
作者 | 陈骏达
编辑 | 李水青
智东西8月28日报道,近日,知名华人AI科学家,普林斯顿大学计算机科学系副教授,NLP小组负责人陈丹琦更新了自己Github主页上的邮箱,邮箱后缀已经变为“thinkingmachines.ai”。
这是前OpenAI首席技术官Mira Murati、前安全副总裁翁荔(Lilian Weng)等人联合创办的明星AI独角兽Thinking Machines Lab的邮箱域名,或许意味着陈丹琦已经加入这家公司。
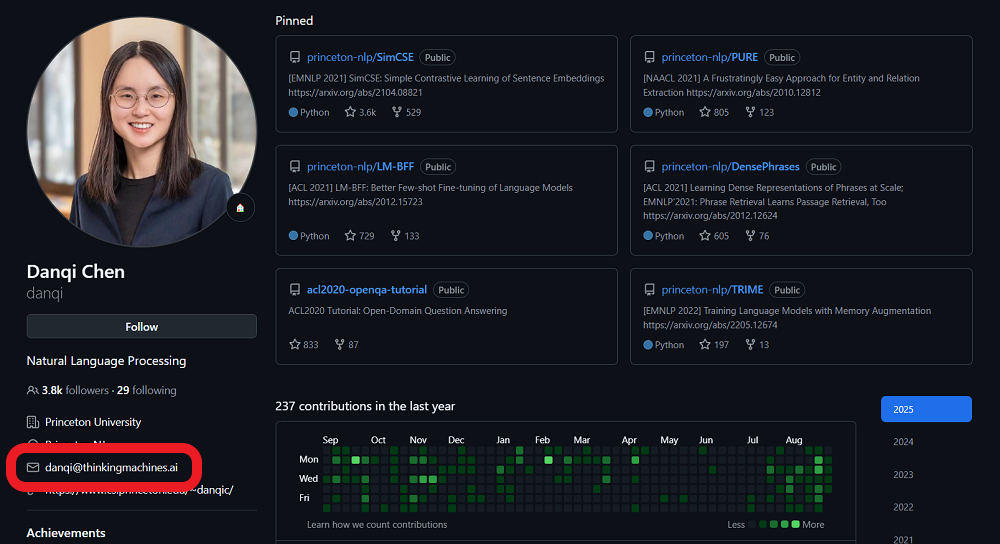
▲陈丹琦GitHub主页
在开源模型平台Hugging Face上,陈丹琦也成为了Thinking Machines Lab团队的成员之一。
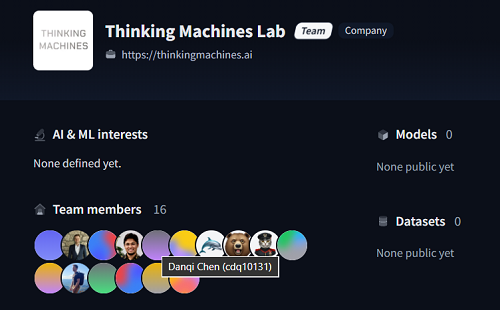
今年7月,刚刚成立5个月的Thinking Machines Lab完成了20亿美元(约合人民币143.46亿元)的全球史上最大种子轮融资,投后估值达120亿美元(约合人民币857.87亿元)。这家创企阵容豪华,多位成员曾在OpenAI担任要职,如OpenAI联合创始人、前后训练团队负责人John Schulman,以及前GPT-4o-mini团队负责人Kevin Lu等。
陈丹琦于2008年保送进入清华大学计算机科学实验班(姚班),2012年获计算机科学学士学位,随后赴美国斯坦福大学攻读博士,2018年获计算机科学博士学位,导师为原斯坦福大学AI实验室主任、NLP领域的领先专家Christopher Manning。
陈丹琦曾两次获得计算语言学领域顶会ACL的优秀论文奖,也曾获得谷歌、亚马逊、Meta、Adobe等机构给学者颁发的奖项。
2016年,陈丹琦作为第一作者,凭借论文“A Thorough Examination of the CNN/Daily Mail Reading Comprehension Task(《对CNN/每日邮报阅读理解任务的全面评估》)”获得ACL的优秀论文奖。
