炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
(来源:机器之心Pro)

本文的主要作者来自复旦大学和南洋理工大学 S-Lab,研究方向聚焦于视觉推理与强化学习优化。
先进的多模态大模型(Large Multi-Modal Models, LMMs)通常基于大语言模型(Large Language Models, LLMs)结合原生分辨率视觉 Transformer(NaViT)构建。然而,这类模型在处理高分辨率图像时面临瓶颈:高分辨率图像会转化为海量视觉 Token,其中大部分与任务无关,既增加了计算负担,也干扰了模型对关键信息的捕捉。
为解决这一问题,复旦大学、南洋理工大学的研究者提出一种基于视觉 Grounding 的多轮强化学习方法 MGPO,使 LMM 能在多轮交互中根据问题,自动预测关键区域坐标,裁剪子图像并整合历史上下文,最终实现高分辨率图像的精准推理。相比监督微调(SFT)需要昂贵的 Grounding 标注作为监督,MGPO 证明了在强化学习(RL)范式中,即使没有 Grounding 标注,模型也能从 “最终答案是否正确”的反馈中,涌现出鲁棒的视觉 Grounding 能力。
MGPO 的核心创新点包括: 1)自上而下的可解释视觉推理:赋予了 LMMs 针对高分辨率场景的 “自上而下、问题驱动” 视觉搜索机制,提供可解释的视觉 Grounding 输出; 2)突破最大像素限制:即使因视觉 Token 数受限导致高分辨率图像缩放后模糊,模型仍能准确识别相关区域坐标,从原始高分辨率图像中裁剪出清晰子图像用于后续分析; 3)无需额外 Grounding 标注:可直接在标准 VQA 数据集上进行 RL 训练,仅基于答案监督就能让模型涌现出鲁棒的视觉 Grounding 能力。


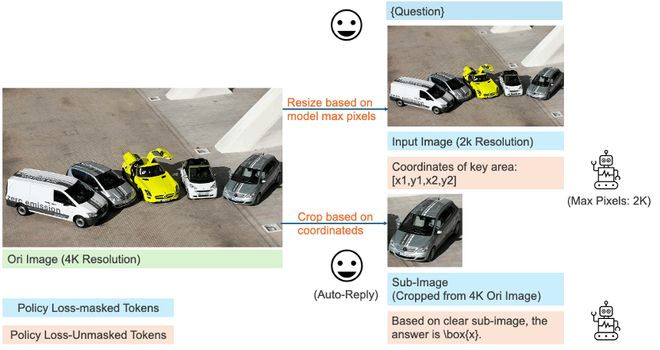
图 1:基于 MGPO 训练的模型性能展示,在处理高分辨率图像时,模型会根据问题输出关键区域坐标,然后自动触发图像裁剪函数,返回清晰的子图帮助模型回答问题。
介绍
当前,以 Qwen2.5-VL 为代表的多模态大模型(LMMs)通常基于强大的语言模型(如 Qwen2.5)结合外部原生分辨率视觉 Transformer(NaViT)构建。然而,这类模型在处理高分辨图像任务时面临挑战:高分辨率图像会转换成海量视觉 Token,其中大部分与任务无关,既增加了计算负担,也干扰了模型对关键信息的捕捉。
相比之下,在处理高分辨率真实场景时,人类视觉系统会采用任务驱动的视觉搜索策略,首先定位,再仔细审视关键兴趣区域。受这一生物机制启发,我们尝试通过视觉 Grounding 为 LMMs 赋予类似的视觉搜索能力,使其聚焦于图像中的关键区域。
但传统视觉 Grounding 模型需依赖大量 Grounding 标注进行训练,而此类标注成本较高。有没有可能不需要额外 Grounding 标注,仅通过最终答案的正确性对模型进行奖励,就让模型自动学会 “找重点”?
我们的答案是:可以。本文提出基于视觉 Grounding 的多轮强化学习算法 MGPO(Multi-turn Grounding-based Policy Optimization),使 LMMs 能在多轮交互中自动预测关键区域坐标、裁剪子图像并整合历史上下文,最终实现高分辨率图像的精准推理。我们的实验证明,即使没有任何 Grounding 标注,模型也能从 “最终答案是否正确” 的奖励反馈中,涌现出鲁棒的视觉定位能力
方法概览
MGPO 的核心思想是模拟人类的多步视觉推理过程:给定高分辨率图像和问题,模型先预测关键区域的坐标,裁剪出子图像;再结合原始图像和子图像的上下文,进行下一步推理。
下图比较了 MGPO 与 SFT、GRPO 的区别,MGPO 可以仅靠正确答案的监督信息,涌现鲁棒的视觉 Grounding 能力。

解决 “冷启动”:固定两回合对话模板
在实际训练中,我们发现 LLMs 在 Rollout 过程中,难以自主在中间过程调用 Grounding 能力,使得 RL 训练过程缓慢。为了解决模型的冷启动问题,我们设计了一个固定两轮对话模板(如下图所示),在第一轮对话中明确要求模型只输出与问题相关的区域坐标,在第二轮对话中再要求模型回答问题。

处理高分辨率:坐标归一化与子图像裁剪
受限于模型能够处理的视觉 Token 数量,高分辨率图往往会被缩放成模糊图像,导致细节丢失。如下图所示,当处理缩放图像时,MGPO 会先定位到与问题相关的区域,再从原始图像中裁剪出清晰的子图,确保模型能够正确回答相关问题。
实验结果
1.不同范式对比
基于相同训练数据下,我们对比了 SFT、GRPO、MGPO 在两个高分辨率图像 Benchmark 的表现:MME-Realworld(In-Distribution)和 V* Bench (Out of Distribution)。实验结果显示,GRPO 相较于 SFT 并未带来显著性能提升,这与之前多模态数学任务的研究结论相反。我们推测,对于高分辨率视觉中心任务,核心挑战在于让模型感知细粒度图像细节,而非进行复杂的长链推理。
相比之下,MGPO 取得了显著提升,相比 GRPO 在 MME-Realworld、V* Bench 分别提升 5.4%、5.2%。我们还将结果与 OpenAI 的 o1、GPT-4o 在 V* Bench 上进行了对比,尽管我们的模型仅基于 7B 模型、用 2.1 万样本训练,经过 MGPO 训练的模型仍超过了这两个商业大模型。

2.RL 训练过程中视觉 Grounding 能力的涌现
我们统计了 GRPO 与 MGPO 两种 RL 框架训练过程中,模型生成的有效 Grounding 坐标比例。结果显示,MGPO 的有效比例随训练迭代呈现显著上升趋势,证明了 MGPO 仅需利用标准 VQA 数据(无需额外 Grounding 标注),就能在 RL 训练过程中自主涌现出稳定、精准的视觉 Grounding 能力。

总结
MGPO 通过多轮强化学习算法激活视觉 Grounding 能力,有效提升了多模态大模型处理高分辨率图像时的 “视觉 Token 冗余” 和 “关键信息丢失” 等问题。同时,实验证明了,相比 SFT 需要昂贵的 Grounding 标注,RL 算法可以仅通过最终答案的奖励反馈,使得模型自主涌现出鲁棒的 Grounding 能力,避免了对昂贵 Grounding 标注的依赖。