
编译 | 陈骏达
编辑 | 云鹏
智东西8月11日报道,近日,智谱发布了其最新一代旗舰模型GLM-4.5的完整技术报告。GLM-4.5融合了推理、编程和智能体能力,并在上述场景的12项基准测试中,综合性能取得了发布之际的全球开源模型SOTA(即排名第一)、国产模型第一、全球模型第三的成绩,发布后不到48小时,便登顶开源平台Hugging Face趋势榜第一。
智东西此前已对GLM-4.5的能力进行了介绍与测试,在技术报告中,智谱进一步分享了这款模型在预训练、中期训练和后训练阶段进行的创新。
GLM-4.5借鉴了部分DeepSeek-V3架构,但缩小了模型的宽度,增加了模型深度,从而提升模型的推理能力。在传统的预训练和后训练之外,智谱引入了中期训练,并在这一阶段提升了模型在理解代码仓库、推理、长上下文与智能体3个场景的性能。
后训练阶段,GLM-4.5进行了有监督微调与强化学习,其强化学习针对推理、智能体和通用场景分别进行了训练,还使用了智谱自研并开源的基础设施框架Slime,进一步提升了强化学习的效率。
在多项基准测试中,GLM-4.5与DeepSeek-R1-0528、Kimi K2、OpenAI o3、Claude 4 Sonnet等头部开闭源模型处于同一梯队,并在部分测试中取得了SOTA。

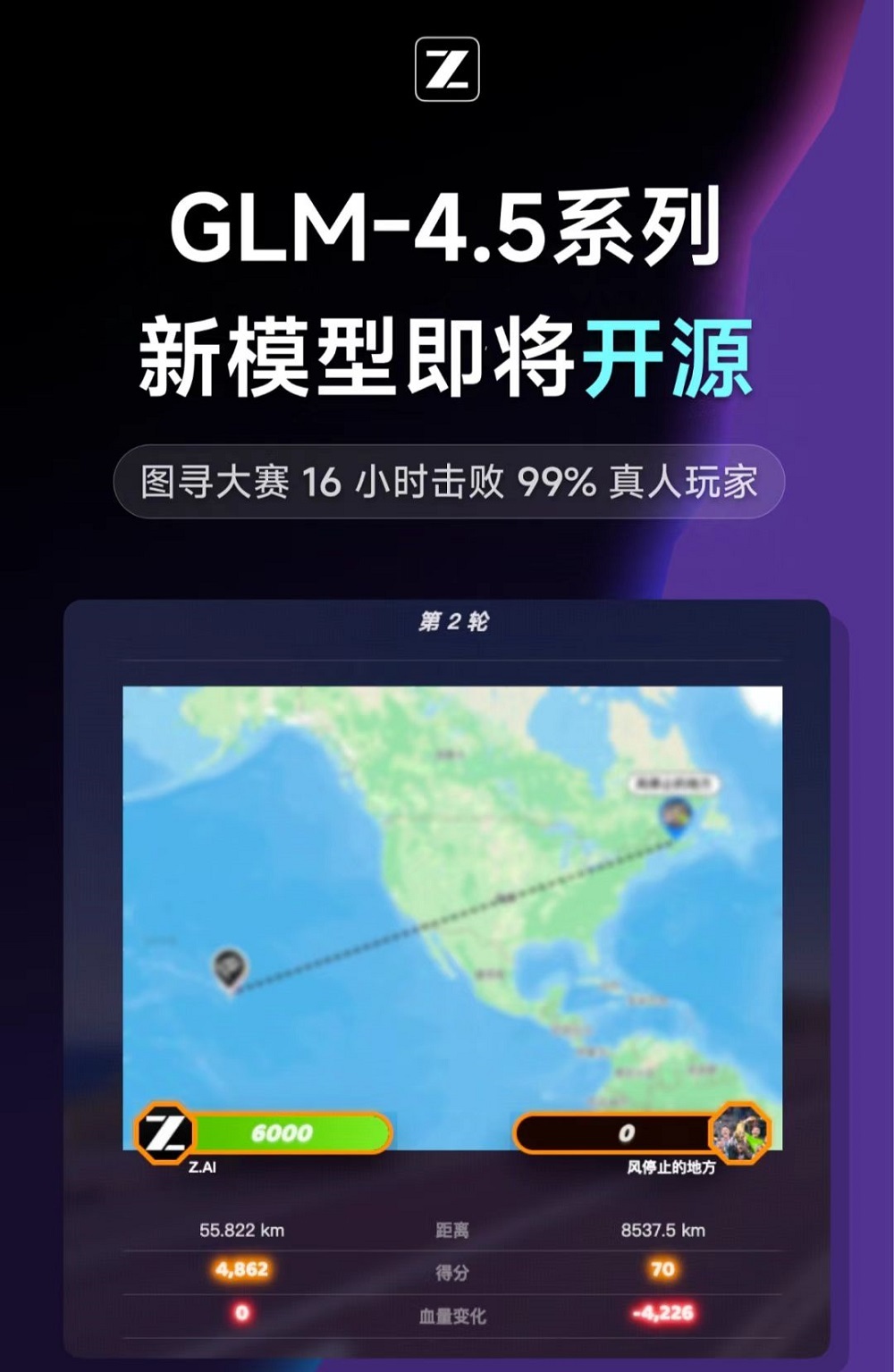
值得一提的是,智谱还计划在今晚开源GLM-4.5系列的新模型,名为GLM-4.5V,或为一款视觉模型。
论文链接:
https://github.com/zai-org/GLM-4.5/blob/main/resources/GLM_4_5_technical_report.pdf
以下是对GLM-4.5技术报告核心内容的梳理:
一、从知识库到求解器,“ARC”成新一代模型重要能力
GLM-4.5团队提出,大模型正逐渐从“通用知识库”的角色,迅速向“通用问题求解器”演进,目标是实现通用人工智能(AGI)。这意味着,它们不仅要在单一任务中做到最好,还要像人类一样具备复杂问题求解、泛化能力和自我提升能力等。
