2025 年 8 月 29 日,由清华大学计算机系崔鹏教授团队联合稳准智能共同研发的结构化数据通用大模型 “极数” (LimiX)正式宣布开源。此次发布标志着我国在结构化数据智能处理领域的技术突破与生态开放迈出关键一步,将显著降低千行百业应用结构化数据 AI 技术的门槛。特别是在结构化数据占主导的泛工业领域,“极数”大模型将助力AI深度融入工业生产全流程,破解工业数据价值挖掘难题,为实现智能制造与新型工业化提供关键支撑,推动产业技术变革和优化升级。
在泛工业领域,结构化数据是核心资产——工业生产参数、设备运行数据、质量检测数据、科研实验数据等均以结构化数据形式呈现,其智能处理能力直接影响产业效率与科研突破,也是 AI 赋能工业制造的关键突破口。虽然通用大语言模型(LLM)凭借强大的文本理解与生成能力,已在内容创作、对话交互等领域实现广泛应用,但 LLM 在面对表格、时序等结构化数据时短板明显:数值比较、计算等基础任务易出偏差,更无法胜任数据分类、预测、归因等复杂任务,准确率难以满足真实行业需求。因此,目前工业结构化数据处理依然依赖私有数据+专用模型的传统范式。由于专用模型难泛化、不通用,面对不同场景需要训练多个专用模型,成本高、效果差,且难以发挥数据要素聚集的乘数效应,严重制约了AI在工业场景的落地路径。
结构化数据通用大模型(Large Data Model, LDM)则针对性解决这一痛点:不同于 LLM 聚焦文本,LDM 融合结构因果推断与预训练大模型技术,既能捕捉结构化数据的内在关联,又具备强泛化能力,可跨行业适配多类任务。“极数”大模型可以支持分类、回归、高维表征抽取、因果推断等多达10类任务,在工业时序预测、异常数据监测、材料性能预测等场景中,性能达到甚至超越最优专用模型,实现单一模型适配多场景、多任务的通用性突破,为人工智能赋能工业提供了One-For-All解决方案。
从技术性能到产业落地,“极数”大模型的核心优势已得到充分验证。在超过600个数据集上的十余项测试结果表明,“极数”大模型无需进行二次训练,已经在准确率、泛化性等关键指标上均能达到或超过专有SOTA模型。而在产业应用层面,“极数”大模型已成功落地多个真实工业场景,无需训练、部署成本低、准确率高、通用性强的特点获得合作企业的高度认可,成为推动工业数据价值转化的实用型技术方案,正加速形成面向泛工业垂直行业核心业务场景的真正智能底座。
1、研发团队
“极数”模型的研发核心力量,由清华大学计算机系崔鹏教授牵头组建,团队汇聚了学术研究与产业落地的双重优势,其技术突破背后是深厚的科研积淀与前瞻性的方向布局。
