展现出其强大的实用价值和广阔的应用前景。
模型有效性验证
为了确保实验结果的公平性和准确性,研究团队在实验设计中采取了严格的控制变量法:所有非注意力相关的模型参数(例如隐藏层维度、多层感知机 MLP 的大小等)都被固定不变,从而确保模型参数量的任何变化都仅仅来源于注意力机制自身的创新设计。
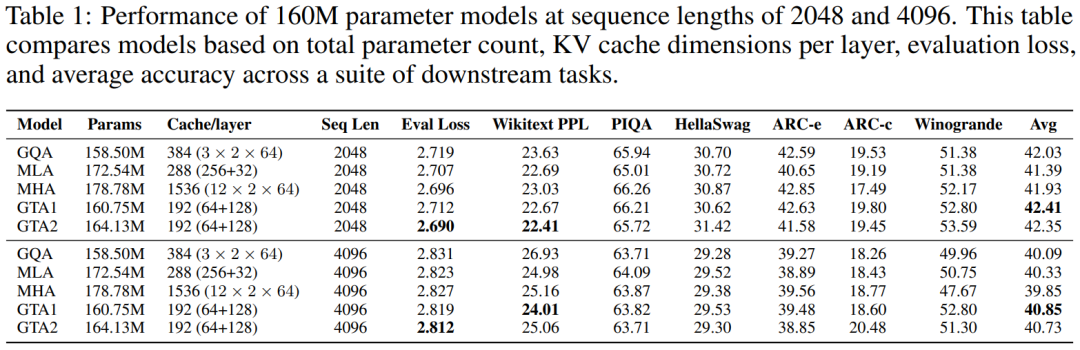
160M 参数模型表现
在针对 160M 参数规模模型的测试中,无论输入序列长度是 2048 还是 4096 个 token,GTA 都持续展现出卓越的性能优势。具体而言,采用 GTA2 配置的模型在 2048 token 序列长度下,成功实现了比传统 MHA、GQA 和 MLA 更低的评估损失,并获得了更优异的 Wikitext 困惑度(PPL)表现。此外,GTA1 配置的模型在多项下游任务中取得了更高的平均准确率,彰显了其在实际应用中的有效性。尤为值得强调的是,GTA 在内存效率方面表现出类拔萃,其每层所需的 KV 缓存大小仅为 MHA 的 12.5%(具体数据为 192 维度对比 MHA 的 1536 维度),这一显著的缩减充分突显了 GTA 在内存优化方面的强大能力。实验结果详细呈现在下方的表格中:
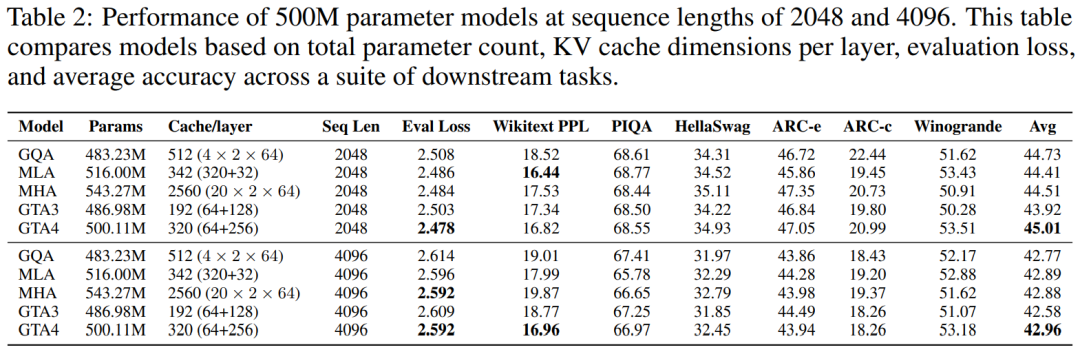
500M 参数模型表现
将模型规模扩展至 500M 参数时,GTA 依然保持了其在性能上的领先地位。在 2048 token 序列长度的测试中,GTA 不仅实现了更低的评估损失,还在下游任务中取得了更高的平均准确率,同时其 Wikitext 困惑度与 MHA 和 GQA 等主流模型保持在同等甚至更优的水平。GTA 持续展现出其独有的内存优势,其 KV 缓存大小仅为 MHA 的 12.5%(具体为 320 维度对比 MHA 的 2560 维度),即使在采用更小缓存(例如 192 维度,仅为 MHA 的 7.5%)的情况下,GTA 也能获得可比拟的性能表现,充分印证了其在内存效率与性能之间取得的完美平衡。在处理 4096 token 长序列的任务中,GTA 不仅能够与 MHA 的评估损失持平,更在 Wikitext 困惑度和下游任务的平均准确率上提供了更优异的表现。这些详尽的实验数据均已在下方的表格中列出:
1B 参数语言模型扩展性
为了进一步验证 GTA 在大规模模型上的卓越扩展能力和稳定性,研究团队特意训练了 1B 参数级别的 GTA-1B 和 GQA-1B 模型。下图清晰地展示了 GTA-1B 和 GQA-1B 在长达 50,000 训练步中的损失曲线和梯度范数曲线,从中可以观察到两者均展现出令人满意的稳定收敛趋势。