智谱提出了三项关键且相互关联的能力:Agentic能力(与外部工具及现实世界交互的能力)、复杂推理能力(解决数学、科学等领域多步骤问题的能力)、以及高级编程能力(应对真实世界软件工程任务的能力),并将其统称为ARC。
要具备上述能力,数据是基础。GLM-4.5的预训练数据主要包含网页、多语言数据、代码、数学与科学等领域,并使用多种方法评估了数据质量,并对高质量的数据进行上采样(Up-Sampling),即增加这部分数据在训练集中的出现频率。
例如,代码数据收集自GitHub和其他代码托管平台,先进行基于规则的初步过滤,再使用针对不同编程语言的质量模型,将数据分为高/中/低质量,上采样高质量、剔除低质量,源代码数据使用Fill-In-the-Middle目标训练,能让模型获得更好地代码补全能力。对于代码相关的网页,GLM-4.5采用通过双阶段检索与质量评估筛选,并用细粒度解析器保留格式与内容。
模型架构方面,GLM-4.5系列参考DeepSeek-V3,采用了MoE(混合专家)架构,从而提升了训练和推理的计算效率。对于MoE层,GLM-4.5引入了无损平衡路由(loss-free balance routing)和sigmoid门控机制。同时,GLM-4.5系列还拥有更小的模型宽度(隐藏维度和路由专家数量),更大的模型深度,这种调整能提升模型的推理能力。
在自注意力模块中,GLM-4.5系列采用了分组查询注意力(Grouped-Query Attention)并结合部分RoPE(旋转位置编码)。智谱将注意力头的数量提升到原来的2.5倍(96个注意力头)。有趣的是,虽然增加注意力头数量并未带来比少头模型更低的训练损失,但模型在MMLU和BBH等推理类基准测试上的表现得到提升。
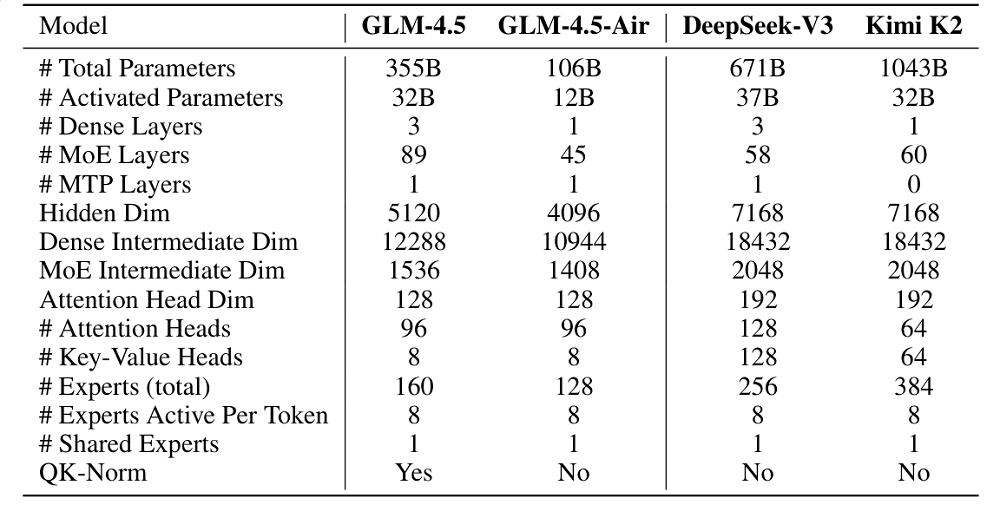
