炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
(来源:机器之心Pro)

在机器人操作任务中,预测性策略近年来在具身人工智能领域引起了广泛关注,因为它能够利用预测状态来提升机器人的操作性能。然而,让世界模型预测机器人与物体交互的精确未来状态仍然是一个公认的挑战,尤其是生成高质量的像素级表示。
为解决上述问题,国防科大、北京大学、深圳大学团队提出LaDi-WM(Latent Diffusion-based WorldModels),一种基于隐空间扩散的世界模型,用于预测隐空间的未来状态。
具体而言,LaDi-WM 利用预训练的视觉基础模型 (Vision Fundation Models) 来构建隐空间表示,该表示同时包含几何特征(基于 DINOv2 构造)和语义特征(基于 Siglip 构造),并具有广泛的通用性,有利于机器人操作的策略学习以及跨任务的泛化能力。
基于 LaDi-WM,团队设计了一种扩散策略,该策略通过整合世界模型生成的预测状态来迭代地优化输出动作,从而生成更一致、更准确的动作结果。通过在虚拟和真实数据集上的大量实验,LaDi-WM 能够显著提高机器人操作任务的成功率,尤其是在 LIBERO-LONG 数据集上提升27.9%,超过之前的所有方法。
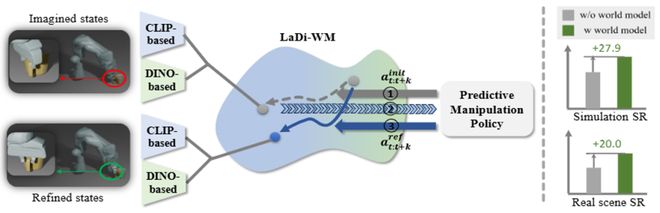

论文创新点:
1.一种基于隐空间扩散的世界模型:使用视觉基础模型构建隐空间的通用表示,并在隐空间学习可泛化的动态建模能力。
2.一种基于世界模型预测迭代优化的扩散策略:利用世界模型生成未来预测的状态,将预测的状态反馈给策略模型,迭代式地优化策略输出。
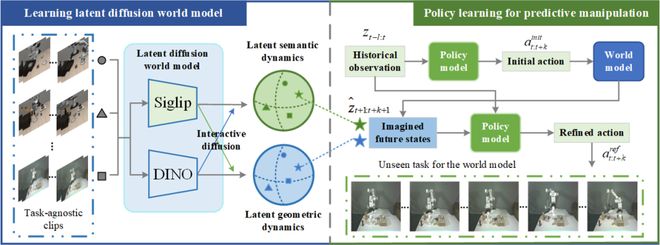 图 1 :(左)通过任务无关的片段学习隐扩散世界模型;(右)通过世界模型的未来状态预测来优化策略模型
图 1 :(左)通过任务无关的片段学习隐扩散世界模型;(右)通过世界模型的未来状态预测来优化策略模型技术路线
该团队提出一种利用世界模型优化策略学习的框架,以学习机器人抓取操作相关的技能策略。该框架可分为两大阶段:世界模型学习和策略学习。
A. 世界模型学习:
(a)隐空间表示:通过预训练的视觉基础模型对观测图像提取几何表征与语义表征,其中几何表征利用 DINOv2 提取,而语义表征则使用 Siglip 提取。
(b)交互扩散:同时对两种隐空间表示实施扩散过程,并在扩散过程中让二者充分交互,学习几何与语义表征之间的依赖关系,从而促进两种表示的准确动态预测。