尽管 GTA-1B 在设计上采用了更小的缓存尺寸,但其损失轨迹却与 GQA-1B 高度匹配,这一事实有力地证明了 GTA 内存高效架构的有效性,即在减少资源消耗的同时不牺牲模型学习能力。在多项严苛的基准测试中,GTA-1B(包括经过 SFT 微调的版本)均展现出与 GQA-1B 相当甚至更为优异的性能,尤其在平均准确率上取得了显著提升。这充分表明,GTA 即使在资源受限的环境下,也能通过微调有效泛化到各种复杂任务,保持强大的竞争力。这些详尽的实验结果均已在下方的表格中呈现:
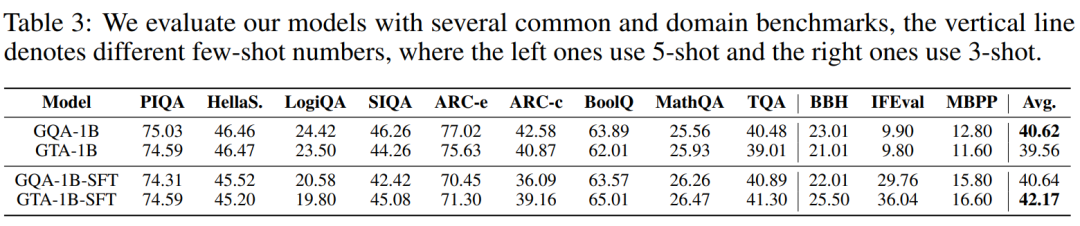
综合来看,GTA-1B 无论是在基础模型状态还是经过微调后,都成功实现了与 GQA-1B 相当的卓越性能。与此同时,其 KV 缓存尺寸仅为 GQA-1B 的 30%,而自注意力计算成本更是低至 37.5%。这些令人瞩目的数据有力地强调了内存和计算高效架构在大型语言模型扩展应用方面的巨大潜力,预示着未来 AI 发展将更加注重可持续性和资源效率。
效率评估
理论效率分析
从理论层面分析,GTA 在计算复杂度和内存使用方面均实现了显著的效率提升。其 KV 缓存尺寸从 MHA 的
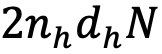
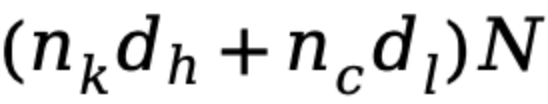
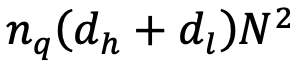
,这直接转化为推理速度的显著提升。这些严谨的理论分析和对比数据均已在下方的表格中详细列出:
显著降低到 GTA 的
,对于参数量庞大的大型模型而言,这意味着一个极其显著的缩减因子,将有效缓解内存压力。同时,注意力计算量也从 MHA 的
且
,其中
大幅减少至 GTA 的

通过 LLM-Viewer 进行经验基准测试
为了将理论优势转化为可量化的实际性能,研究团队利用 LLM-Viewer 框架,在配备 NVIDIA H100 80GB GPU 的高性能计算平台上,对 GTA-1B 和 GQA-1B 进行了全面的经验基准测试。下图清晰地展示了在不同配置下,两种模型的预填充和解码时间对比。从中可以明显看出,GTA-1B 在计算密集型的预填充阶段和 I/O 密集型的解码阶段都持续地优于 GQA-1B,充分展现了其卓越的延迟特性和更高的运行效率。
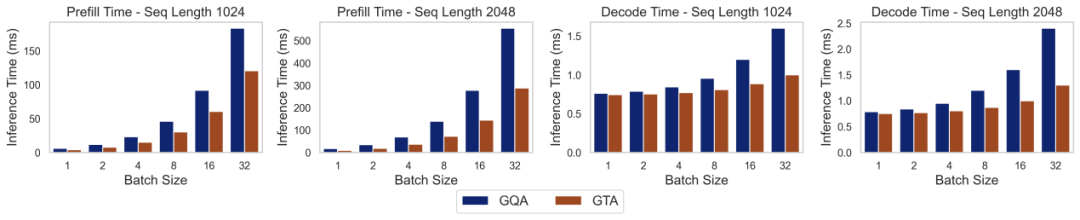
实际部署表现
为了更真实地评估 GTA-1B 在实际应用场景中的性能,研究团队利用 transformers 库,在多种异构硬件平台(包括服务器级的 NVIDIA H100、NVIDIA A800,消费级的 RTX 3060,以及边缘设备如 Apple M2 和 BCM2712)上进行了深入的推理实验。