▲GLM-4.5系列模型与DeepSeek-V3、Kimi K2在架构方面的区别(图源:GLM-4.5技术报告)
GLM-4.5还使用了QK-Norm技术,用于稳定注意力logits的取值范围,可以防止注意力过度集中或过于分散,改善模型在长序列或复杂任务上的表现。同时,GLM-4.5系列均在 MTP(多Token预测)层中加入了一个MoE层,以支持推理阶段的推测式解码,提升推理速度和质量。
预训练完成后,GLM-4.5还经历了一个“中期训练”阶段,采用中等规模的领域特定数据集,主要在3个场景提升模型性能:
(1)仓库级代码训练:通过拼接同一仓库的多个代码文件及相关开发记录,帮助模型理解跨文件依赖和软件工程实际场景,提升代码理解与生成能力,同时通过加长序列支持大型项目。
(2)合成推理数据训练:利用数学、科学和编程竞赛题目及答案,结合推理模型合成推理过程数据,增强模型的复杂逻辑推理和问题解决能力。
(3)长上下文与智能体训练:通过扩展序列长度和上采样长文档,加强模型对超长文本的理解与生成能力,并加入智能体轨迹数据,提升模型在交互和多步决策任务中的表现。
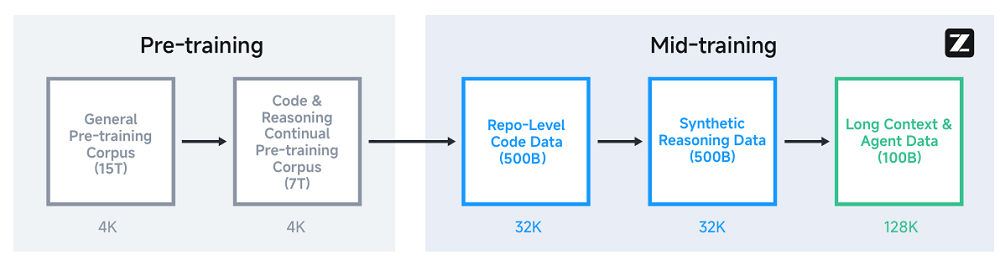
▲GLM-4.5的预训练与中期训练阶段(图源:GLM-4.5技术报告)
二、两步走完成后训练,自研开源基础设施框架立功
GLM-4.5团队将模型后训练划分为两个阶段,在阶段一(专家训练)中,该团队打造了专注于推理、智能体和通用对话这3个领域的专家模型。在阶段二(统一训练)中,该团队采用自我蒸馏技术将多个专家模型整合,最终产出一个融合推理与非推理两种模式的综合模型。
在上述两个阶段中,GLM-4.5都经历了有监督微调(SFT)。
专家训练中,SFT使用带有思维链的小规模数据集,对专家模型进行基础能力的预训练,确保模型在进入强化学习前具备必要的推理和工具使用能力。