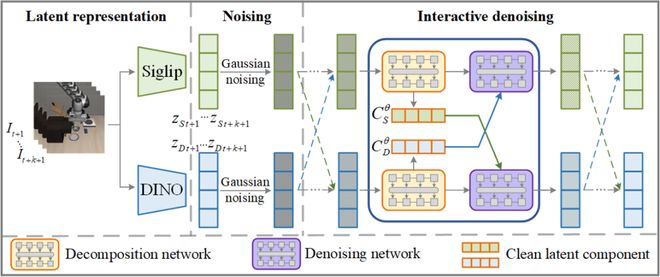 图 2 : 基于交互扩散的世界模型架构
图 2 : 基于交互扩散的世界模型架构B. 策略模型训练与迭代优化推理
(a)结合世界模型的未来预测引导策略学习:将世界模型给出的未来预测作为额外的输入,引导策略模型的准确动作预测;模型架构基于扩散策略模型,有利于学习多模态动作分布。
(b)迭代优化策略输出:策略模型可以在一个时间步多次利用世界模型的未来预测作为引导,从而不断优化自身的动作输出。实验显示,该方案可以逐渐降低策略模型的输出分布熵,达到更准确的动作预测。
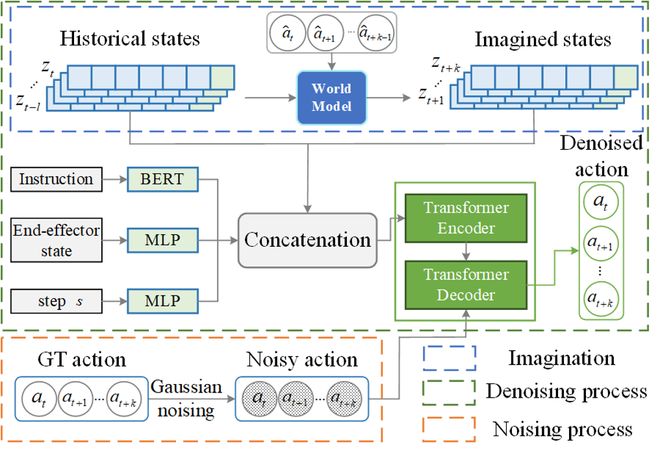 图 3 : 基于未来预测引导的策略模型架构
图 3 : 基于未来预测引导的策略模型架构实验结果
虚拟实验:
在公开的虚拟数据集(LIBERO-LONG,CALVIN D-D)中,团队验证了所提出框架在机器人抓取相关的操作任务上的性能。在实验中,世界模型的训练数据会与策略模型的训练数据区分开,从而验证世界模型的泛化能力。对于 LIBERO-LONG,给定语言指令,多次执行并统计机器人完成各项任务的成功率。对于 CALVIN D-D,连续给定五个语言指令,多次执行并统计平均完成任务的数量。
在 LIBERO-LONG 数据集,为了验证世界模型对策略模型的引导作用,团队仅使用 10 条轨迹去训练各任务,对比结果如表 1 所示。相比于其他方法,LaDi-WM 能够提供精确的未来预测,并将预测反馈给策略模型,不断优化动作输出,仅需少量训练数据即可达到 68.7% 的成功率,显著优于其他方法。
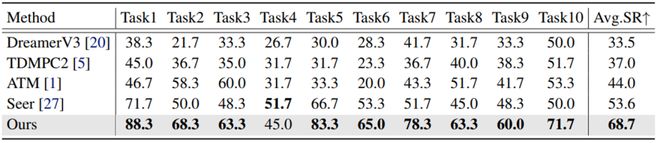
表 1: LIBERO-LONG 性能对比
在 CALVIN D-D 数据集上,LaDi-WM 同样展示了在长时任务中的强大性能(表 2)。
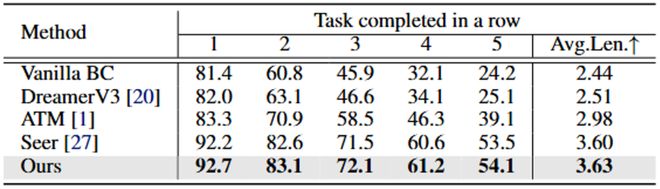
表 2: CALVIN D-D 性能对比
团队进一步验证了所提出框架的可扩展性,如图 4 所示。
(a)逐渐增大世界模型的训练数据,模型的预测误差逐渐降低且策略性能逐渐提升;
(b)逐渐增大策略模型的训练数据,抓取操作的成功率逐渐提升;
(c)逐渐增大策略模型的参数量,抓取操作的成功率逐渐提升。
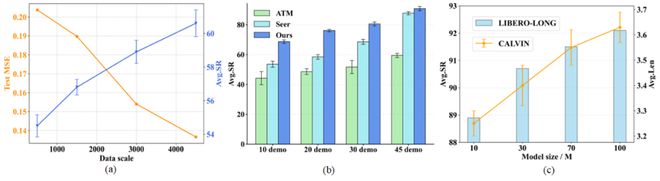 图 4 : 可扩展性实验
