华人 95 后“叫板”谷歌搜索,联合创办 AI 搜索公司融资 6 亿多元!2021 年,美国哈佛大学华人校友 Jeffrey Wang 和室友威尔·布莱克(Will Bryk)创办了一家名为 Exa 的 AI 搜索公司。经过几年的发展,其于当地时间 2025 年 9 月 3 日宣布已筹集到 8500 万美元的 B 轮融资(约等于 6.16 亿人民币),公司估值达到 7 亿美元。本轮融资由 Benchmark 领投,Lightspeed、英伟达和 YCombinator 参投。与此同时,Benchmark 的合伙人彼得·芬顿(Peter Fenton)也将加入 Exa 公司董事会。目前,该公司表示其已经为数千家公司提供网页搜索服务,用户涵盖私募股权公司、咨询公司以及 Cursor、Databricks、Notion 等科技公司。

图 | Jeffrey Wang(来源:资料图)
如前所述,该公司成立于 2021 年,可以说是在“AI 需要搜索引擎”、即在 ChatGPT 面世之前就已经成立。对此,该公司在官方新闻稿中写道:“我们相信,世界需要一个比谷歌更好的搜索引擎,而我们能够做到。”其形容自己的产品定位是:“谷歌搜索之于人类,正如我们之于 AI。”
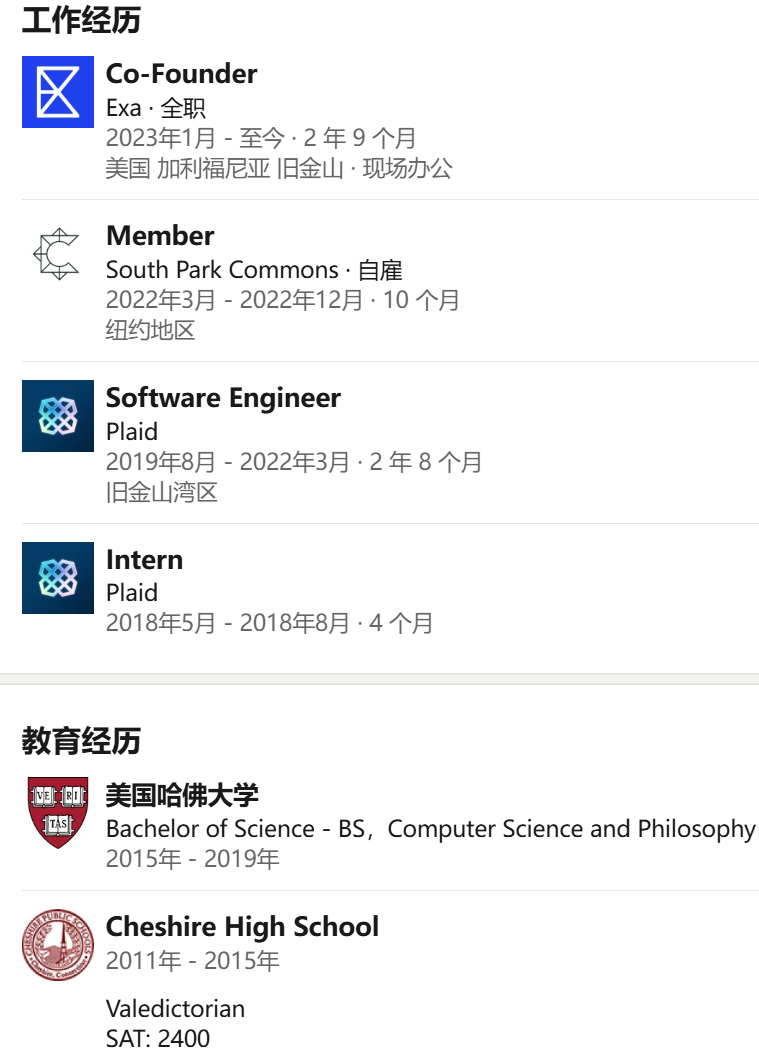
图 | Jeffrey Wang 的学习经历和工作经历(来源:资料图)
公司成立之后,Jeffrey Wang 等人先是购买了一个 GPU 集群,借此构建出一个大规模的索引系统,并尝试了多个新型网络搜索技术。旨在开发一个让用户能以“谷歌无法做到的方式”来控制网络的搜索引擎。比如,用户可以提出这样一个搜索请求:“给我找出所有拥有博客的在纽约的机器学习工程师,并按照经验年限排序。”
2022 年 11 月,该公司推出了第一款搜索引擎产品。两周之后,ChatGPT 横空出世。很快,该公司就收到访问器搜索引擎 API 的请求。之所以会受到这些请求是因为,当时很多公司都开始研发 AI 应用,而这需要先从网络上获取信息。这时,Jeffrey Wang 等人意识到 AI 也需要网络搜索。其还意识到,AI 的网络搜索需求频率很快就会高出人类。
那么,什么是 AI 搜索引擎?和人类一样的是,AI 的“大脑”中也不可能存储世界上所有的信息。无论是了解新闻、代码、论文还是公司数据,它都需要通过网络搜索来获取最新、最全面的信息。但是,AI 毕竟和人类有着本质区别,因此 AI 需要一种新型的搜索引擎。“搜索引擎”这个词语大家并不陌生,人类使用的搜索引擎早在几十年前就已诞生。但是,该公司表示其和公司名字同名的产品 Exa 是一款专门为 AI 设计的搜索引擎。