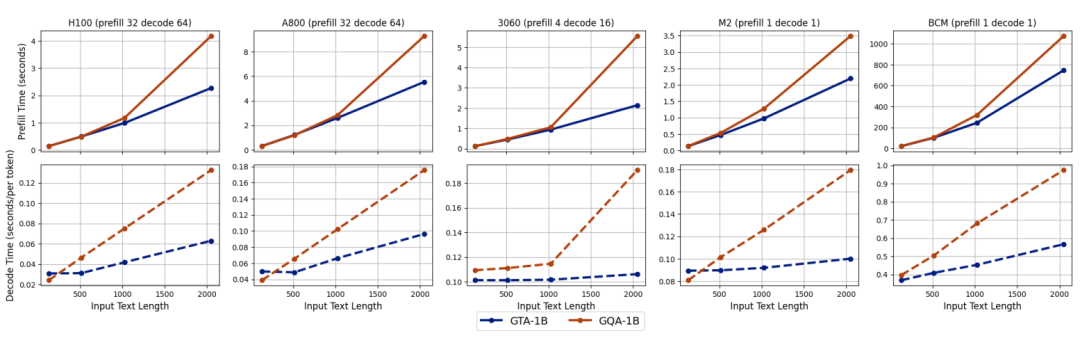
上图直观地展示了在不同配置下,GTA-1B 与 GQA-1B 的预填充和解码时间对比。GTA-1B(蓝色实线)在所有测试平台上都持续展现出优于 GQA-1B(橙色虚线)的预填充时间,尤其是在处理 2k token 等更长输入序列时,性能差距更为显著,体现了其在处理长文本时的强大优势。在解码阶段,GTA-1B 同样表现出卓越的性能,特别是在扩展生成长度时,这种优势在所有硬件类型上都保持一致,充分突显了其设计的鲁棒性。
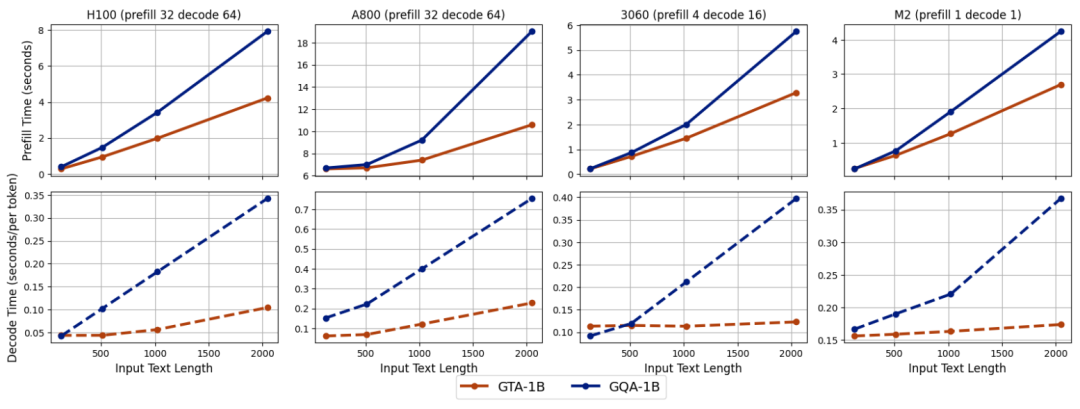
上图进一步展示了在启用缓存卸载功能时的性能表现。在 NVIDIA H100 平台上,GTA-1B 在处理更长输入序列时依然保持了其预填充优势,并且在解码时间上实现了比 GQA-1B 更大的改进。这种在所有平台上的持续趋势,有力地突显了 GTA-1B 在 I/O 密集型场景中的高效性,这类场景中缓存卸载需要 GPU 和 CPU 内存之间频繁的数据传输,而 GTA-1B 在这种复杂环境下依然表现出色。
综上所述,GTA-1B 在各种硬件平台下,无论是在预填充还是解码时间上,均全面超越了 GQA-1B,并在处理更长输入序列时展现出显著的性能优势。它不仅在标准推理设置中表现出色,在启用缓存卸载的 I/O 密集型条件下也同样杰出,充分展现了其在不同硬件能力和批处理大小下的强大多功能性。这种卓越的适应性使得 GTA-1B 成为服务器级和消费级部署的理想解决方案,通过显著降低计算复杂度和内存需求,极大地提升了大型语言模型中注意力机制的整体效率。
技术局限与未来方向
尽管 Grouped-head latent Attention (GTA) 在效率和性能方面取得了令人瞩目的突破,但作为一项新兴技术,仍有一些关键的技术挑战需要我们持续关注和深入探索。首先,非线性解码器在进行模型压缩的过程中,可能会引入微小的近似误差,这需要未来的研究在架构设计和训练策略上进一步优化,确保模型输出的准确性。其次,当前 GTA 的研究和验证主要集中在自然语言处理任务上,其在计算机视觉或多模态任务中的适用性和性能表现,还需要进行更广泛和深入的探索与验证。
尽管存在这些局限,研究团队已经为 GTA 的未来发展制定了清晰且富有前景的后续研究方向。他们计划持续改进非线性解码器的架构设计,以期在保证高效解码的同时,进一步减少信息损失,提升模型性能上限。此外,研究团队还雄心勃勃地计划将 GTA 应用于更大规模的模型,以验证其在超大规模场景下的可扩展性和效率优势,推动大型语言模型向更广阔的应用领域迈进。