编辑:定慧 好困
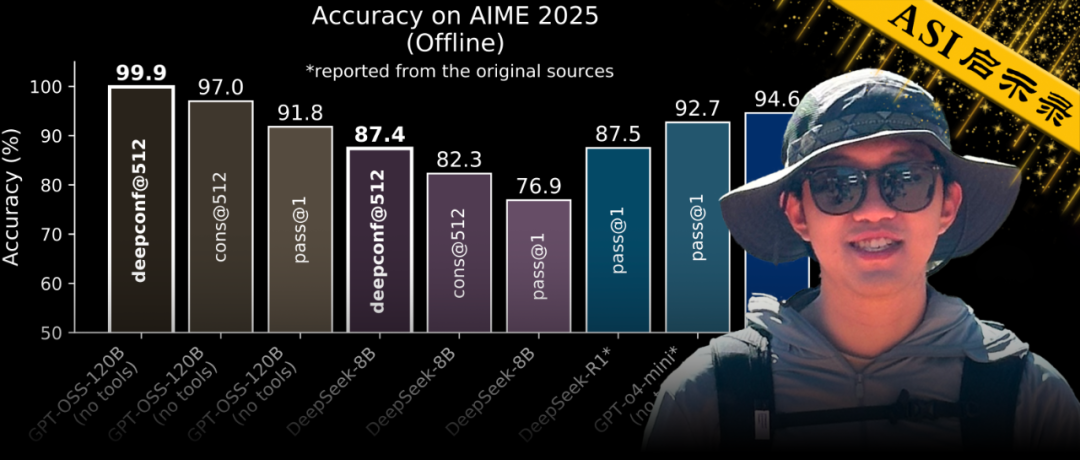
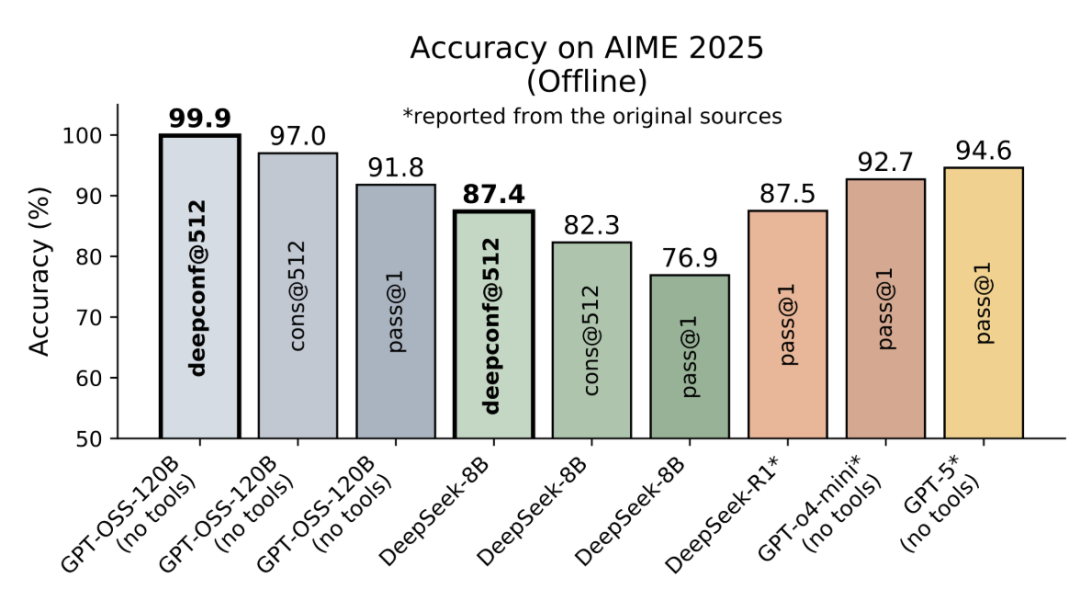
【新智元导读】DeepConf由Meta AI与加州大学圣地亚哥分校提出,核心思路是让大模型在推理过程中实时监控置信度,低置信度路径被动态淘汰,高置信度路径则加权投票,从而兼顾准确率与效率。在AIME 2025上,它首次让开源模型无需外部工具便实现99.9%正确率,同时削减85%生成token。
如何让模型在思考时更聪明、更高效,还能对答案有把握?
最近,Meta AI与加州大学圣地亚哥分校的研究团队给出了一个令人振奋的答案——Deep Think with Confidence(DeepConf),让模型自信的深度思考。
论文地址:https://arxiv.org/pdf/2508.15260
项目主页:https://jiaweizzhao.github.io/deepconf
这项新方法通过并行思考与“置信度筛选”,不仅让模型在国际顶尖数学竞赛AIME 2025上拿下了高达99.9%的正确率。
可以说,这是首次利用开源模型在AIME 2025上实现99.9%的准确率,并且不使用任何工具!