作为团队核心,崔鹏教授是我国数据智能领域的顶尖学者:他不仅是国家杰出青年科学基金获得者,更以突出成果两度斩获国家自然科学二等奖,同时获评 国际计算机协会(ACM)杰出科学家,其学术影响力获国际学界广泛认可。在基础研究领域,崔鹏教授开创性提出 “因果启发的稳定学习” 新范式,突破传统机器学习在数据分布偏移场景下的性能局限,为 AI 模型的可靠性与泛化性研究奠定重要理论基础。
2022 年 OpenAI 推出 ChatGPT 引发大模型技术浪潮后,崔鹏教授敏锐洞察到结构化数据方向大模型技术的发展潜力,迅速将研究方向从因果稳定学习拓展至结构化数据通用大模型(LDM)领域。依托既有理论积累,团队攻克结构因果数据合成、模型结构设计、跨场景泛化等核心难题,最终实现 “极数” 模型在多领域任务中的性能突破,为此次开源奠定关键技术基础。
2、极数大模型简介
“极数”大模型将多种能力集成到同一基础模型中,包括:分类、回归、缺失值插补、数据密度估计、高维表征抽取、数据生成、因果推断、因果发现和分布外泛化预测等;在拥有优秀结构化数据建模性能的同时,极大提高了模型的通用性。
在预训练阶段,“极数”大模型基于海量因果合成数据学习数据中的因果关系,不同于专用模型在训练阶段记忆住数据特征的模式,“极数”大模型可以直接在不同的上下文信息中捕捉因果变量,并通过条件掩码建模的方式学习数据的联合分布,以适应包括分类、回归、缺失值预测、数据生成、因果推断等各种下游任务。在推理阶段,极数可直接基于提供的上下文信息进行推理,无需训练即可直接适用于各种应用场景。
模型技术架构
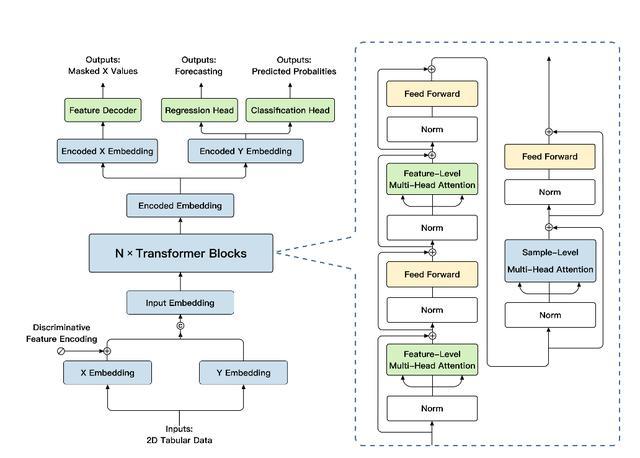
“极数”大模型沿用了transformer架构,并针对结构化数据建模和任务泛化进行了相关的优化。“极数”大模型先对先验知识库中的特征 和目标 分别进行embedding;之后在主要模块中,在样本和特征维度上分别使用注意力机制,来聚焦关键样本的关键特征。最终,提取到的高维特征被分别传入regression head和classification head,实现对不同功能的支持。
训练数据构建
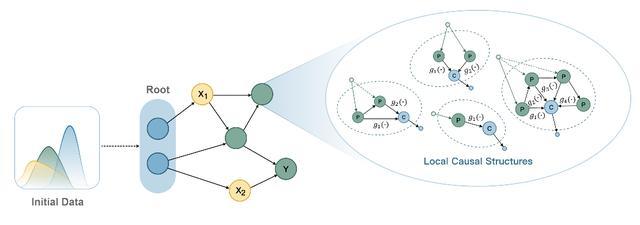
不同于传统的树模型和基于transformer架构的LLM,“极数”大模型在训练过程中完全使用生成数据,不依赖于任何真实世界的数据来源。为了使数据生成的过程高效且可控,团队使用了基于结构因果图的数据生成方式:采样到的初始数据在有向无环图上进行传播,通过复杂的边映射和节点交互来模拟现实世界中不同的因果依赖关系;通过对因果图上的生成数据进行采样,最终获得训练数据中的特征 和目标 。使用这种方法生成的数据,既实现了因果结构上的多样性,又保证了数据的可控性。
模型优化目标
