炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
(来源:虎嗅APP)

出品 | 虎嗅科技组
作者 | 丸都山
编辑 | 苗正卿
头图 | 清微智能提供
在2025年的AI芯片赛道上,随便扔一板砖,能砸倒一片“英伟达学徒”。
但与此同时,也有一群人认为,英伟达构建的叙事乃至GPU这个品类本身,都到了该被颠覆重构的节点。
创办清微智能的王博,算是其中颇具代表性的一位。
“行业现在有一个绝对占据市场份额的竞品,比如英伟达或者英特尔,你是绝对不能按照它的路径走的,那会被碾压得渣都不剩。”
而王博的做法是,选择了一条与英伟达截然不同的路径——可重构芯片,一种能够动态配置计算资源的芯片。
关于这个概念,王博用一组形象的比喻解释了它和GPU的区别:后者更像是一条笔直的铁轨,火车沿着既定线路高速运行;而在可重构芯片上,重构后的计算单元让这条铁路延伸出了多个“道岔”,切换这些计算单元,即可完成多种任务的转换。
更进一步讲,可重构芯片与传统的GPU芯片是两种完全截然不同的计算范式,后者属于指令驱动+共享存储,前者属于无指令配置+数据流驱动。
以一个典型的工作场景为例,现在有两枚正在做大模型训练的GPU,其中一枚计算完数据后,需要执行指令将结果写到HBM中,随后再执行指令通过“PCIe——网卡——交换机”这条链路传到另外一枚GPU的HBM中,以此实现相互协作。
在同样的场景中,可重构芯片无需取指译码,通过无指令配置即可完成计算,并直接将数据通过自带的通信接口传给下一枚芯片,在多枚芯片计算完成后,再统一写回到外部存储器上。
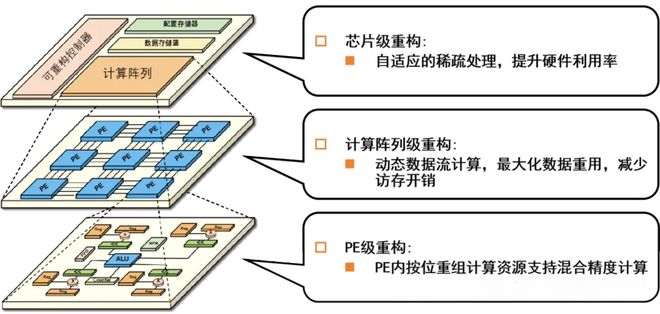 图片备注:可重构芯片架构示意图
图片备注:可重构芯片架构示意图如果对芯片架构有所了解,就会发现这已经脱离了典型的“冯诺依曼架构”。
当然,选择这个特殊的芯片架构,并非是王博刻意地回避英伟达的技术路线。因为在他将可重构芯片技术搬出实验室的2017年,人们在谈到英伟达或是GPU时,对他们的唯二印象就是“打游戏”和“挖矿”。
而在那个Transformer架构尚处于论文阶段的时候,王博也从未想过将可重构芯片同大模型联系到一起。
彼时,王博选择做可重构芯片创业的原因非常简单——此前他曾在一家云厂商担任CTO,在拓展机器视觉业务的过程中,他发现市面上几乎没有能匹配端侧,且符合强算力、性能优的芯片。
一次偶然的机会,他了解到相识多年的清华大学尹首一教授团队的可重构芯片技术已逐渐成熟。几番交谈下,两人都认为随着人工智能兴起和摩尔定律放缓,现有架构的演进无法满足算力增长需求,未来会有与AI计算更适配的架构出现。而清华团队自2006年开始一直专注可重构计算方向研究,积累的端侧、云端的技术成果已达到可以产业化的阶段。于是,两人一拍即合,在2018年共同创办了清微智能。
不过,此时的可重构芯片距离一款商业化产品,中间还隔着一条巨大的鸿沟。
“商品化的东西,需要考虑可靠性、可升级、可兼容等等,最重要的是考虑客户的需求和性价比。”王博表示。
这个过程,王博和创业团队耗费了一年半的时间。
公司成立的第二年,清微智能推出了第一枚量产的可重构芯片,那是一枚用在智能手机上的语音唤醒芯片,可好景不长,高通在下代SoC上也集成了这项功能。后续王博又带领团队转做蓝牙耳机芯片,还较具前瞻性地在这个芯片上加入了AI算力。
但王博很快意识到,蓝牙耳机芯片的需求与团队核心能力并不完全匹配。“做蓝牙耳机的SoC芯片,我们需要花大量时间去做模拟、传输、充电,这些我们并不擅长,我们最擅长的AI技术在这类芯片中只占10%,这就导致团队又遇到了技术问题”,王博解释道。
在消费电子领域两次遇阻后,王博进行了深刻复盘,最终凝练出一条感悟:
“创业,应该在擅长的领域做有挑战的事”,而在王博看来,AI正是那个能发挥可重构技术的领域。
深思熟虑下,王博决定带领团队全力攻克那些“AI占比较高”的芯片领域,先从部署在边缘端的芯片做起,之后一步步迭代至AI算力芯片。
2022年初,基于边缘端芯片的多年积累,用于云端部署的TX8系列芯片正式立项。彼时,尽管ChatGPT尚未开启公测,但王博认为,清微端侧芯片产品的成功足以证明可重构芯片的核及编译器已经趋于成熟,应该去尝试下那些“AI占比更高”的行业。
