炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
(来源:字母榜)

打开字节、阿里们的多模态能力地图,每块宝藏都标着"语音”。
近期,就在阿里通义千问团队发布翻译模型Qwen-MT的同一天,字节跳动旗下的火山引擎正式对外发布了豆包·同声传译模型 Seed LiveInterpret 2.0,后者的模型在多个Benchmark测试中都获得了大幅度领先,但其实该模型的首版发布已经是去年的事了。
时隔一年,字节再次将这个模型端出来,并花大力气更新换代了一次,字节想做什么?
我们可以把时间线串联起来看:字节豆包团队于 2024 年推出了旗舰语音生成基础模型 Seed-TTS,今年1月发布了豆包 Realtime Voice Model(首个端到端语音理解与生成模型),4月开源了中英双语TTS模型MegaTTS3,1个月前则发布了豆包播客语音模型。
作为豆包多模态能力中的重要一环,字节将同声传译补足到了语音能力之中。反观阿里,去年也曾高调推出了新一代端到端语音翻译大模型 Gummy,这回在翻译能力上又进一步。如果将视野再打开,环顾国内外,我们能看到阿里巴巴、字节、科大讯飞、Grok、OpenAI、Meta都在向语音类赛道疯狂投入资源。
吸引一众AI厂商纷纷加码语音模型的背后,则是行业对新一代“语义交互”方式的竞争。
一旦突破“实时语音+实时翻译+实时输出”的技术体验屏障,其将直接打开AI产品的商业化想象空间。
譬如AI硬件。新一代AI硬件浪潮正对语音翻译技术产生着强烈的需求牵引。尤其是国内正在打响的“百镜大战”。翻译模型Qwen-MT亮相两天后,阿里在WAIC上正式推出了首款AI眼镜。字节也被爆将在年内发布自家的AI眼镜。
不同于电脑和手机等终端硬件的文字交互方式,没有键盘的眼镜,天然便适合语音交互这一新形式。不过,当下阻碍AI眼镜普及的一大难点,也恰恰在语音交互体验的不完备上。
从这个角度来说,字节和阿里对语音模型的押注,颇有点给自家AI眼镜打好前站的意思。
A
那么,语音类赛道到底正在发生着什么?豆包同传2.0表现如何?
让我们先来看看这个产品的实际能力。
同声传译已经是各种圈子内的“老需求”了,并不新鲜。不过此模型,仍然吸引了全网不小的注意。这主要在于大家通过这次模型的升级,意识到了其背后的“泛商业价值”。
这款语音模型已经能够以极低的延迟、更丝滑的效果,输出与用户音色相一致的英语翻译。一边接收源语言语音输入,一边 0 样本声音复刻用户声音,直接输出目标语言的翻译语音。
我们来试一试。字节官方提供了体验地址,登录该网址后,每日有20次体验同声翻译的机会。
我们以在WAIC2025上进行的AI教父Geoffrey Hinton的演讲为例。
该同传大模型目前仅支持中英间转录,我们先来试试中文,Hinton谈论大语言模型的一段中文翻译:
今天的大语言模型(LLM)可以看作是当年我所构建的小型语言模型的后继者,是自 1985 年以来语言技术演进中的一个重要里程碑。它们以更长的词序列作为输入,采用更复杂的神经网络结构,并在特征学习中建立了更精妙的交互机制。