图 4 : 可扩展性实验为了验证 LaDi-WM 的跨场景泛化能力,团队在 LIBERO-LONG 上训练世界模型,并直接应用于 CALVIN D-D 的策略学习中,实验结果如表 3 所示。若是使用在 LIBERO-LONG 训练的原始策略模型,直接应用到 CALVIN D-D 是不工作的(表第一行);而使用在 LIBERO-LONG 训练的世界模型来引导 CALVIN 环境下的策略学习,则可以比在 CALVIN 环境训练的原始策略的性能高 0.61(表第三行)。这表明,世界模型的泛化能力要优于策略模型的泛化能力。
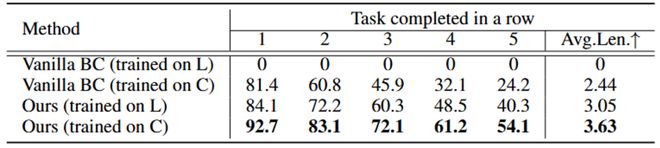
表 3: 跨场景实验结果。L 代表 LIBERO-LONG,C 代表 CALVIN D-D
团队进一步探索了利用世界模型迭代优化的工作原理。团队收集不同迭代轮次下策略模型的输出动作并绘制其分布,如图 5 所示。迭代优化的过程中,输出动作分布的熵在逐渐降低,这表明策略模型每一步的输出动作更加稳定,从而提升整体的抓取成功率。
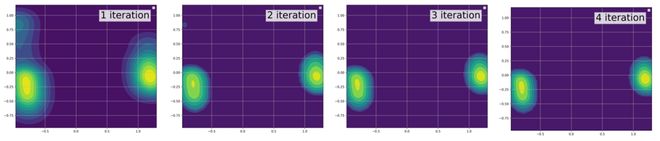 图 5 : 迭代优化的动作分布对比
图 5 : 迭代优化的动作分布对比真机实验:
团队也在真实场景中验证了所提出框架的性能,具体操作任务包括“叠碗”、“开抽屉”、“关抽屉”以及“抓取物体放入篮子”等,如图 6 所示。
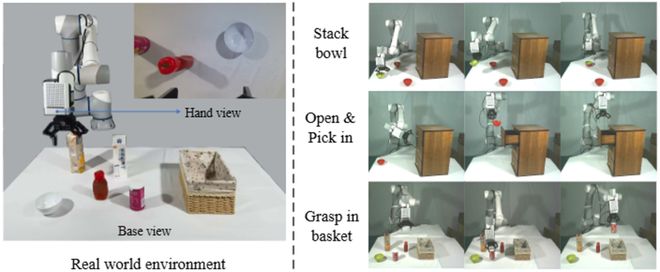 图 6 : (左)真实场景环境;(右)机器人实际操作样例
图 6 : (左)真实场景环境;(右)机器人实际操作样例在真实场景中,LaDi-WM 将原始模仿学习策略的成功率显著提升 20%(表 4)。

表 4: 真实场景性能对比
图 7 展示了最终所得策略模型在不同任务上的执行轨迹,从图中可以发现,提出的策略能够在不同光照条件以及不同初始位置的情况下有鲁棒的泛化性。
 图 7 : 真实场景机器人执行轨迹
图 7 : 真实场景机器人执行轨迹总结
国防科大、北京大学、深圳大学团队提出了一种隐空间扩散的世界模型 LaDi-WM(Latent Diffusion-based World Models),利用视觉基础模型提取通用的隐空间表示,并在隐空间学习可泛化的动态建模。同时,团队提出基于世界模型的未来预测来引导策略学习,在推理阶段通过迭代式地优化策略输出,从而进一步提高策略输出动作的准确度。团队通过虚拟与真机上广泛的实验证明了 LaDi-WM 的有效性,所提出的方法显著提升了机器人抓取操作技能的性能。