它具有六个专有特点。
第一个特点是能帮助 AI 获取高质量的知识。AI 要搜索的是最高质量的知识,而不是 SEO 内容或广告内容,否则 AI 就会变得“输入的是垃圾,输出的也是垃圾”。为此,Exa 的排名算法能对高质量知识进行优化。由于这款搜索引擎不会接受外部广告投放,因此不会采取任何不正当的激励措施,故能为 AI 尽可能提供高质量的搜索。
第二个特点是其能让 AI 获得所有需要的内容。AI 所需要的不仅是一篇文章的链接和标题,而是需要尽可能地获得每个结果的信息。而 Exa 能为每个信息都提供完整的页面内容,以便 AI 处理所有必要的信息。
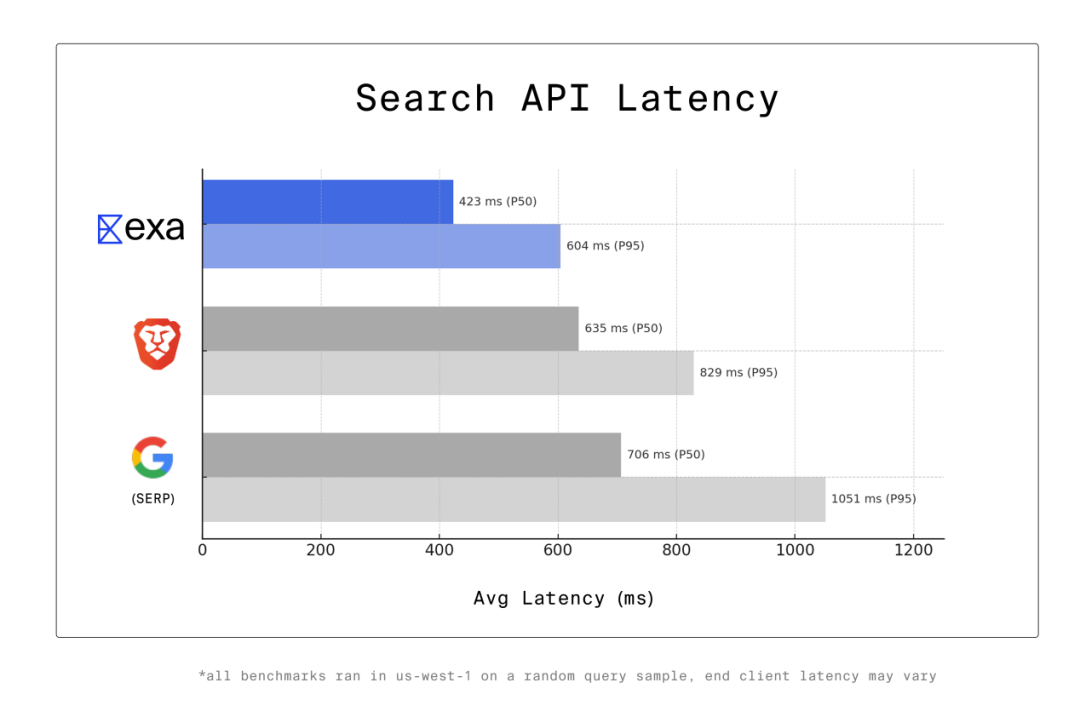
第三个特点是更快速。相比人类,AI 需要更快的搜索速度。与此同时,AI 语音助手等 AI 产品对于延迟非常敏感,甚至说每一毫秒都至关重要。AI 在工作时通常会在单个请求中调用多个工具,而搜索引擎只是其调用的工具之一。那么,在调用多个工具的时候就会积累延迟。Jeffrey Wang 等人认为,要想构建全球最快的搜索 API,就不能成为包装器,即不能在搜索 API 的底层封装谷歌,因为这意味着服务器集群中的浏览器会接受用户查询,并通过在谷歌搜索中进行处理来提供结果。而这需要超过 700 毫秒的中位数延迟(P50,The 50th Percentile Latency),因此其指出任何封装谷歌的搜索 API 的 P50 时间至少为 700 毫秒。AI Agent 会进行大量的搜索调用,如果一个 Deep Research 代理进行 50 次搜索调用,每当每次调用的速度快 200 毫秒,那么就能为真人用户节省 10 秒时间。为了构建“全球最快的搜索 API”,Jeffrey Wang 等人爬取了网络数据,并训练模型进行搜索,以及开发了自己的矢量数据库。通过掌控整个技术栈的每个部分,从而能够缓解延迟。通过此,其构建了一款名为 Exa Fast 的搜索 API,Jeffrey Wang 等人表示其速度低于 450 毫秒。在一项实验中,他们针对美国北加州数据中心的数千次随机查询进行了基准测试,结果发现其网络延迟约为 50 毫秒。
(来源:资料图)
第四个特点是高计算。对于 AI 来说它并不关心延迟,而是只想进行最全面的搜索,对于那些异步应用程序来说更是如此,为此 Jeffrey Wang 等人打造了一款名为 Websets 的高计算搜索产品,并称其是“迄今为止全球最全面的搜索引擎”,能让 AI 获取海量的人员信息、公司信息或其他信息。
