炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
(来源:量子位)
大模型OUT,小模型才是智能体的未来!
这可不是标题党,而是英伟达最新论文观点:
在Agent任务中,大语言模型经常处理重复、专业化的子任务,这让它们消耗大量计算资源,且成本高、效率低、灵活性差。
相比之下,小语言模型则能在性能够用的前提下,让Agent任务的执行变得更加经济灵活

网友的实测也印证了英伟达的观点:当6.7B的Toolformer学会调用API后,其性能超越了175B的GPT-3。
7B参数的DeepSeek-R1-Distill推理表现也已胜过Claude3.5和GPT-4o。
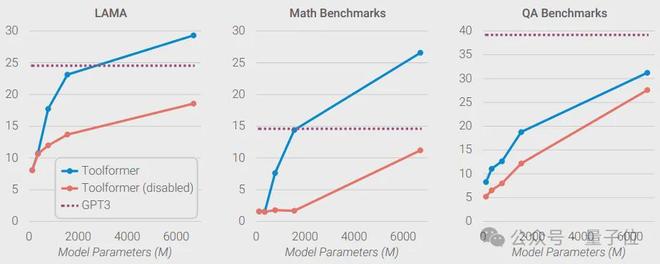
那么,小模型是如何“四两拨千斤”,放倒大模型的?
针对硬件与任务的优化
总的来说,小模型通过优化硬件资源Agent任务设计两个方面来更高效地执行Agent任务。
首先是针对GPU资源和调度的优化
由于小模型“体积”小巧的独特优势,它们可以在GPU上高效共享资源,其可在并行运行多个工作负载的同时保持性能隔离。
相应的,小巧的体积还带来了更低的显存占用,从而使得超分配机制得以可能,进一步提升并发能力。
此外,GPU资源还能根据运行需求灵活划分,实现异构负载的弹性调度和整体资源优化。
而在GPU调度中,通过优先调度小模型的低延迟请求,同时预留部分资源应对偶发的大模型调用,就能实现更优的整体吞吐与成本控制
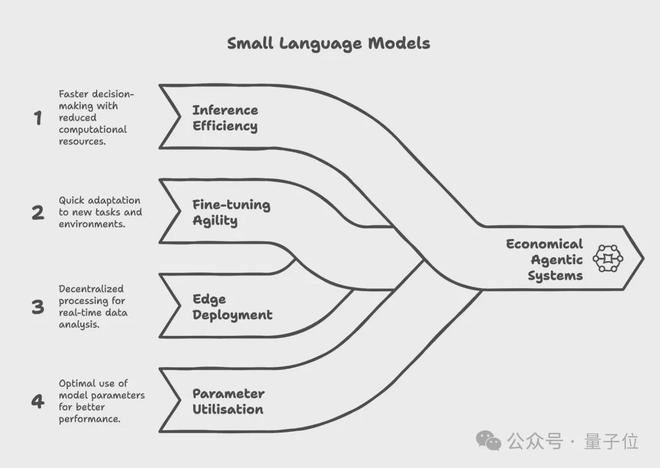
其次是针对特定任务的模型部署
在传统的Agent任务场景中,Agent依赖大模型完成工具调用、任务拆解、流程控制和推理规划等操作。
然而就像网友提到的,Agent任务往往是重复性的、可预测的、范围明确的。譬如,帮我“总结这份文档,提取这份信息,编写这份模板,调用这个工具”,这些最大公约数需求最常被拉起。
因此,在大部分需求中,往往不需要一个单一的大模型来执行简单重复的任务,而是需要为每个子任务选择合适的工具。
基于此,英伟达指出,与其让花费高企的通用大模型处理这些常见的任务,不如让一个个经过专业微调的小模型执行每个子任务。
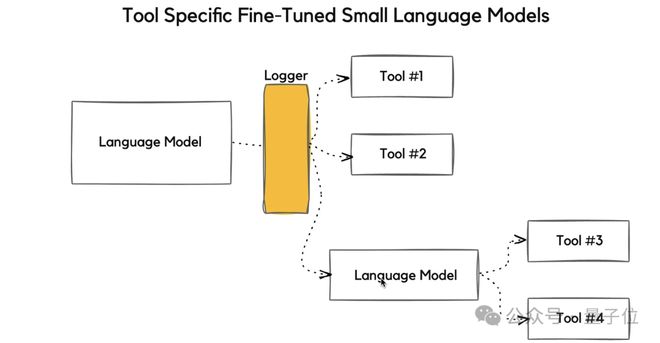
这样一来,不仅可以避免Agent任务中,大模型“高射炮打蚊子”带来的资源浪费,还可以有效地降低推理成本。
举例来说,运行一个70亿参数的小模型做推理,要比用700–1750亿参数的大模型便宜10–30倍
同时,由于小模型计算资源占用低,因而也更适合在本地或边缘部署,而大模型则更多地依赖大量GPU的并行计算,依赖中心化的云计算供应商,需要花费更多地计算成本。
此外,大模型还有“大船掉头难”的毛病,不仅预训练和微调成本远高于小模型,难以快速适配新需求或新规则,而且还无法充分利用海量参数(一次推理只激活少量参数)。
与之相对,小模型则可以在较小数据量和资源条件下完成高效微调,迭代更快,同时还能凭借更合理的模型结构和定制设计,带来更高的参数利用率
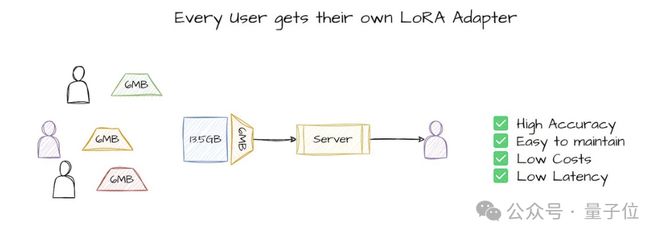
不过,也有一些研究者提出了反对的声音。
例如,就有研究者认为大模型因其规模庞大而具有更好的通用理解能力,即使在专业的任务中也表现更佳。
针对这一疑问,英伟达表示,这种观点忽略了小模型的灵活性,小模型可以通过轻松的微调来达到所需的可靠性水平 。
同时,先进的Agent系统会将复杂问题分解为简单的子任务,这使得大模型的通用抽象理解能力变得不那么重要 。
此外,还有研究者对小模型相对大模型的经济性提出了质疑:
对此,英伟达表示了部分地认同,但同时也指出:
最后,也是争议的核心——虽然小模型部署门槛正在下降,但大模型已经占先,行业惯性让创新仍集中在大模型,转型未必会真的降本增效。
这就引出了小模型在实际落地中要面临的挑战。
从大模型到小模型
英伟达表示,小模型虽然以其高效、经济的特点在特定任务中表现出了不错的潜力,但仍然需面临以下挑战:
由此看来,一种折衷的手段就变得未尝不可:
为此,英伟达给出了将大模型转换为小模型的方法:
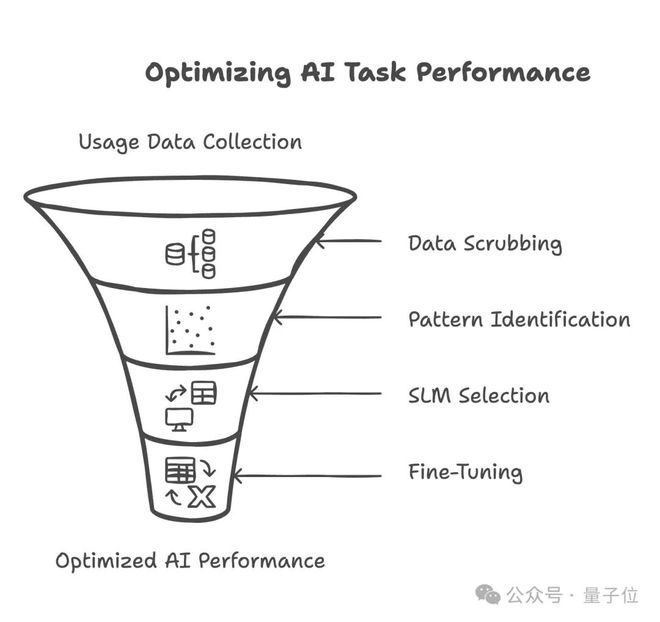
首先,通过数据采集记录当前大模型的运行数据、资源占用和请求特征,然后对数据进行脱敏处理,只保留使用模式。
接着,根据请求类型和任务结构对工作负载进行聚类,识别常见子任务。
随后,选择合适的小模型,并匹配相应的GPU分配策略。在定制数据上完成模型微调后,将其部署上线服务。
最后,构建持续反馈闭环机制,不断优化模型性能和资源利用率,实现迭代提升。
小模型vs大模型
围绕英伟达的这篇论文,网友们针对“小模型才是 Agentic AI的未来”这一观点展开了讨论。
例如,就有网友分享了自己在Amazon处理产品退款的心得,他认为在这种简单的任务中,使用小模型比使用大型语言模型更具成本效益。
就像论文里指出的,大模型在处理简单任务时,其强大的通用性往往会被浪费,因此,使用小模型更为合适。