整体SFT中,GLM-4.5利用数百万涵盖多领域任务(推理、通用对话、智能体任务及长上下文理解)的样本,基于128K上下文长度的基础模型进行训练。通过从多个专家模型输出中蒸馏知识,模型学会在不同任务中灵活应用推理,同时兼顾部分不需复杂推理的场景,支持反思和即时响应两种工作模式,形成混合推理能力。
在SFT过程中,GLM-4.5团队采用了几种方式,以提升训练效果:
(1)减少函数调用模板中的字符转义:针对函数调用参数中代码大量转义带来的学习负担,提出用XML风格特殊标记包裹键值的新模板,大幅降低转义需求,同时保持函数调用性能不变。
(2)拒绝采样(Rejection Sampling):设计了多阶段过滤流程,去除重复、无效或格式不符的样本,验证客观答案正确性,利用奖励模型筛选主观回答,并确保工具调用场景符合规范且轨迹完整。
(3)提示选择与回复长度调整:通过剔除较短的提示样本,提升数学和科学任务表现2%-4%;对难度较高的提示词进行回复长度的调整,并生成多条回复,进一步带来1%-2%的性能提升。
(4)自动构建智能体SFT数据:包括收集智能体框架和工具、自动合成单步及多步工具调用任务、生成工具调用轨迹并转换为多轮对话,以及通过多评判代理筛选保留高质量任务轨迹,确保训练数据的多样性与实用性。
SFT之后,GLM-4.5又进行了强化学习训练。推理强化学习(Reasoning RL)重点针对数学、代码和科学等可验证领域,采用了难度分级的课程学习。因为早期训练时,模型能力较弱,过难数据则会导致奖励全为0,无法有效从数据中学习。分级学习后,模型学习效率得到了提升。
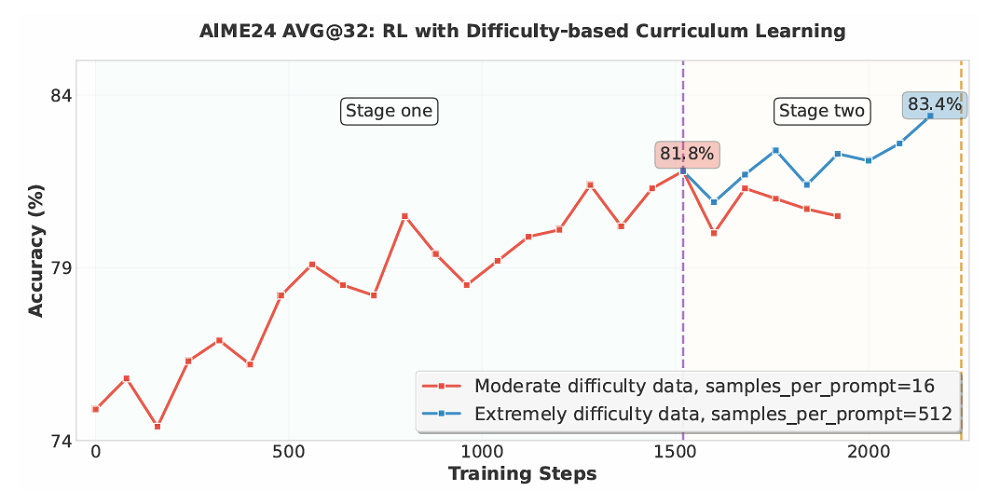
GLM-4.5模型还直接在最大输出长度(64K)上进行单阶段RL,这样能维持在SFT阶段获得的长上下文能力。智谱还发现,在编程强化学习中,损失计算方式对训练效率影响显著。采用基于token加权的平均损失比传统的序列均值损失效果更好,可提供更细粒度稳定的梯度信号,加快收敛速度,并有效缓解长度偏差和避免训练中生成过于简单重复样本。
