炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
(来源:量子位)
大语言模型(LLM)正从工具进化为“裁判”(LLM-as-a-judge),开始大规模地评判由AI自己生成的内容。这种高效的评估范式,其可靠性与人类判断的一致性,却很少被深入验证。
一个最基础、却也最关键的问题是:在评判一个模型是否“入戏”之前,AI裁判能准确识别出对话中到底是谁在说话吗?
针对这一问题,上海交通大学王德泉课题组的论文《PersonaEval: Are LLM Evaluators Human Enough to Judge Role-Play?》对此进行了系统性的研究。
文章提出一个名为PersonaEval的全新基准测试。这项测试的核心任务,就是让模型在给定一段对话后,从几个候选角色中选出真正的说话者。

测试结果显示,即便是表现最好的模型Gemini-2.5-pro,其准确率仅为68.8%,而人类实验组的平均准确率为90.8%。
论文即将发表在2025年10月份的第2届语言模型大会(COLM)上。
一个让顶尖模型也“翻车”的简单问题
近来,关于大语言模型能否胜任“裁判”的讨论愈发激烈,从“隐形prompt”影响大模型审稿的争议,到斯坦福大学筹备首届纯AI学术会议Agent4Science的尝试,都标志着一个新趋势的到来:大语言模型(LLM)能当裁判评判AI生成的内容。
这一趋势在角色扮演(Role-Play)领域尤为明显。从让大模型扮演经典的文学人物、游戏NPC,到Character.AI的火爆和各类应用中“AI陪玩”的兴起,一个由LLM驱动的虚拟伴侣和内容创作时代正向我们走来。
随着其巨大的商业与应用潜力引发业界广泛关注,如何评价AI“演技”也自然成了亟待解决的核心问题。于是,让LLM来担当裁判,也顺理成章地成为了该领域的主流评估方法之一。
在AI当裁判之前,首先要确认AI是否能够准确进行“角色身份识别”(Role Identification)。作者认为,如果连这个都做不到,那么后续所有关于语气、情感、性格一致性的高级评估,都将是空中楼阁。
我们来看一个在人类眼中非常简单,但却让顶尖大模型都判断失误的例子,如下图所示:
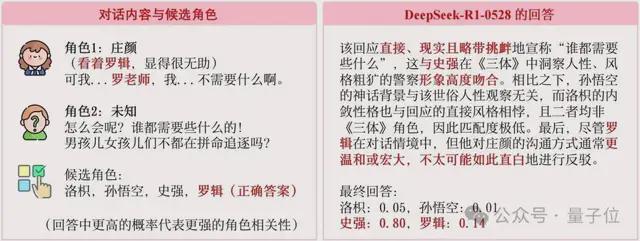 △图1 简单案例
△图1 简单案例如上图所示,角色庄颜正在与某人对话。在她的内心独白中,她明确提到了“罗辑”,同时她在话语中也提到了“罗老师”。
这个例子一针见血地指出了当前LLM裁判的致命缺陷:它们似乎更关注表层的语言风格(听起来像谁),而人类则首先观察真实的对话意图和上下文(在那个情境下,谁会这么说)。
为什么会产生这种分歧?这背后其实是AI与人类智能模式的深刻差异。
正如论文所引述的认知科学家Josh Tenenbaum的观点:LLM的智能是从海量语言中学习模式而“衍生”出来的,它们是顶级的模式匹配专家;而人类的智能则“先于”语言,我们是带着意图和认知去发展和使用语言这一工具的。
PersonaEval:一个专为LLM裁判打造的“照妖镜”
为了系统性地评估LLM在角色身份识别上的能力,论文作者精心构建了PersonaEval基准。
它有几个核心特点,确保了评估与人类对齐,以及一定的挑战性:
 △图2:PersonaEval基准的构建流程
△图2:PersonaEval基准的构建流程整个基准包含了三个不同方向的测试集:
测试发现:AI判断相较于人类还有巨大差距
在PersonaEval这个“考场”上,现有LLM的表现如何呢?结果令人震惊。
论文作者对包括GPT系列、Claude系列、DeepSeek系列在内的多个顶尖模型进行了测试。结果显示,即便是表现最好的模型Gemini-2.5-pro,其准确率也仅为68.8%。相比之下,论文作者组织了一场人类研究,由20名高学历志愿者参与,人类的平均准确率高达90.8%!
△图3:LLM在PersonaEval上的准确率与人类水平对比上图直观地展示了这条巨大的“鸿沟”(Current Gap)。这清晰地回答了论文标题中的问题:
目前的LLM裁判,还远不够“拟人”,不足以可靠地评判角色扮演。如何弥补差距?强化“推理”是关键,而非“投喂”角色知识。
既然发现了问题,那该如何解决?
论文作者进一步探索了两种常见的模型提升策略:
结果再次出人意料。研究发现,对模型进行角色相关的微调,不仅没有提升其角色识别能力,反而可能导致性能下降。这可能是因为死记硬背的角色知识干扰了模型更底层的、通用的推理能力。
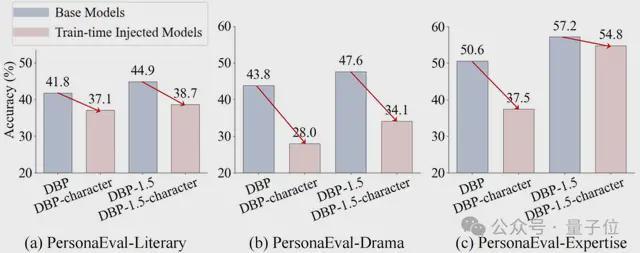 △图4:在角色数据上微调后(粉色柱),模型性能反而下降
△图4:在角色数据上微调后(粉色柱),模型性能反而下降与此同时,测试时计算的方法显示出更大的潜力,特别是那些为“推理”而生的模型,表现出了明显的优势。例如,专为推理任务优化的DeepSeek-R1和QwQ-32B等模型,在基准测试中名列前茅。
这表明,想要打造一个好的“AI裁判”,关键不在于灌输更多的角色知识,而在于提升模型本身强大、稳健、具有上下文感知能力的推理引擎。
该论文揭示了当前流行的“LLM-as-a-judge”评估范式在一个基础却被忽视的维度上的严重缺陷。
这项研究不仅为我们提供了一个宝贵的评估工具,更促使我们重新思考如何构建真正与人类价值观和判断力对齐的AI系统。
未来的研究或许可以深入分析模型做出错误判断的“思考路径”,从而开发出更有效的、以推理为导向的提升方法。PersonaEval,正在朝着这个目标迈进。
最终,我们希望AI不仅能“扮演”人类,更能真正“理解”人类的互动方式。
作者简介
论文第一作者是上海交通大学博士研究生周凌枫,主要研究大模型智能体、人工智能赋能的社会科学等方向。

论文的通讯作者为上海交通大学长聘教轨助理教授、博士生导师王德泉。本科毕业于复旦大学,博士毕业于加州大学伯克利分校,师从Trevor Darrell教授。近五年论文谷歌学术总引用次数 12000 余次,H-index 22。
项目链接:https://github.com/maple-zhou/PersonaEval
论文地址:https://arxiv.org/abs/2508.10014