正如我当初设计的小模型那样,LLM 的基本原理与人类理解语言的方式本质一致:将语言转化为特征表示,并在多个层次上对这些特征进行精密的整合与重构。这正是 LLM 在其各个神经网络层中所执行的核心任务。
因此,我们有理由说,LLM 确实在某种意义上“理解”了它们所生成的语言。
在这段视频中,你能非常清晰地听到,该语音模型对于用户输入的自然语言短句的识别能力非常强,也非常迅速。即便只是一个很短的间隔,模型也能够准确识别到,并根据这种间隔判断如何翻译。
像是下图,模型会自动根据语境,而选择不更改主语,在翻译过程中,模型会根据上下文自动判断是否需要重复主语:

除此之外,当我输入语音的同时,它也在实时克隆我的音色,当然效果称不上很好,但也确实有一些相似度。
我又测试了一段鲁迅语录,其中可能会有一些语病,你会更明显地发现该模型在同传过程中的延迟非常低。像是“有一份热,便发一份光”“无穷的远方,无数的人们”中间的简短时间非常的短,几近于连读,而模型也依然觉察出来了:
我们再来试一试Hinton的英文讲座,这回我们非常明显地发现同传模型对于音色的克隆效果大幅下降了,几乎没有相似度。但是在翻译场景下的表现,包括低延迟、准确度、自然的断句等等,依然比较好。

目前该模型主要聚焦中英文对话,这点上与 Meta 的SeamlessStreaming 等跨语种模型相比仍有差距 。Meta 在2023年12月发布 Seamlessstreaming 时,就已经能够涵盖近 100 种输入语言和 36 种语音输出语言。从"语言覆盖面"这个角度,字节确实还有很长的路要走。
除此之外,在用户体验上双方之间的差距已急剧缩小,下方是官方发布视频:
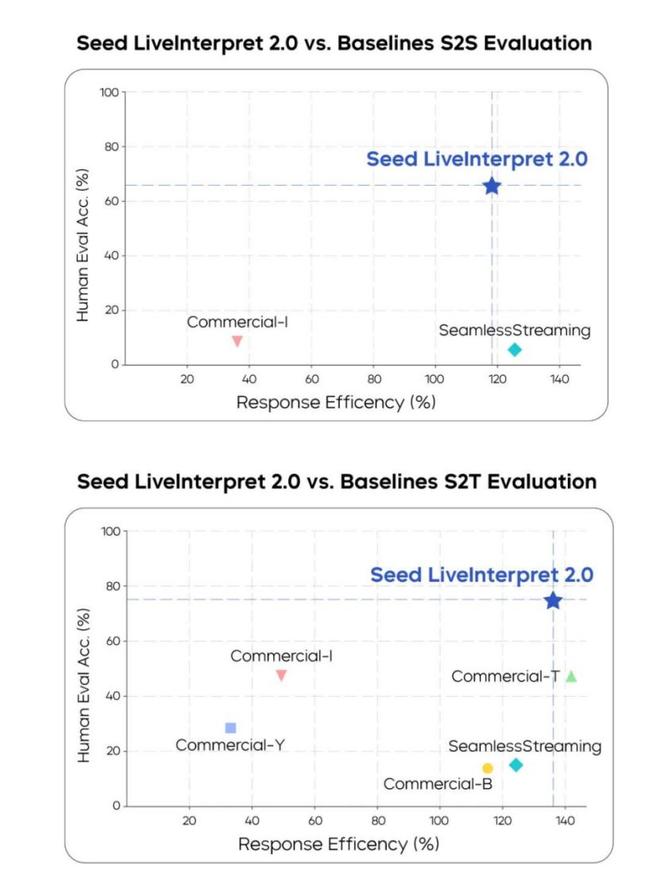
字节同步发布了基准测试成绩,Streamlessstreaming仍旧停留在这张表上,不过SeedLiveInterpret 2.0成绩很不错。中英互译平均翻译质量的人类评分达到 74.8(满分 100,评估译文准确率)
相比之下,其他大多厂商的语音同传翻译产品基本不支持实时的语音复刻,在体验上基本维持在语音输入文字输出的交互方式,我们也就不再多进行类比。
客观地说,体验下来,目前的模型技术还存在一些明显的局限。 在不同语言方向上的音色克隆表现差异较大,技术的一致性还需要改进。 对于特定领域的专业词汇,翻译准确度还有提升空间。不过,语音复刻虽然略显稚嫩,但也确实带来了更有意思的交互体感。
B
同传语音模型相对于单纯语音生成来说,难度可能已经是Next Level了。同传模型需要同时做三件事:听懂你说的话(语音识别)、翻译成另一种语言(机器翻译)、再用自然的声音说出来(语音合成)。
因此,这波字节语音翻译模型的升级并不只是为了做一个“翻译软件”。它的核心价值在于"语音交互"能力已经宣告成熟,翻译只是其中一个应用场景。
这是关于“语义交互”方式的竞争。
豆包同传模型2.0的推出,实际上是字节跳动在AI大模型生态布局中的重要一步。回顾一下时间线:早在2024年,豆包就发布了初代同传模型,但那时只能输出文字翻译结果。
