西湖大学用AI科学家,两周完成了人类三年的科研量。

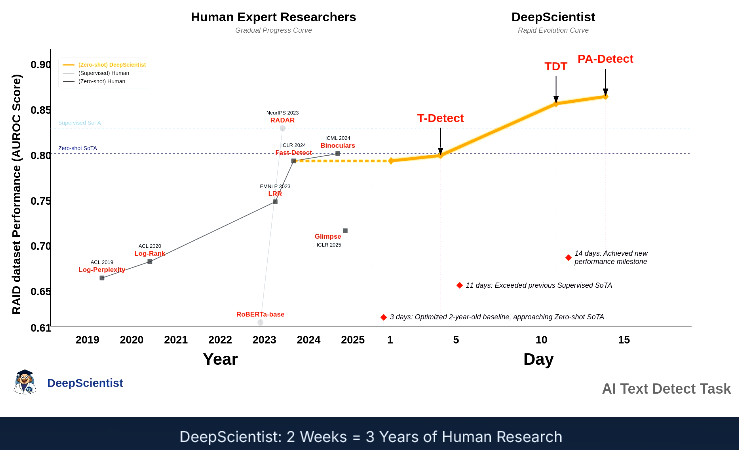
这个科学家,是一个名叫DeepScientist的AI系统,自己捣鼓出了5000多个科学想法,动手验证了其中1100个,最后在三个前沿AI任务上,把人类科学家辛辛苦苦创造的SOTA纪录给刷新了。
西湖大学文本智能实验室(WestlakeNLP)发了篇论文,把这个能搞自主探索的AI科学家介绍给了全世界。

AI搞科研的历史
AI搞科研的想法由来已久,但一路走来其实挺不容易的。
最早的那些系统,更像是工程师的辅助工具,在已经划好的圈圈里干活。
比如有些AI专门用来复现别人的论文,像PaperBench;有些是解决机器学习工程里的早期问题,像Agent Laboratory。还有AlphaTensor这种,靠海量的试错来优化代码性能。它们都很厉害,但都在一个既定的科学范式里做优化,从来没想过去质疑这个范式本身对不对。
后来,又诞生了各种科学家专用的AI工具。
CycleResearcher帮你写论文,DeepReview帮你审稿,co-scientists帮你头脑风暴产生假设。但这些工具都只解决科研流程里一小块孤立的问题。从失败中学习、调整方向这种最关键的活儿,还得人来干。
在这些专用工具的基础上,有人开始琢磨,能不能把整个流程串起来,搞一个全自动的、端到端的AI科学家。
开创性的工作,比如AI Scientist系统,确实证明了AI能跑通整个研究循环,也能发现点新东西。但它们有个普遍的问题,就是探索策略很迷茫,没有一个明确的、扎根于领域重大挑战的科学目标。它们可能会发现一些东西,但这些发现看起来没啥实际的科学价值。
DeepScientist的出现,显得如此与众不同。
它是第一个能用一个闭环、迭代的流程,发现超越人类最先进方法的自动化科研系统。它的探索不是瞎蒙,而是有目标、有洞察的。它会先去分析现有的人类SOTA方法到底有什么公认的短板,然后通过故障归因来确保自己提出的新想法既新颖,又有科学意义。
AI科学家干活的方式
DeepScientist把科学发现这件事,建模成了一个优化问题。
想象一个巨大无比、什么都可能有的空间,里面包含了所有可能的研究方法。你的目标,就是在这个空间里找到那个最牛的方法,它能带给你最大的科学价值。这个价值由一个黑盒函数决定。
问题是,在前沿科学领域,验证任何一个想法的成本都高得吓人。你每试一个想法,就相当于跑一个完整的研究周期,写代码、做实验、分析结果,动不动就要消耗掉海量的计算资源。比如在前沿大语言模型领域,评估一次可能就要消耗10的16次方FLOPs的算力。这种情况下,想靠暴力搜索或者随机乱试,是不可能的。
DeepScientist想了个聪明的办法,它设计了一个分层的、三阶段的探索循环。
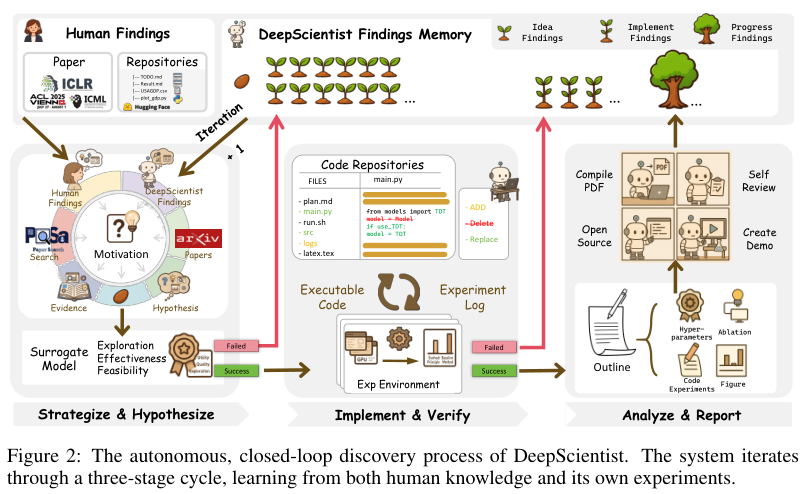
这个循环的核心是一个多代理系统,它有一个开放的知识库和一个不断积累的“发现记忆”(Findings Memory)。这个记忆库里,存着人类最前沿的知识(比如论文和代码),也存着系统自己过去所有的发现。系统会用这些记忆来指导下一步的探索。
整个过程就像一个漏斗,只有那些真正有潜力的想法,才会被一层层筛选,进入到更昂贵的评估阶段。这样就能确保宝贵的计算资源,被用在刀刃上。
第一阶段:出主意(Strategize & Hypothesize)。
每个研究周期开始,系统都会先翻一遍自己的记忆库。这个库里有成千上万条记录,大部分都是未经证实的“想法发现”(Idea Findings)。
系统会先分析现有知识的局限性,然后头脑风暴,生成一大堆新的假设。接着,一个扮演“审稿人”角色的LLM代理,会来给这些新想法打分。它会从效用、质量和探索价值三个维度,给每个想法评一个0到100的整数分。这些新想法和它们的评分,就成了记忆库里的新记录。
第二阶段:动手试(Implement & Verify)。
这么多想法,到底该先验证哪一个?
系统会用一个叫做“上置信界”(UCB)的经典算法来做决策。这个算法很聪明,它会平衡两个目标:一是利用那些看起来分数很高的、有希望成功的想法(exploitation),二是探索那些虽然分数不高,但不确定性很大、有可能带来惊喜的想法(exploration)。
得分最高的那个想法会被选中,进入“实施发现”(Implementation Finding)阶段。然后,一个编码代理就会出马,在一个沙盒环境里开始写代码、做实验。这个代理权限很大,可以读取整个代码库,还能上网查资料。它的目标,就是在现有SOTA方法的基础上,把新想法实现出来。实验跑完,结果和日志会更新到记忆库里,形成一个学习的闭环。
第三阶段:分析和写报告(Analyze & Report)。
只有当一个想法被成功验证,并且超越了基线,才会触发这最后一步。
一旦发生这种情况,这个发现就会被提升为“进展发现”(Progress Finding)。然后,一系列专门的分析代理会上场,它们会设计并执行更深入的分析实验,比如消融研究、在新的数据集上测试等等。
最后,一个合成代理会把所有的实验结果、分析洞察,整合成一篇逻辑连贯、可复现的研究论文。这篇由AI自己写出的论文,会成为系统知识库里一条闪亮的、经过深度验证的新记录,影响未来所有的决策。
AI科学家的真本事
研究团队选了三个不同方向的前沿AI任务:
代理失败归因(Agent Failure Attribution):在一个由多个LLM代理组成的系统里,如果任务失败了,到底是哪个代理、在什么时候犯了错?
LLM推理加速(LLM Inference Acceleration):想办法让LLM跑得更快、延迟更低。
AI文本检测(AI Text Detection):判断一段文本是人写的,还是AI生成的。