在科学领域的强化学习中,数据质量和类型尤为关键。GPQA-Diamond基准测试显示,仅用专家验证的多选题进行强化学习,效果明显优于使用混合质量或未经验证的数据,凸显严格过滤高质量数据的重要性。
智能体强化学习(Agentic RL)则聚焦网页搜索和代码生成智能体,利用可自动验证的奖励信号实现强化学习的Scaling。为进一步提升强化训练的效率,GLM-4.5团队还采用了迭代自蒸馏提升技术,也就是在强化学习训练一定步骤或达到平台期后,用强化学习模型生成的响应替换原始冷启动数据,形成更优的SFT模型,再对其继续强化学习。
该团队还观察到,在智能体任务中,随着与环境交互轮数的增加,模型性能显著提升。与常见的使用更多token进行推理,实现性能提升不同,智能体任务利用测试时计算资源持续与环境交互,实现性能提升。例如反复搜索难以获取的网页信息,或为编码任务编写测试用例以进行自我验证和自我修正。智能体任务的准确率随着测试时计算资源的增加而平滑提升。
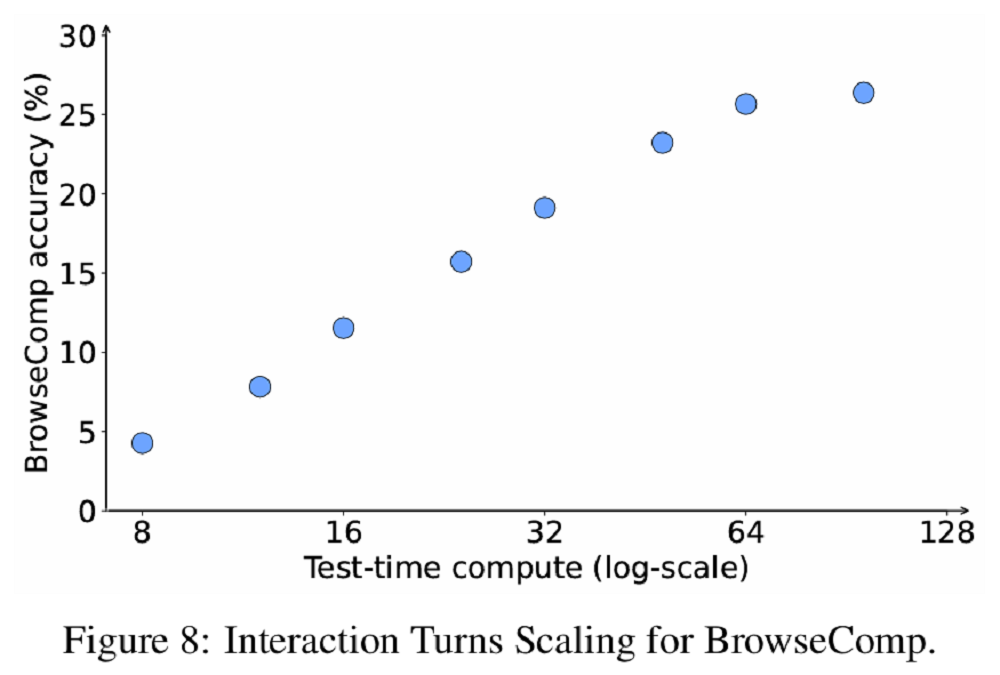
▲GLM-4.5在网页搜索智能体评测集BrowseComp上的性能,随着交互次数提升而变化(图源:GLM-4.5技术报告)
通用强化学习(General RL)融合规则反馈、人类反馈和模型反馈等多源奖励体系,提升模型整体能力。包括使用指令遵循RL,减少奖励作弊,确保稳定进步;函数调用RL分为逐步规则和端到端多轮两种方式,提升工具调用的准确性和自主规划能力;异常行为RL通过针对性数据集高效减少低频错误。
强化学习训练中,智谱使用了其自研并开源的基础设施框架Slime,针对灵活性、效率和可扩展性进行了多项关键优化。其最大特点是在同一套统一系统中,同时支持灵活的训练模式和数据生成策略,以满足不同RL任务的差异化需求。同步共置模式适用于通用RL任务或增强模型推理能力,可显著减少GPU空闲时间并最大化资源利用率。异步分离模式适用于软件工程(SWE)等智能体任务,可实现训练与推理GPU独立调度,利用Ray框架灵活分配资源,使智能体环境能持续生成数据而不被训练周期阻塞。