不过,也有网友提出了反对意见。
比如,小模型因其专业性在面对偏离预设流程的情况时,可能不够鲁棒。同时,为了应对这些corner case,设计者还需要预先考虑更多的变数,而大模型在应对复杂情况时可能更具适应性。

说起来,小模型就像Unix“一个程序只做好一件事”(Do One Thing and Do It Well)的设计哲学,把复杂系统(大模型)拆成小、专一、可组合的模块(小模型),每个模块做好一件事,然后让它们协同完成更大任务。
但与此同时,系统也需要在功能多样性和操作复杂度之间作出取舍。
一方面,小模型越多,那么理论上其可以完成的任务就越丰富(功能多样性高)。
另一方面,功能越多,用户和系统操作的复杂度也会随之增加,容易导致难以理解、难以维护或错误频发,到头来可能还不如一个通用的大模型方便。
到底是“少而精”的小模型更靠谱,还是“大而全”的大模型更稳?你怎么看?
[1]https://x.com/ihteshamit/status/1957089843382829262
[2]https://cobusgreyling.medium.com/nvidia-says-small-language-models-are-the-future-of-Agentic-ai-f1f7289d9565
[3]https://www.theriseunion.com/en/blog/Small-LLMs-are-future-of-AgenticAI.html
[4]https://arxiv.org/abs/2506.02153