当然,除了字节之外,无论是国内还是国外,几乎所有基础大模型厂商都把目光投向了语音模型这个赛道。然而,生成语音很简单,难的是“实时语音+实时翻译+实时输出”,许多大厂都正在攻坚。
比如,只谈及“纯血同传翻译”模型的话,大家自然会把目光转向阿里巴巴。在2024年云栖大会上,阿里高调推出了新一代端到端语音翻译大模型 Gummy,虽然无法实时语音复刻,但也可实时流式生成语音识别与翻译结果。
其在多个维度中都获得了SOTA级别的表现,翻译延迟甚至降到了0.5s以下:


"卖体验"比"卖翻译功能"要更吸引人。
同传翻译模型2.0背后,大家的关注点更多的还是在于语音类模型背后的潜力,而非垂直翻译能力,大家的兴奋点并不在于它能把中文翻译成英文有多准确。
如果,我们继续将目光放宽一点,会发现专攻语音交互模型赛道的选手,已经遍布整个市场了,它们正在从各个角度撬动用户应用场景。
像是最近,在舆论场和资本场拿回一点声量的“AI六小龙”之一—— MiniMax,也不甘示弱连续发布了MiniMax-Speech系列模型,特别是2025年5月推出的 Speech-02 模型,号称是"全球第一的TTS语音模型"。
其在社交场上获得声量并引起关注的原因,追其根本,在于它单次输入支持 200K 字符,支持 30 多种语言,拥有超逼真的语音克隆体验。
OpenAI的高级语音模式就更不用提了,如果你翻看各种社媒产品,就会发现几乎所有领域的用户都在抱怨“Plus用户的语音限额有点少的可怜”,这说明低延迟、实时语音、拟人性的需求非常高。
只不过,OpenAI做产品确实有点慢,尚未将手伸向一些明确的应用场景,不过倒是投了一批初创企业。像是语言学习语音交互平台 Speak,2024 年年底OpenAI曾参与其 7,800 万美元融资,并将自身语音技术模型融入进去,现在这家公司估值已经突破 10 亿美元了。
Elon Musk也早早布局,他xAI旗下的Grok模型最近也卷入了语音赛道:7月中旬,Grok应用新增了"伴侣模式",上线了一位可互动的3D虚拟AI少女形象 Ani。这个虚拟角色可以用甜美的动漫嗓音与用户对话,在日本网友中迅速走红,被戏称为"AI女友"。
Grok对语音能力的意识显然要比其他大厂商超前一点,像是ElevenLabs等初创企业与Grok在脑机接口上的合作,为渐冻症患者替换声音的操作,自然而然为这类模型打了一个大大的广告。
C
多方动向背后,说明业界对于实时语音在AI产品商业化中的价值形成了共识。
首先让我们回顾下AI产品的发展轨迹,在多模态交互中,构建从“语音到语音”的闭环体验在过去两年就被认为是下一个关键目标。过去的AI产品(无论是Chatbot还是AI 硬件)更多停留在文字和图像处理层面,但在人类日常交流中,语音才是最自然、最高效的沟通方式。所以,语音交互能带给用户更好更佳更AI的体验过程,而这正好意味着一片“痛点蓝海”。
各大厂抢攻语音模型,正是为了抢占这一未来的蓝海市场,其第一步就是抢占入口。
相信从过去一年的“Chatbot”入口界面争夺战中,许多基础模型厂商都悟得了一个道理:单纯文字对话的用户体验每上升1分,背后可能是100分的模型能力提升,10000分的算力、算法、架构的投入。