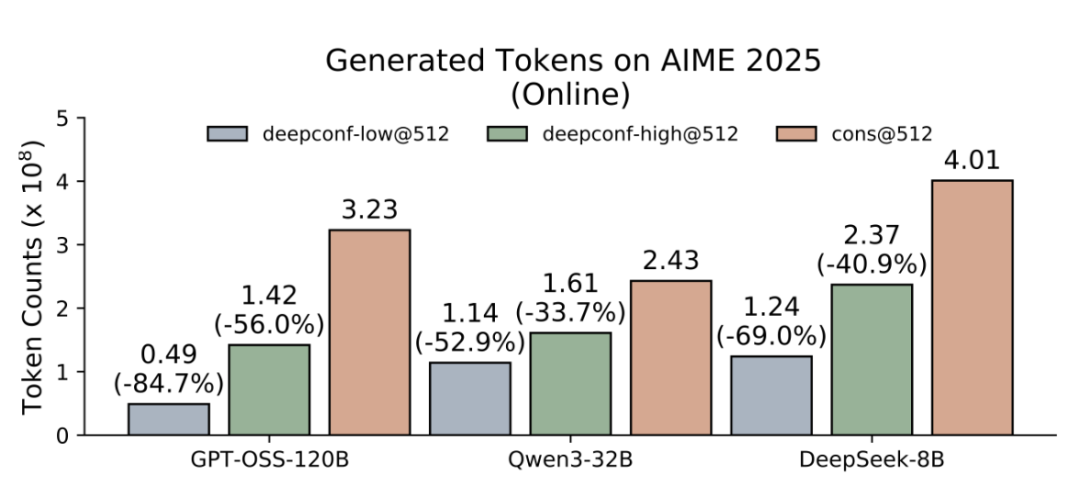
并且在保持高质量推理的同时,将生成的token数量削减了84.7%。
DeepConf还为并行思考(parallel thinking)带来了多项硬核优势:
性能飙升:在各类模型与数据集上,准确率平均提升约10%
极致高效:生成token数量锐减高达85%
即插即用:兼容任何现有模型——无需额外训练(也无需进行超参数微调!)
轻松部署:在vLLM中仅需约50行代码即可集成
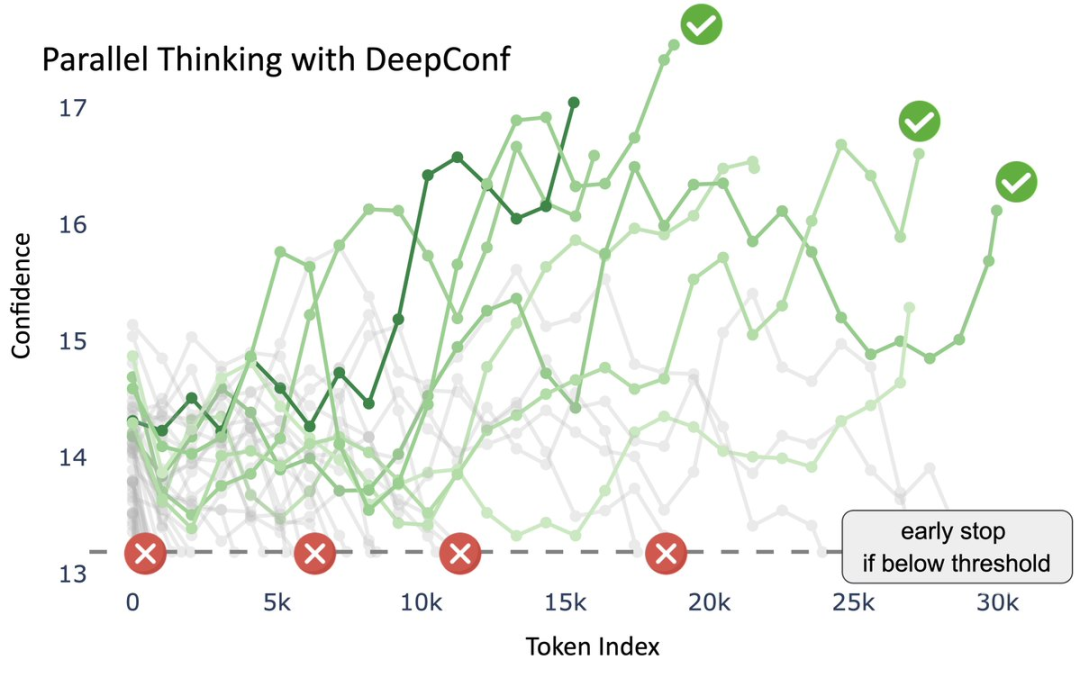
以DeepConf在HMMT 25(哈佛–麻省理工数学竞赛)的第11道题目上的推理过程为例。
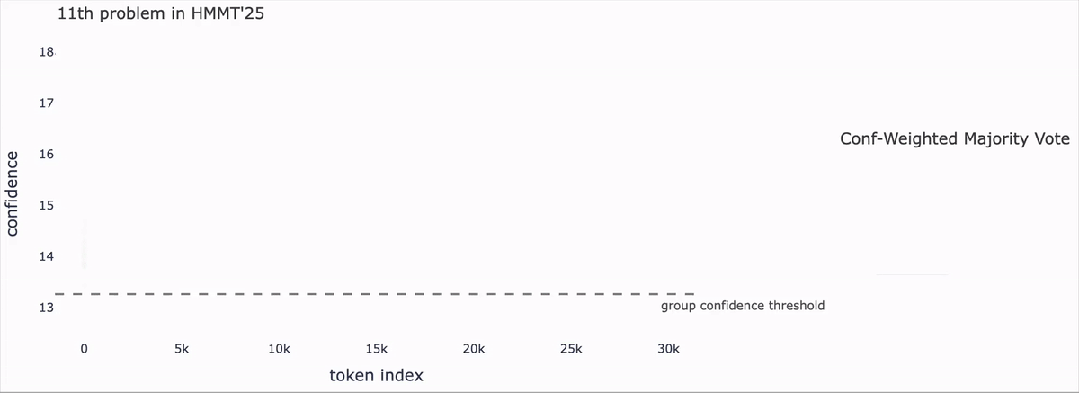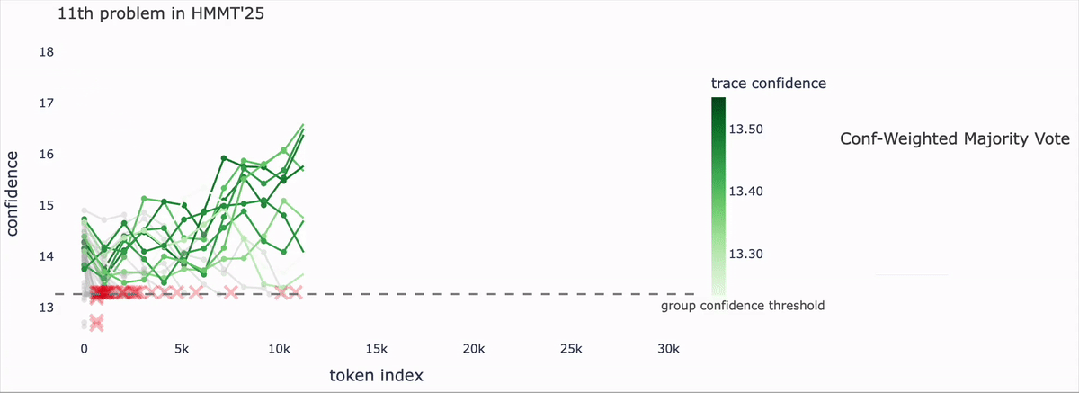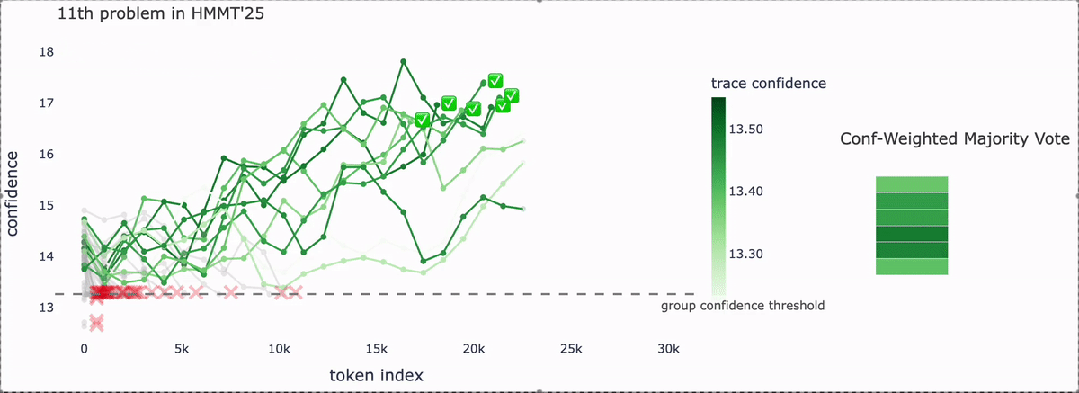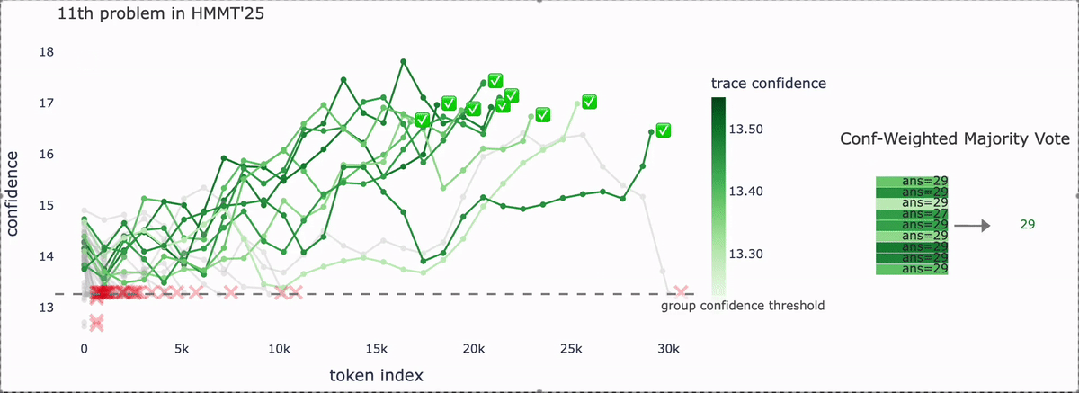
核心思想是DeepConf通过“置信度信号”筛选推理路径,从而得到高质量答案,并在效率与准确率之间取得平衡。