这篇论文帮助学界认识到,数据集本身的缺陷回影响模型评估的可信度,是理解早期机器阅读理解研究局限性的里程碑式论文。

▲陈丹琦作为第一作者的ACL 2016优秀论文
2022年,由她指导并署名的论文“Ditch the Gold Standard: Re-evaluating Conversational Question Answering(《抛弃黄金标准:对话式问答的再评估》)”再次获得ACL优秀论文奖,这一论文的第一作者为Huihan Li。

▲陈丹琦参与指导的ACL 2022优秀论文
这篇论文提出应当重新审视评估标准,强调在对话问答场景中,单一“标准答案”不足以衡量模型真实的理解与对话能力。研究提供了更合理的评估方法,反映模型在多样性、语境理解与对话适应性方面的表现。
在斯坦福大学期间,陈丹琦在句法解析、知识库构建、问答和对话系统等领域做出了贡献。
她2014年发表的论文“A Fast and Accurate Dependency Parser Using Neural Networks(《一种快速且准确的基于神经网络的依存句法分析》)”是第一个成功的神经网络依存句法分析模型,用于分析句子的语法结构。该工作为谷歌NLP团队后续解析器的研究奠定了基础。
陈丹琦2017年发表的论文“Reading Wikipedia to Answer Open-Domain Questions(《通过阅读维基百科回答开放域问题》)” 开启了将信息检索与神经阅读理解方法结合起来,进行开放域问答研究的方向。
2018年,陈丹琦完成了题为“Neural Reading Comprehension and Beyond(《神经阅读理解及其拓展》)”的博士论文,长达156页。
该论文重点研究阅读理解和问答任务,在斯坦福大学正式公开后,迅速成为近十年来最受欢迎的博士论文之一。后来,它被中国的NLP研究者翻译成中文,是该领域许多人必读的著作。

▲陈丹琦博士论文封面