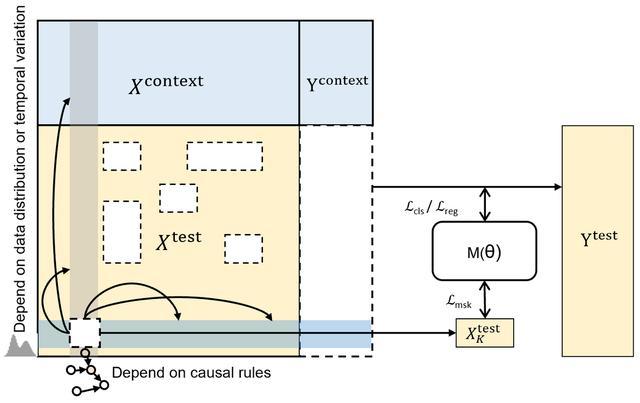
通用结构化数据大模型(LDM)需要在各种应用场景的各种任务中通用,且具备无需进行训练的数据建模能力。因此需要对数据的联合分布进行建模,以提高模型的通用性、增强对特征交互模式的建模能力。为此,“极数”大模型在模型优化目标设计中加入了掩码重构机制:在训练过程中,通过对随机特征值进行掩码操作,模型将根据特征间的因果依赖关系,使用观测到的特征来重构缺失特征。通过引入掩码预测,模型可以学习到数据特征的联合分布,学习到更清晰且鲁棒的决策边界,提高对特征依赖关系的表示学习能力。为了更贴近真实场景中的缺失模式,“极数”大模型在三个维度上进行了掩码操作,分别是:
样本维度掩码:对于每一个样本,随机掩码掉其中的某些特征。
特征维度掩码:对于所有样本,随机掩码掉其中的一个特征。
语义维度掩码:关注高维上的相关性,将语义相关度高的特征中的某些特征随机掩码掉。
此外,“极数”大模型将特征缺失比例纳入考量,通过设计针对每行或每个子集缺失的训练目标,稳定了模型在不同缺失程度下的推理性能,提高了对各类缺失模式的鲁棒程度。
模型推理
在推理应用环节,“极数”大模型具备极强的场景适配性与任务灵活性。该模型无需针对特定场景或任务进行额外训练,即可直接接收表格、时序、图等多形态结构化数据输入;用户仅需明确分类预测、回归预测、缺失值补全、数据生成、因果推断、因果发现等具体任务类型,模型即可自动完成数据解析、逻辑建模与结果输出,真正实现即插即用模式,高效覆盖各类结构化数据处理需求。
此外,“极数”大模型还支持针对数据集进行模型高效微调,可使模型学习更全面的数据中的因果联系,在预测层面的性能会进一步提升。
3、模型效果
“极数”大模型在无需针对数据集进行专项训练的情况下,在分类、回归等多项结构化数据核心任务上取得了优异的性能表现。
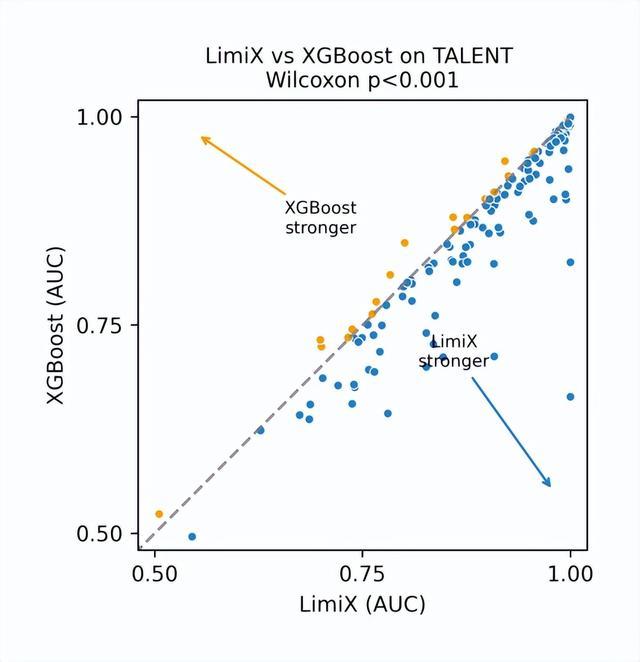
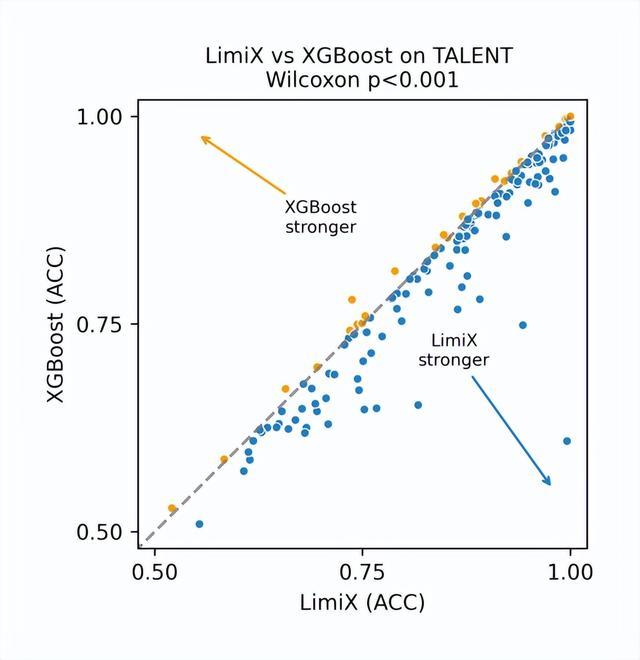
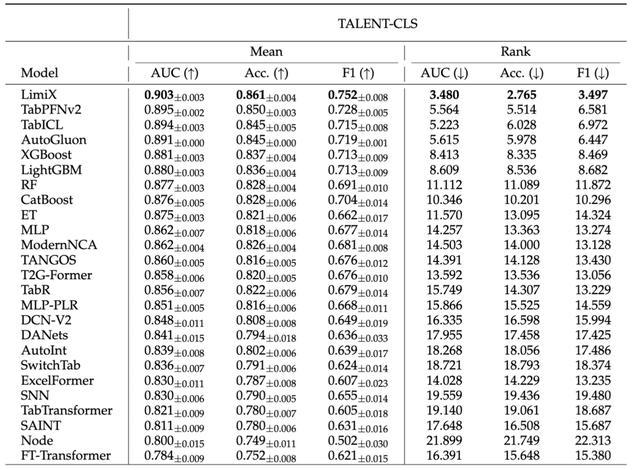
模型评测方面,选取了各个领域的权威数据集作为Benchmark。如开源数据集 Talent,它包含上百个真实数据集,是当前领域内体量最大、最具代表性的基准之一。在分类任务中,对比“极数”与21个领域内的常用baseline方法,“极数”大模型的模型性能显著超越其他模型,在AUC、ACC、F1 Score和ECE上均取得了最优。
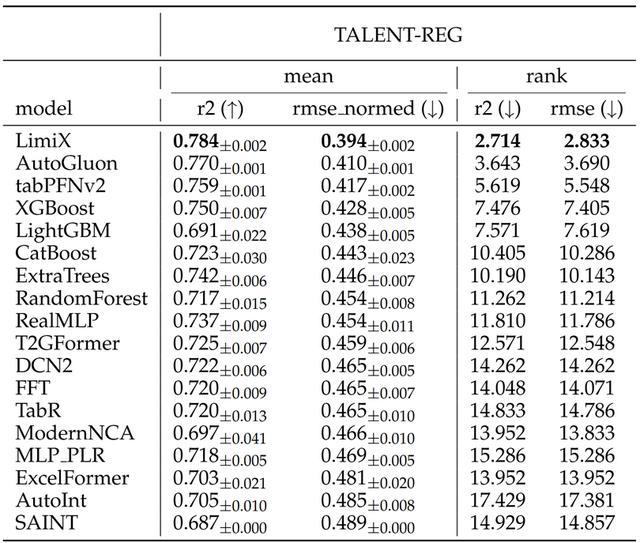
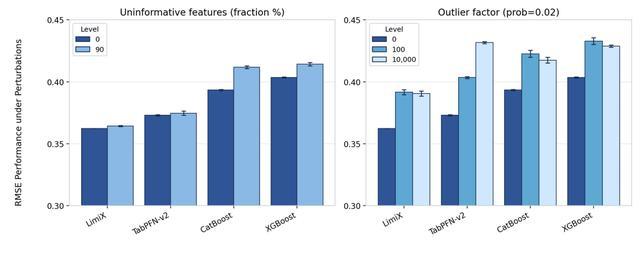