横轴(token index):表示模型生成的推理步骤(随着token逐步增加)。
纵轴(confidence):表示每条推理路径在该步骤上的置信度水平。
绿色曲线:表示不同推理路径的置信度轨迹,越深的绿色表示置信度越高。
红色叉叉:低于置信度阈值的推理路径,被动态筛除。
绿色对勾:最终被保留下来的高置信度路径。
最终表决:这些路径在基于置信度加权的多数表决下,最终得出统一答案:29。
DeepConf在生成过程中,会持续监控推理路径的置信度,低置信度路径被及时淘汰,只保留“更有把握”的路径,提升整体准确性。
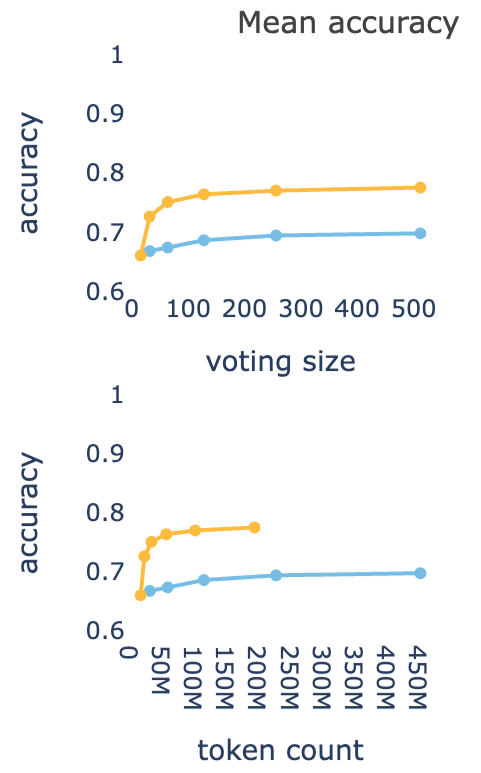
通过准确率对比曲线,上图可以看出纵轴是accuracy(准确率),黄色曲线(DeepConf)比蓝色曲线(标准方法)明显更高。
表明DeepConf在相同投票规模下能达到更高的准确率。
下图横轴是token数量(推理所需的计算成本),黄色曲线在准确率保持较高的同时,token消耗明显更少。
表明DeepConf大幅减少了无效token的生成,推理效率更优。
DeepConf让模型不再“胡思乱想”,而是高效地走在高置信度的推理轨道上。
DeepConf支持两种工作模式:
离线模式:根据置信度筛选已完成的推理路径,然后根据质量对投票进行加权。
在线模式:当置信度实时降至阈值以下时,立即停止生成。
DeepConf的秘诀是什么?
其实,LLM知道自己何时开始不确定的,只是大家一直没有认真关注过他们的“思考过程”。
之前的方法在完整生成之后使用置信度/熵用于测试时和强化学习(RL)。
DeepConf的方法不同,不是在完成后,而是在生成过程中捕捉推理错误。
DeepConf实时监控“局部置信度”,在错误的推理路径消耗数千个token之前及时终止。
只有高质量、高置信度的推理路径才能保留下来!
DeepConf是怎样“用置信度筛选、用置信度投票”?
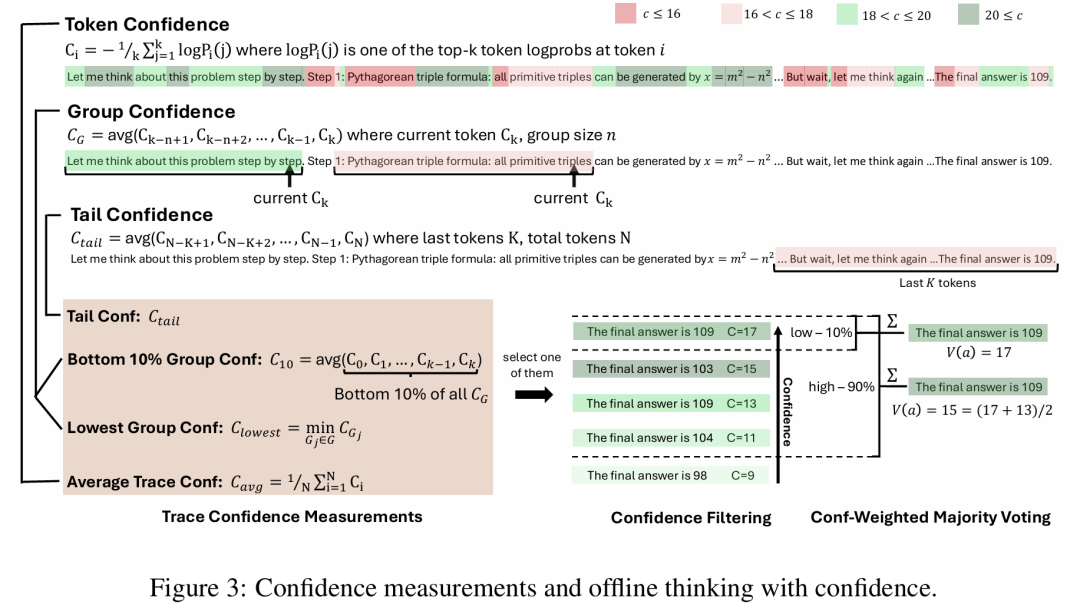
这张图展示了DeepConf在离线思考时的核心机制:
它先判断哪些推理路径值得信赖,把不靠谱的路径提前剔除,再让靠谱的路径进行加权投票,从而得到一个更准确、更高效的最终答案。
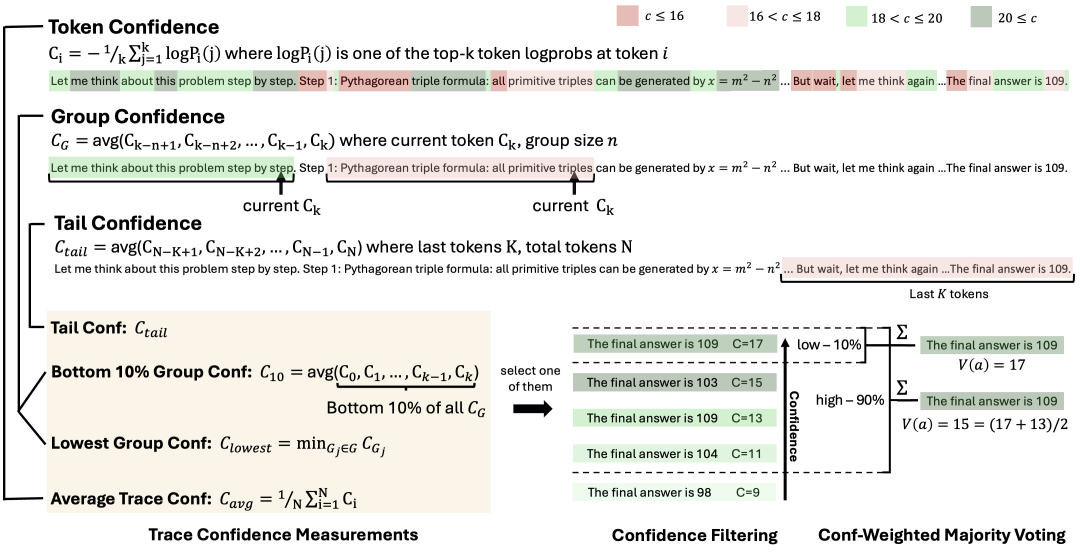
首先是每一token“有多确定”。
当模型在写推理步骤时,其实每个词(token)背后都有一个“信心值”。
如果模型觉得“这一步答案很靠谱”,信心值就高。如果它自己都拿不准,这个信心值就会低。