去年年底,清微AI算力芯片首枚产品“TX81”开始批量出货。短短半年,即实现了在全国多地落地千卡智算中心,累计订单超过20000枚。

在性能上,基于TX81芯片打造的REX1032训推一体服务器单机算力达4 PFLOPS,支持万亿以上大模型部署,可实现千卡直接互联,且无需交换机成本,成为了AI算力芯片领域兼具性能和性价比优势的一款产品。
面对当前市场环境,王博认为,在与英伟达等头部企业的竞争中,生态上的劣势短期内不可能逆转,因此未来至少要有“5倍性价比”优势,才能在市场中站稳脚跟。
“产品‘5倍性价比’包括性能更优、成本更低,如果做不到,很难说服客户将模型迁移到我们的产品上。”王博补充道。
据王博描述,在下一代TX8系列芯片上,清微智能还会大面积使用“3D存储”技术,以实现更高的性能,“5倍性价比”将很快得到兑现。
不过,还是要说的是,可重构芯片这项技术还算不上是清微智能的独家秘笈。
包括谷歌的TPU芯片、美国AI芯片新贵Groq、斯坦福系独角兽公司SambaNova,他们的技术路线均属于可重构数据流新架构阵营。实际上,在以英伟达主导的GPU阵营之外,新架构芯片已大有开辟第二阵营的趋势。
而对于未来可能存在的“同派之争”,王博的态度十分豁达:
“近两年那些新兴的美国创业公司,他们做3D堆叠、做晶圆级芯片、做数据流,几乎没有做GPU的,至少证明这个技术路线是没有问题的。”
以下为虎嗅与清微智能创始人王博的对话实录,略有删减:
Q:站在2017年,你为什么会看好可重构芯片?
王博:在之前的公司做机器视觉产品的时候,我们发现业内没有专用的AI芯片,都是用高通、MTK这些CPU芯片去硬跑,效率普遍都很低。正好当时看到尹老师(清华大学集成电路学院副院长尹首一)在做AI芯片,还是一个特殊的新架构,也满足我们当时做这种产品的需求。包括之前所在的公司也上市了,就跟尹老师出来一起成立了清微智能。
之所以看好可重构技术,一方面,2016年国内“AI四小龙”出现,国外特斯拉推出自动驾驶,人工智能应用到了新的高度,对人工智能的商业落地需求更明确,对芯片的需求也更确定。另一方面,2017年左右,清华两颗thinker系列芯片顺利回片,也验证了可重构的技术优势。
Q:那你做出这个判断的核心依据是什么?
王博:初衷特别简单,就是我们经过研究,还是觉得人工智能处于比较早期,所以它不仅需要低功耗,还要非常强调灵活性,这一点可重构芯片能很好地满足。那时候也有人用ASIC做加速器,但我们都觉得那个方案太短期,长期来看还是需要一个既灵活又高效的架构,所以我们就觉得可重构架构前景比较好。
Q:从定义上看,可重构芯片和FPGA有些类似,二者有什么本质区别吗?
王博:FPGA重构的是“门电路”,而我们重构的是“计算单元”。
计算单元有点类似于CPU里边的ALU(逻辑单元),你也可以把它理解成一个小的计算器,这里有成千上万个这样的计算器,要把这些计算器之间的通路连起来,它就变成了一个针对某种特殊计算的ASIC。然后这些计算机之间的连接,它就像铁路的“道岔”一样,它变了一种连接之后,就又变成一个新的ASIC了。
而且我们这个叫动态可重构,就相当于在程序运行过程中不断地重构。每执行一段程序或者神经网络的几层,就把它擦掉了,重新再配一次。然后每次配置就是十几纳秒,十几个时钟周期这样的时间。所以他是在不断地在配置重构运行这么一个过程。
Q:从实验室技术到商业化产品,你遇到的最大挑战是什么?
王博:公司要的是一个产品化的东西,它就必须要解决几个问题:
第一就是基于可重构核心外,还要做SoC的整体设计;第二要考虑产品的性价比;第三要考虑是否符合客户需求;第四还要考虑稳定可靠,可升级、可兼容等等。
这项技术从学校走出来后,2019年才把第一颗小芯片做出来,到去年才把第一颗大芯片做出来,这么长的周期,都是在不断修正和迭代这些问题。
尽管AI才是可重构技术最擅长的领域,但作为一项从实验室走向产业化的新兴技术,还是需要一步一个脚印,先从部署要求明确、验证周期较短的边缘端芯片切入,逐步积累经验,再向更高性能的AI算力芯片拓展。
Q:作为国内最早开启可重构芯片研究的公司,相信清微智能可参考的先例较少,你是如何看待这个问题的?