为了提升RL训练中的数据生成效率,GLM-4.5在训练阶段采用BF16精度,而在推理阶段使用FP8 精度进行混合精度推理加速。具体做法是在每次策略更新迭代时,对模型参数执行在线分块FP8量化,再将其派发至Rollout阶段,从而实现高效的FP8推理,大幅提升数据收集的吞吐量。这种优化有效缓解了Rollout阶段的性能瓶颈,让数据生成速度与训练节奏更好匹配。
针对智能体任务中Rollout过程耗时长、环境交互复杂的问题,该团队构建了全异步、解耦式 RL基础设施。系统通过高并发Docker运行环境为每个任务提供隔离环境,减少Rollout开销;并将GPU分为Rollout引擎与训练引擎,前者持续生成轨迹,后者更新模型并定期同步权重,避免长或多样化轨迹阻塞训练流程。此外,智谱还引入统一的HTTP接口与集中式数据池,兼容多种智能体框架并保持训练与推理一致性,所有轨迹集中存储,支持定制化过滤与动态采样,确保不同任务下RL训练数据的质量与多样性。
三、进行12项核心基准测试,编程任务完成率接近Claude
智谱对多款GLM-4.5模型的性能进行了测试。
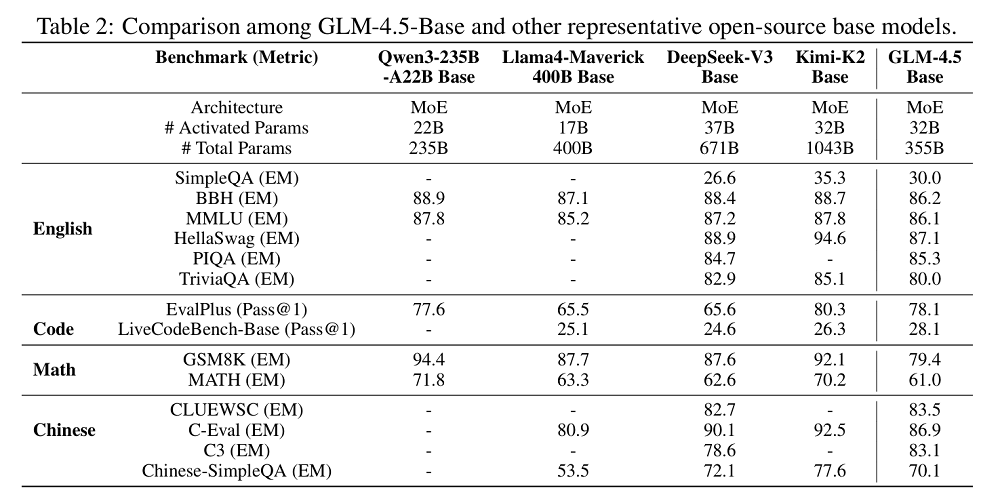
未经过指令微调的基础模型GLM-4.5-Base在英语、代码、数学和中文等不同基准测试中表现稳定,较好地融合了各领域能力。
GLM-4.5还进行了12项ARC基准测试,分别为MMLU-Pro、AIME24、MATH-500、SciCode、GPQA、HLE、LCB(2407-2501)、SWE-BenchVerified、Terminal-Bench、TAU-Bench、BFCLV3、BrowseComp。
在智能体领域,基准测试主要考查了模型调用用户自定义函数以回答用户查询的能力和在复杂问题中找到正确答案的能力。GLM-4.5在四项测试中的得分与平均分位列参与测试的模型前列,平均分仅次于OpenAI o3。