因为语音交互不像搜索引擎那样存在一个绝对的入口,用户可能从任何一个点开始接触,然后逐渐习惯这种交互方式,这背后的商业价值可以说高到难以想象。
这场语音赛道的集体押注,实际上是各大厂商对未来AI应用场景的一次集体下注。
从进入2025年以来,AI硬件产品已经进入“井喷式领域”。各种形态的智能设备如雨后春笋般涌现。
从最原初的纯刚需来看,跨国出海或者是会议场景是始终绕不过的一关。各种翻译企业从机器翻译、神经网络翻译再到AI翻译,已经走过了一关又一关,商业成果进展缓慢,蛋糕做大困难。相比之下,如果实时语音同传成熟化,这种体验的商业价值是巨大的。
无论是这些硬需求,还是满足用户对于AI未来交互体验的“软需求”,都需要一个合适的载体 —— AI硬件,或许很多人对此嗤之以鼻,认为其全部是套壳产品。但现实是,新一代AI硬件浪潮对语音翻译技术产生了强烈的需求牵引。硬件产品非常能够激发市场去琢磨一个市场还存在哪些尚未被发现的隐秘机会。
同时,在国外各个主力AI模型都已经开始开发不同的收费模式时,反观国内,除了AI Agent带来了较为成体系的价格结构之外,AI基础模型厂商几乎是“一片噤声”,无人愿意提及。正如大家常说的:“光靠模型就能盈利,那是做梦”。
AI也需要一个载体。
2023年以来,从硅谷初创公司Humane推出的可佩戴显示设备 AI Pin,到国内创业团队研发的 Rabbit R1 ,年收入近1亿美金的AI录音硬件 Plaude、TicNote、再到字节推出的Ola Friend耳机,各种形态的可穿戴AI助手层出不穷。科大讯飞也推出了主打实时多语种同传功能的会议耳机和翻译耳机,AI硬件已经事实上成为了各家厂商将AI商业化的“救命稻草”。

OldFriend 这款勉强被称为AI硬件的产品,可以通过唤醒词 “豆包豆包” 激活其 AI 聊天助手豆包,从而将体验的支撑角色转移给豆包。但是,这种体验缺乏真正的颠覆性使用场景。
既然是AI硬件,还是要从AI下手。
当字节宣布同传大模型2.0发布时,同时提到了该模型将在8月迅速进入Old Friend耳机中,为其补足更多的语音交互能力。我们可以这么理解,语音翻译模型带来的"实时语音交互"体验,正在成为AI硬件产品吸引用户的新战场。
当然,在语音这个大领域内,还存在其他分支赛道。比如字节、MiniMax前段时间都火出圈的AI播客功能,以及专注情感陪伴的语音AI产品。各家AI创业公司正在疯狂挖掘语音交互的潜力,大家逐渐发现了AI产品发展下半程的"引爆点"——语音交互市场。
此次字节豆包同传模型的发布、官方迅速宣布该模型将立刻接入硬件,以及前段时间字节投入大力气打造的播客模型等等,都在宣告着国内“语音”市场的潜力才刚刚展现。
“抢占下一代AI产品交互入口之前,先把硬件造出来”是国内普遍信奉的朴素商业道理。在此之上,AI厂商们在看到不断有初创企业通过“较差”或者只是开源的AI大模型技术就已经能发掘出这么多应用场景了,肯定会扪心自问:我何乐而不为呢?
尤其是AI实时语音交互赛道,尚且没有将这项体验完整融合到硬件市场的产品出现。作为拥有AI原生技术的字节——这个大厂的标杆之一,开始认真考虑:语音交互很可能成为下一个改变人机交互方式的关键技术。