在回归任务上,“极数”大模型在R2和RMSE指标上都达到了平均最优,对比其他baseline方法展现出了明显的优势。并且在数据集中有干扰特征或无效特征时,性能优势更加明显。
4、模型落地应用
目前,“极数”大模型凭借其优越的通用建模能力,有效破解了传统专用模型在工业场景“数据稀缺、质量参差、环境异质”情况下的能力瓶颈,已在多个关键工业场景中成功落地。
在工业运维领域,“极数”大模型已成功应用于钢铁、能源、电力等行业,扮演着“设备健康管家”的角色,为设备运行监测、故障预警与健康度评估等任务提供核心支撑。以某钢铁企业为例,其复杂产线长期面临难以从海量传感数据中精准捕捉非典型异常信号而导致的预警失效问题,给安全生产带来巨大隐患。“极数”大模型部署后,将设备故障预测准确率在原专用模型基础上提升了15%,达到应用级要求,推动其维护模式从“事后维修”向“预测性维护”转型,显著提升了生产的安全性与运行效率。
在工艺优化领域,“极数”大模型在化工、制造、生物等行业中则化身为“生产智囊”。在某材料研发企业,如何从海量物化特征中精准识别关键因子,是提升材料设计效率的核心瓶颈。“极数”大模型成功筛选出少数核心优化因子,在确保信息无损(R^2超过0.95)的前提下,将调控效率提升了5倍,为企业的降本增效与绿色生产提供了科学决策依据。
业内专家表示,“极数”大模型的成功落地不仅验证了通用建模技术在工业场景的适用性,更为解决工业数据应用痛点提供了标准化解决方案,有望推动更多工业领域实现智能化升级。
5、开源地址
项目主页:
https://limix-ldm.github.io
技术报告:
https://github.com/limix-ldm/LimiX/blob/main/LimiX_Technical_Report.pdf
Github:
https://github.com/limix-ldm/LimiX
Huggingface:
https://huggingface.co/stableai-org
Modelscope:
https://modelscope.cn/organization/stable-ai
6、结语
在当前人工智能的发展浪潮中,大语言模型(LLM)通过大规模预训练实现了“语义空间的通用世界模型”,而如何面向工业数据的独特属性,构建“数据空间的通用世界模型”,已成为AI迈向产业纵深的关键命题。在这一目标的驱动下,发展能够跨场景、跨任务、跨环境的结构化数据通用大模型(LDM)势在必行。我国凭借丰富的工业数据资源与多元的应用场景,有望在LDM领域打造出独特的“非对称竞争力”。清华大学团队此次开源发布的“极数”大模型,正是这一方向上的重要突破。期待以此为起点,共同迎接LDM的“GPT-3时刻”早日到来。