上图里用不同深浅的绿色和红色标出来:绿色=更自信,红色=不自信。
其次,不光要看单token,还要看整体趋势。
DeepConf不只看某一个词,而是会滑动窗口:看看一小段话里的平均信心值,衡量“这段话整体是否靠谱”。
重点看看最后几句话的信心值,因为最终答案、最终结论往往决定于结尾。
DeepConf也会记下这条推理链里最差的一步,如果中间有明显“翻车”,这条路径就不太可靠。
这样一来,每条完整的推理链路都会得到一个综合的“置信度分数”。
最后,是先淘汰,再投票。
当模型并行生成很多条不同的推理路径时:
第一步:过滤,把“置信度分数”排序,最差的10%直接丢掉,避免浪费。
第二步:投票,在剩下的推理链里,不是简单数票,而是按照置信度加权投票。
也就是说:一条高置信度的路径,它的意见分量更大;低置信度的路径,即便答案一样,也不会拉高太多票重。
最后看一下结果,在图的右边可以看到:有的路径说“答案是109”,有的说“答案是103、104、98”。
但由于支持“109”的路径更多、而且置信度更高,所以最终投票选出了109作为答案。
成绩刷爆99.9%
比GPT-5还高
离线模式结果:在AIME 2025上达到99.9%的准确率(基线为97%)!