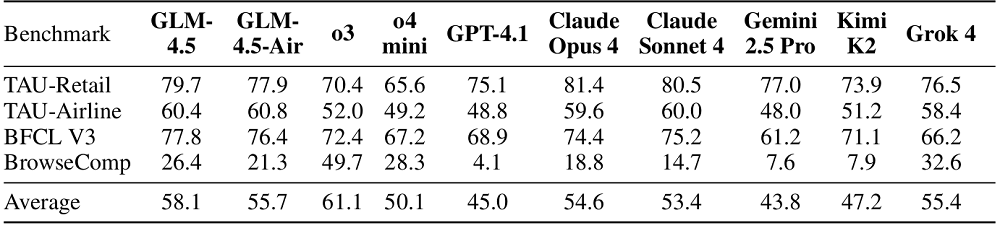
推理方面,智谱的测试集包括数学和科学知识等。GLM-4.5在AIME24和SciCode上优于OpenAI o3;整体平均表现超过了Claude Opus 4,并且接近DeepSeek-R1-0528。
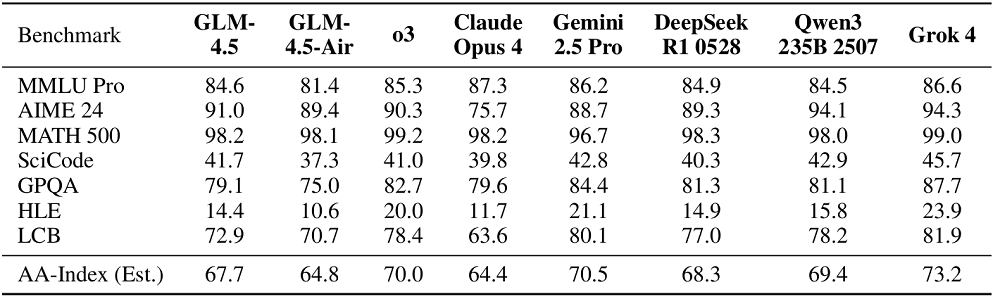
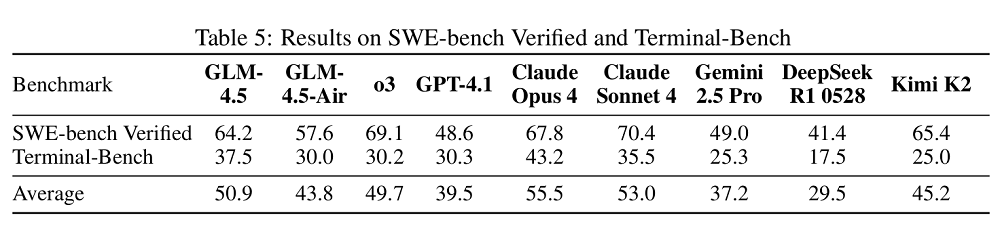
编程方面的基准测试侧重考验模型在真实世界编程任务上的能力。在SWE-bench Verified上,GLM-4.5 的表现优于GPT-4.1和Gemini-2.5-Pro;在Terminal-Bench上优于 Claude Sonnet 4。
为评估GLM-4.5在真实场景下的智能体编程能力,该团队构建了CC-Bench基准,评估主要依据任务完成率(根据预先设定的完成标准判断),若结果相同,则参考次要指标如工具调用成功率和Token消耗效率。评估优先关注功能正确性与任务完成,而非效率指标。
测试结果如下:
GLM-4.5 vs Claude 4 Sonnet:胜率40.4%,平局9.6%,败率50.0%。
GLM-4.5 vs Kimi K2:胜率53.9%,平局17.3%,败率28.8%。
GLM-4.5 vs Qwen3-Coder:胜率80.8%,平局7.7%,败率11.5%。
智谱还在技术报告中分享了GLM-4.5在通用能力、安全、翻译、实际上手体验方面的特点。
结语:中国开源AI生态蓬勃
有越来越多的企业正采取模型权重开源+详细技术报告的开源模式,这种方式不仅能让企业第一时间用上开源模型,还能让大模型玩家们从彼此的研究成果中借鉴,并获得下一次技术突破的灵感。
在DeepSeek现象之后,国内AI企业通过密集的开源,已经逐渐形成了良性的国产开源AI生态,有多家企业在其他开源模型的研究成果上完成了创新。这种集体式的创新,或许有助于推动国产大模型获得竞争优势。