王博:首先,国外像谷歌这些公司,其实他们都做了七代TPU了。还有好几个创业公司已经接近上市了,说明他们已经拿到了较好的市场反馈。比如,美国AI芯片新贵Groq、斯坦福系独角兽公司SambaNova、硅谷AI芯片设计公司Cerebras Systems,他们的技术路线都属于可重构数据流新架构阵营。
另外,这个东西我觉得它是有契机的,一开始我们就相信这条路,做的过程中发现它的优势越来越明显。而且我们始终认为,在一个行业中如果你想超越那个占据绝对市场份额的竞品,比如说英伟达、英特尔,你是绝对不能跟它走同样道路的,这个就叫创新者窘境。
大公司做技术创新,可以沿着原来路径走,小公司如果也在它的路径里,那会被它碾压得渣都不剩。因为,它随便拿出一点资源,对产品的升级可能比你投入十年都大得多。所以你沿着它路径走,差距只会越来越大。
Q:但是市场上诸如博通或者Marwell这种公司,没有按照英伟达的路线走,但市场份额也没有明显提升。
王博:这个悖论就是因为定制化芯片研发成本较高,而且博通还要盈利。所以作为客户,找博通定这个芯片,那得卖出多少的量才能把这个成本摊平?我们始终认为在芯片行业,特别是算力芯片行业,定制芯片这条路是走不通的,或者说性价比是不划算的,远不如买英伟达或者其他的通用芯片。
Q:那同样都是做通用芯片,你们要如何与英伟达这类巨头竞争呢?
王博:我认为需要在产品上具备5倍性价比优势,就是从客户的角度来看,它的采购成本、运维成本要降低,最重要的是性能的提升和优化,要在同类产品中有优势,这些加起来,我们需要比竞品有5倍优势,才能在市场上分得更多的蛋糕。
Q:5倍性价比,这要如何实现?
王博:首先在可重构架构下,4000卡以内的智算中心是不需要交换机的,而且我们也不需要昂贵的HBM存储,我们可以用DDR存储代替;再有就是在下一代产品上我们会使用“3D存储”技术,这会进一步提升能效比。
Q:可是像英伟达做的GPGPU,也可以在封测端使用3D存储呀。
王博:在我们看来,3D存储这条路不太适合GPU。从芯片设计维度来说,传统GPU的计算存储布局受限于二维平面思维,而可重构数据流架构从底层就具备三维扩展的天然优势,每个计算单元上方都有对应的存储,这种空间自由度让它和晶圆级集成、3.5D堆叠等立体封装技术产生天然适配。未来,可重构芯片还是有较强的性能突破潜力。
Q:那这个搭载3D存储的下一代产品更新,我们有明确的时间线吗?
王博:预计明年下半年,我们就能交付到用户手中了。
Q:行业内经常会说英伟达在生态上的绝对领先优势,有许多国内GPU厂商也是选择主动兼容CUDA,但可重构路线从根本上就与GPU不同,在生态搭建上是否意味着需要“从零做起”?在这一过程中,清微智能做了哪些工作?
王博:我们其实是做了三层的兼容。
第一层兼容是英伟达CUDA的API兼容,像cuDNN(专为深度学习设计的库)、cuBLAS(用于线性代数运算的库)用户都可以使用,同时,我们和英伟达CUDA生态的兼容也在持续完善。
第二层就是“Triton兼容”,这也是OpenAI主推的开源编译器,行业内主流大模型厂商都在向Triton做迁移,我们也在联合智源研究院,积极参与国内Triton生态的建设工作。
第三层就是在芯片最底层,类似英伟达PTX那一层,我们做了一个比较特殊的RISC-V兼容,用户可以用RISC-V的指令集去做整个芯片的编程,目前RISC-V开源生态也比较繁荣,对于用户来说更容易进行性能极致调优。
此外,像一些主流的神经网络框架,比如PyTorch,TensorFlow等,我们也都做了完整兼容适配,保证框架上编程的用户做到无感迁移。
总的来说,我们不需要完全“从零做起”,通过拥抱开源的Triton + RISC-V生态,同时也尽量兼容CUDA,可以为不同类型的客户提供适配的使用方式。
Q:国外的一些公司,像Groq,包括刚才提到的谷歌TPU,他们都在做数据流新架构的芯片,你觉得这个技术路线未来会是算力芯片的第二阵营吗?
王博:我觉得现在就算是第二阵营了。你看近两年那些新兴的美国创业公司,他们做3D堆叠、做晶圆级芯片、做数据流,但几乎没有做GPU的,至少证明这个技术路线是没有问题的。
本文来自虎嗅,原文链接:https://www.huxiu.com/article/4697234.html?f=wyxwapp