在5个模型×5个数据集上实现普适性增益。
在所有设置下均取得约10%的稳定准确率提升。
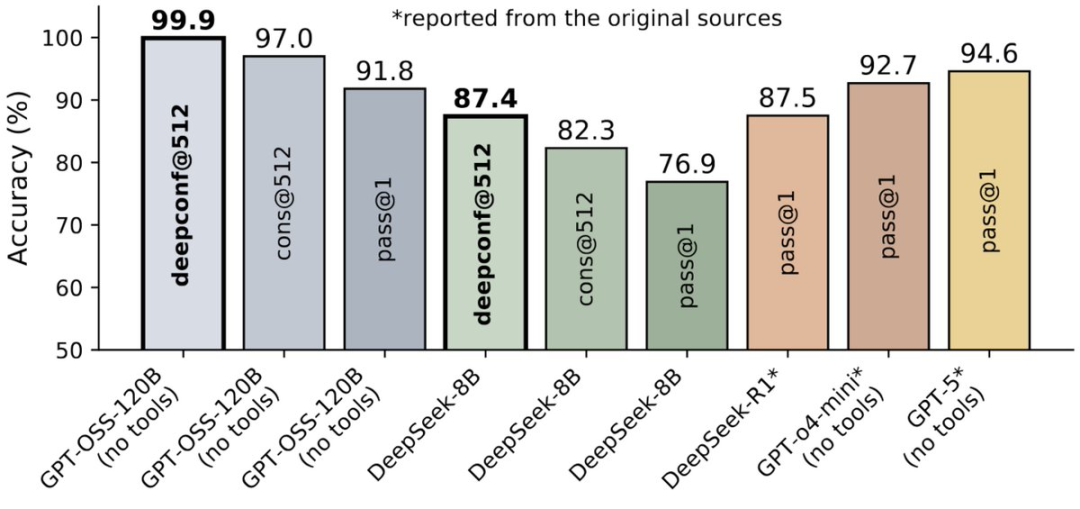
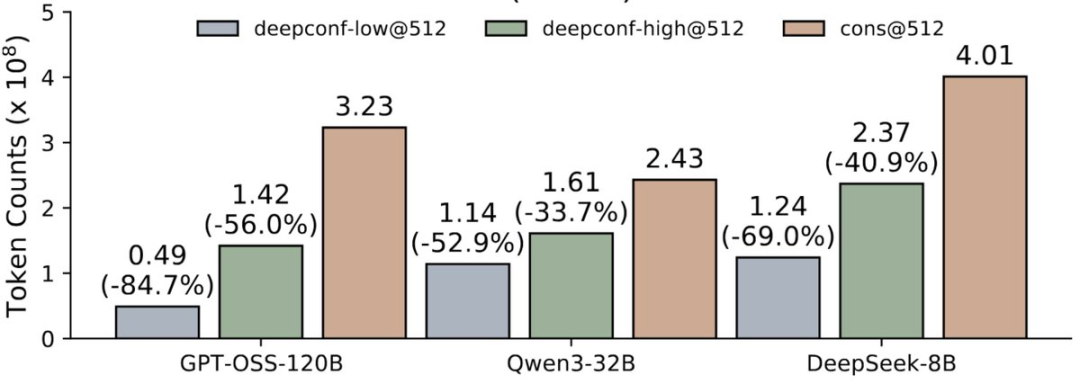
在线模式结果:在所有基准测试中节省33%-85%的token!
在AIME 2025基准测试中,使用GPT-OSS-120B,在减少85%的token消耗下,仍达到97.9%的准确率。
该方法适用于从8B到120B的各类开源模型——在不牺牲质量的前提下实现实时高效。
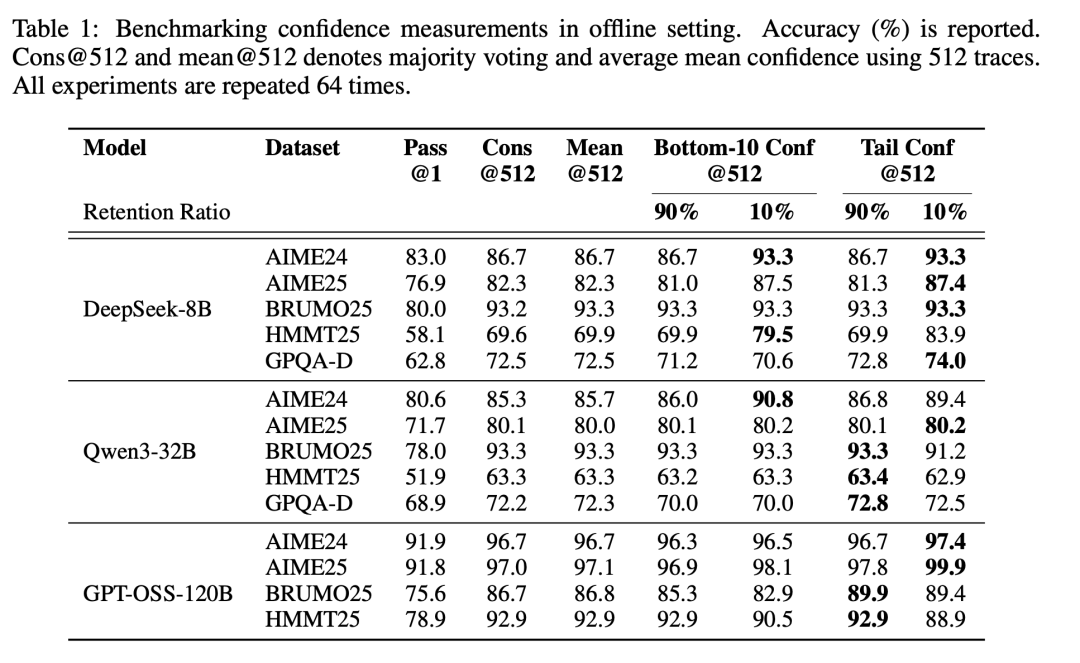
在离线环境中对置信度度量进行基准测试。报告的数值为准确率(%)。
Cons@512和mean@512分别表示使用512条推理轨迹进行的多数投票结果,以及平均置信度的均值。所有实验均重复进行了64次。
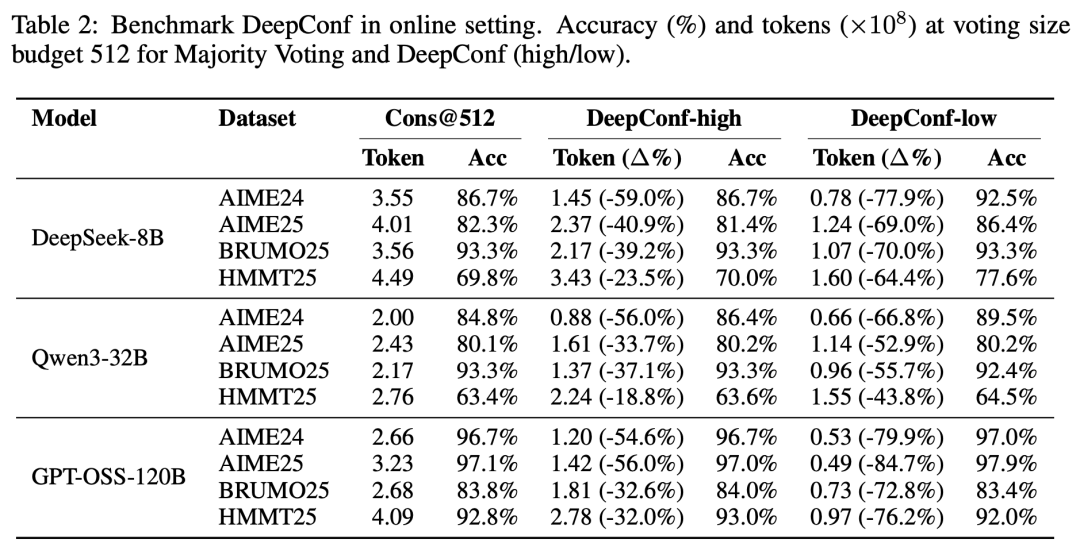
在在线环境中对DeepConf进行基准测试。
在投票规模预算为512的条件下,报告多数投票方法与DeepConf(高/低)的方法的准确率(%)以及生成的token数量(×10⁸)。
基于置信度的深度思考
研究者的思考是:到底怎么把“置信度”用得更巧妙,让模型既想得更准,又想得更快呢?
正如前文所述,这里可以分成两个使用场景:
离线思考:等模型把一整条推理路径都写完了,再回头去评估每条路径的置信度,把靠谱的结果聚合在一起。这样做的好处是能最大化提升答案的准确性。
在线思考:在模型一步步生成推理的过程中,就实时参考置信度。如果发现某条思路不靠谱,可以及时停掉,避免浪费算力。这样能边走边筛选,提升效率甚至精度。

离线思考
在离线思考模式下,每个问题的所有推理路径均已生成。
此时的核心挑战是:如何聚合来自多条路径的信息,从而更准确地确定最终答案。
针对这一点,研究人员采用了标准的多数投票(majority voting)方法。
多数投票(Majority Voting)
在标准的多数投票中,每条推理路径得出的最终答案对最终决策的贡献是均等的。
设T为所有已生成路径的集合,对于任意路径t∈T,设answer(t)为从该路径中提取的答案文本。
那么,每个候选答案a的票数为:
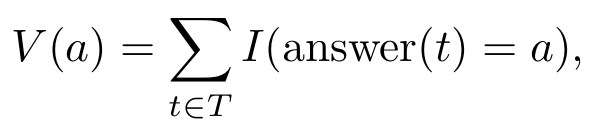