陈丹琦目前引用量最高的论文是“RoBERTa:A Robustly Optimized BERT Pretraining Approcah(《RoBERTa:一种稳健优化的 BERT 预训练方法》)”,单篇引用量达3.6万多次。这是她在FAIR期间参与的研究项目之一。
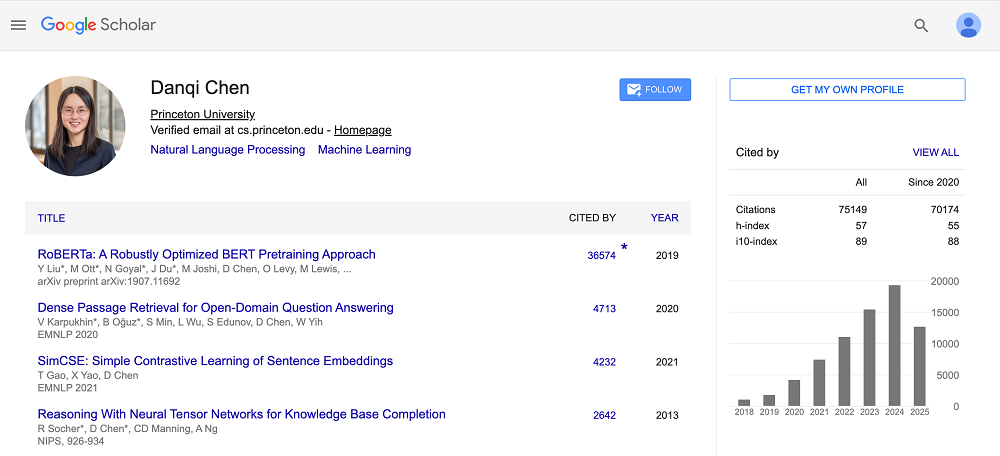
▲陈丹琦谷歌学术主页(图源:谷歌学术)
这篇论文让NLP社区认识到,模型架构并非唯一突破口,训练策略与数据规模同样关键。此后许多大规模语言模型(如GPT-3等)都在数据与训练策略上进行了类似优化。

▲陈丹琦参与的RoBERTa论文
从斯坦福大学毕业后,陈丹琦入职普林斯顿大学。她在普林斯顿大学的个人主页显示,她担任该校NLP小组的共同负责人、语言与智能中心副主任,负责大模型相关的基础研究。陈丹琦还是西雅图Facebook AI研究院(FAIR)的访问科学家。
陈丹琦的个人主页显示,她近期的学术兴趣包括检索、大预言模型训练部署民主化等。
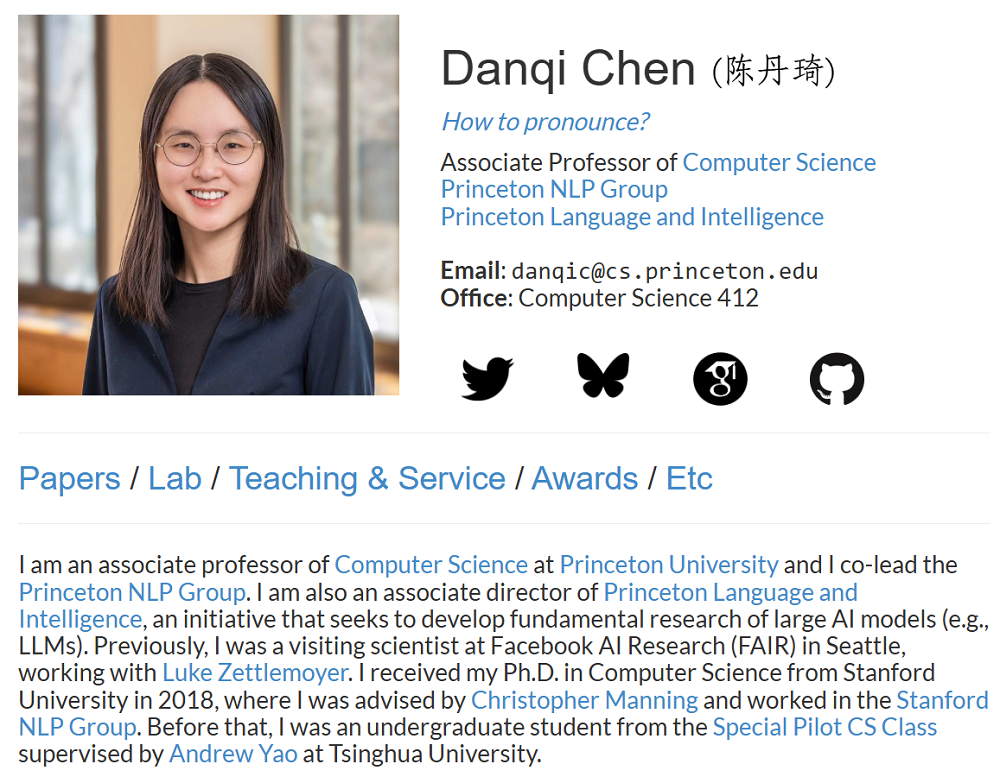
▲陈丹琦在普林斯顿大学的个人主页
陈丹琦认为,检索应该在下一代语言模型中发挥基础性作用,以提高其真实性、适应性、可解释性和可信度。她的团队正在积极探索如何构建有效的检索器,以及如何将检索与语言模型相结合,以实现最佳权衡。
此外,陈丹琦还希望通过改进训练方法、数据管理、优化到模型压缩和下游适配等方式,实现大语言模型模型训练和部署的民主化,尤其是在学术界。
结语:又一AI学者投身产业界
近年来,越来越多的AI学者选择投身产业界。从斯坦福大学以人为本AI研究院主任李飞飞休假创业,到MIT教授、计算机视觉领域的领军人物何恺明加盟DeepMind担任杰出科学家,再到如今的陈丹琦,已经形成了一种趋势。
产业界所掌握的海量资金与算力,对顶尖学者无疑具有强大吸引力。随着高校与企业在研究资源上的差距逐渐拉大,学者们或许能够在产业界找到更充分的条件去实现科研构想。我们期待这些学者们,在未来实现更多的创新突破。