第五个特点是可定制。由于每个 AI 应用都有特定的用例,因此如能针对特定应用程序进行搜索定制,效果无疑会更好。而 Exa 这一 AI 搜索引擎基于定制化的理念,可以做到通过排除数千个域名来获取数百个结果,同时也能创建自定义分类器以便在每次搜索时运行。
第六个特点是零数据保留。来自企业的查询数据往往非常敏感,因此企业更倾向于拥有具备零数据保留特点的搜索 API,这意味着 AI 的查询内容永远不会被存储在任何地方。对于实现完全的数据隐私保护的企业来说,零数据处理是一个黄金标准。对于搜索服务商来说,要想提供零数据处理,无论在主服务器还是子处理器中,都绝对不能存储用户的查询数据。Jeffrey Wang 等人在一篇博文中指出,大多数搜索提供商实际上无法提供零数据处理,并指出这也是搜索领域中一个鲜为人知的秘密。之所以会出现这种情况,是因为绝大多数搜索服务商都会在后台抓取谷歌数据。当查询达到搜索服务商时,查询会被路由到全球某个在浏览器中运行谷歌搜索的匿名服务器,然后谷歌搜索结果会被发回给搜索服务提供商。由于谷歌搜索是一个基于用户查询进行训练的消费级搜索引擎,所以它并没有零数据处理。因此,任何以子处理器身份在后台抓取谷歌搜索数据的搜索服务提供商都无法拥有零数据处理能力。而由于 Exa 是从头开始构建的搜索引擎,因此该公司表示它可以为所有产品端点提供零数据保留。为了炼就这一能力,其通过爬取网络数据,训练了专门的 AI 搜索引擎,并通过设计海量数据库来为模型提供服务。这让其不仅能为客户提供准确的搜索结果,还能确保每个查询都保留在零数据处理系统中,当搜索结束之后查询数据就会被删除。
(来源:资料图)
而在未来,Exa 还有着更加辽阔的野望,它希望通过扩大索引能力和处理能力,以便能够收集全球范围内的绝大多数信息。同时,它还计划建设一个比当前大出 5 倍的 GPU 集群,以便开发出来能将全球信息组织起来的新技术,最终它的目标是超越谷歌搜索。

(来源:资料图)
资料显示,作为 Exa 公司联合创始人的 Jeffrey Wang 会说中文,如前所述其本科毕业于美国哈佛大学。毕业之后他曾在美国金融科技公司 Plaid 工作了三年,在那里他主要负责构建数据和网络基础设施。后来,他和大学室友威尔·布莱克(Will Bryk)联合创办了 Exa 公司,并由布莱克担任 CEO。

(来源:资料图)
与此同时,Exa 还有多位华人技术人员。比如,毕业于哈佛大学的 Benjamin Chen、毕业于清华大学姚班的 Hubert Yuan、毕业于美国卡内基梅隆大学的 Zixi An、毕业于美国加州大学伯克利分校的 Felicia M. Tang、博士毕业于美国康奈尔大学的 Benjamin Y Chan 等。

图 | 该公司部分员工(来源:资料图)
未来,Exa 能否实现超越谷歌的梦想?还需让时间来证明一切。