置信度加权多数投票
这个方法不再均等对待每条路径的投票,而是依据其关联路径的置信度,为每个最终答案赋予权重。
对于每个候选答案a,它的总投票权会被重定义为:
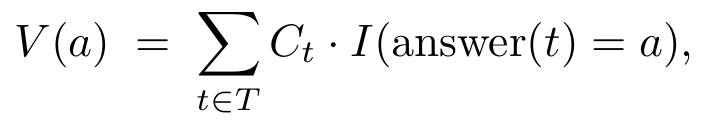
置信度过滤
在加权多数投票的基础上,还需要应用置信度过滤,才能在将投票更集中于高置信度的推理路径。
具体来说就是,通过路径的置信度分数,筛选出排序前η%的路径,从而确保只有最可靠的路径参与最终答案的决定。
选择前10%:专注于置信度最高的少数路径。适用于少数路径就能解决问题的场景,但风险是如果模型存在偏见,容易选错答案。
选择前90%:纳入更广泛的路径。这种方法能保持多样性、减少模型偏见,在各路径置信度相差不大时尤其稳健。
图3阐释了各种置信度度量方法以及基于置信度的离线思考的工作原理。
算法1则提供了该算法的详细实现。

在线思考
在线思考模式通过在生成过程中实时评估推理路径的质量,来动态终止低质量的路径,进而确保其在后续的置信度过滤阶段大概率能被排除。
对此,研究人员提出了两种基于最低分组置信度,并会自适应地中止生成过程并调整推理路径的预算的方法:DeepConf-low和DeepConf-high。
其中,共包含两大核心组件:离线预热与自适应采样。
离线预热(Offline Warmup)
DeepConf需要一个离线预热阶段,以便为在线决策过程建立停止阈值s。
对于每个新的提示词,首先生成Ninit条推理路径(例如,Ninit=16)。
停止阈值s定义为:
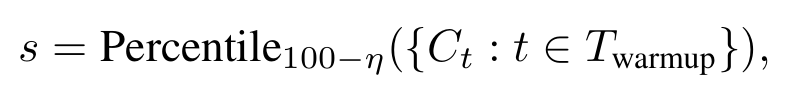
在所有配置下,DeepConf-low均统一采用前η=10%的策略,而DeepConf-high则统一采用前η=90%的策略。
在在线生成过程中,一旦某条推理路径的置信度低于预热阶段的数据所设定的、能够筛选出置信度排序前η%路径的最低门槛,生成过程就会被终止。
自适应采样(Adaptive Sampling)
在DeepConf中,所有方法都采用了自适应采样,如此就可以根据问题难度动态调整所生成推理路径的数量。
问题难度通过已生成路径之间的一致性程度来评估,其量化方式为多数投票权重与总投票权重的比值:
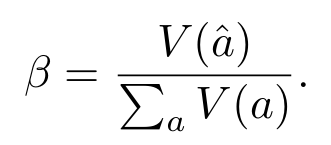
若β
由于采用的是最低分组置信度,一个足够大的预热集便能产生对停止阈值s的精确估计。
