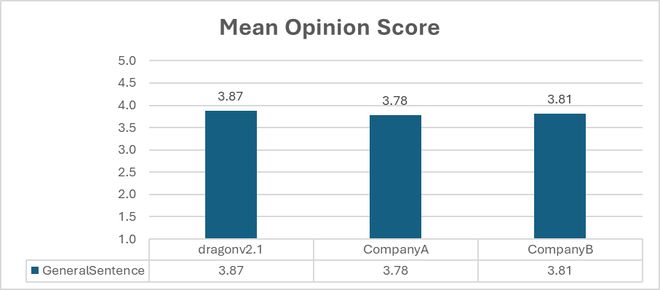
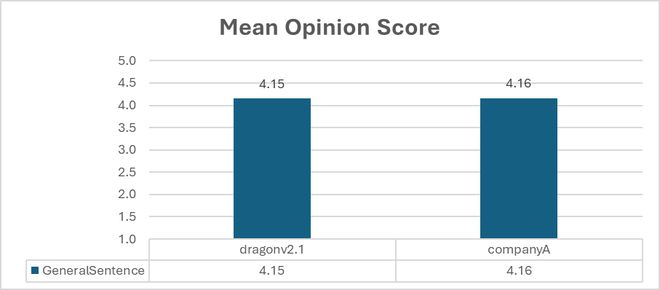
该模型还提升了声音的自然度,用户使用此模型时,可以利用 SSML 音素标签和自定义词典对发音和口音进行细致控制。为了帮助用户入门,微软构建了 Andrew、Ava 和 Brian 等多个声音档案,供用户测试。
海量资讯、精准解读,尽在新浪财经APP
Disclaimer: Investing carries risk. This is not financial advice. The above content should not be regarded as an offer, recommendation, or solicitation on acquiring or disposing of any financial products, any associated discussions, comments, or posts by author or other users should not be considered as such either. It is solely for general information purpose only, which does not consider your own investment objectives, financial situations or needs. TTM assumes no responsibility or warranty for the accuracy and completeness of the information, investors should do their own research and may seek professional advice before investing.