因此,任何被在线终止的路径,其分组置信度必然低于s,也就会被离线过滤器所排除。
这样,在线流程便能近似于离线的最低分组置信度策略,并且随着Ninit的增加,其准确率会逼近离线策略的准确率。
图4中阐释了在线生成的过程。
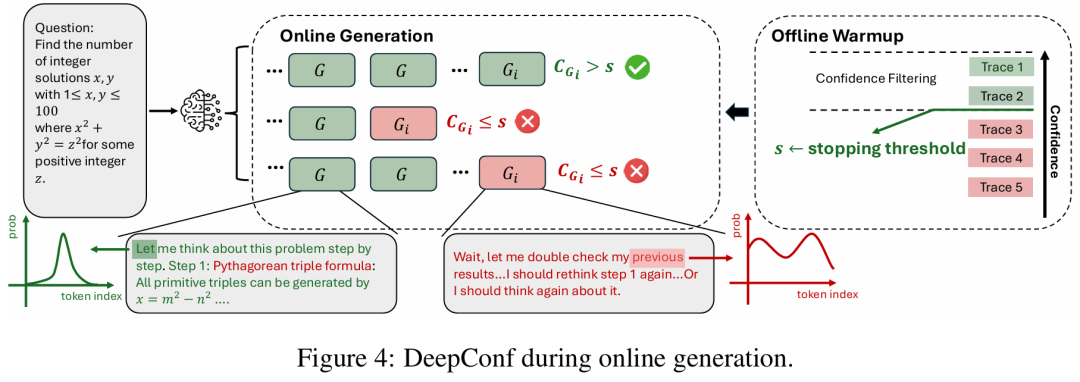
算法2则提供了该算法的详细实现。

具体过程,我们就用上图里的这道“勾股三元组计数”问题举个例子。
DeepConf要在生成推理的同时判断:哪条思路靠谱、该继续;哪条思路不靠谱、该尽早停,从而少花token、又更准。
两个阶段:先定阈值,再在线筛
1. Offline Warm-up(上图右侧,离线预热)
先离线跑几条完整的推理轨迹(Trace 1~5),给每条算一个“整体有多靠谱”的分数。
按分数做一次置信度过滤,好的轨迹在上方(绿色),差的在下方(红色)。
据此确定一个停止阈值s(图中绿色箭头标注)。
简单来说就是低于 s 的,通常是不值得继续的推理。
这一步就像“热身+标定”,模型把“该不该停”的门槛先定好。
2. Online Generation(上图中间,在线生成)
正式解题时,同时展开多条并行思路(多行的方块序列)。
对每条思路,系统滚动地评估“这段话最近一小段的可靠度”(图中方块从左到右代表一步步的生成)。
左下 & 右下的小曲线各自表示模型的“把握”程度。
左下绿曲线表示模型对接下来的词更“有把握”,示例文本是正经的数学推理(如“勾股三元组公式…”),这类内容通常被保留。
右下红曲线表示模型在犹豫或“自我怀疑”,示例文本是“让我再想想、回头检查一下…”,这类犹豫/兜圈子的片段常被判为低置信度,从而触发在线早停。
先离线确定“可靠度阈值s”,再在线用s给并行思路“边走边检查”。
不靠谱就当场叫停,靠谱的继续前进。这样就能做到既快又准了。
作者介绍
Yichao Fu

论文一作Yichao Fu是加州大学圣地亚哥分校(UC San Diego)计算机科学与工程系的博士生,师从张昊教授,也就是老朋友Hao AI Lab的负责人。
此前,他在浙江大学获得计算机科学学士学位。
他的研究兴趣主要为分布式系统、机器学习系统以及高效机器学习算法,近期专注于为LLM的推理过程设计并优化算法与系统。
他参与的项目包括:Lookahead Decoding、vllm-ltr和Dynasor。