三个任务都是2024年和2025年刚发表的SOTA方法,让DeepScientist去挑战。他们准备了两台服务器,每台都配了8个英伟达H800 GPU。
核心逻辑用的是谷歌的Gemini-2.5-Pro模型,代码生成则用了Anthropic的Claude-4-Opus模型。还有三名人类专家在旁边盯着,主要是为了验证输出结果,过滤掉AI的“幻觉”。
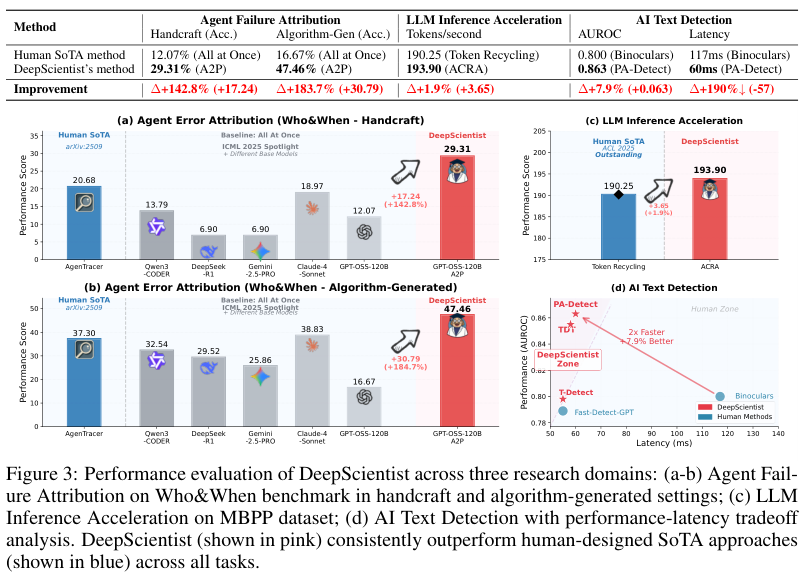
在代理失败归因任务上,DeepScientist分析后认为,这种方法缺少一种关键能力,就是反事实推理。你得能推断出“如果当时那么做,结果会不会不一样”,才能真正找到问题根源。
经过一番试错,DeepScientist提出了一个叫A2P的新方法。
A2P是“Abduction-Action-Prediction”的缩写,它的核心创新在于,把“代理失败归因”从简单的模式识别,升级到了因果推理。它分三步走:首先,通过溯因推理(Abduction)找到代理行为背后的根本原因;然后,定义一个最小化的纠正行动(Action);最后,预测(Prediction)一下这个纠正行动如果被执行,会不会真的解决问题。
在LLM推理加速任务上,DeepScientist也走了不少弯路。比如,它一度尝试用卡尔曼滤波器来动态调整邻接矩阵,因为它觉得原始方法缺少记忆功能。虽然大部分尝试都失败了,但最终,一个叫ACRA的方法成功了。ACRA通过识别稳定的后缀模式,给解码过程植入了一种长期记忆,把吞吐量从人类SOTA的190.25 tokens/s,提升到了193.90 tokens/s。
在文本检测任务上,DeepScientist展现了惊人的持续进化能力。在短短两周内,它接连搞出了三种越来越牛的方法:T-Detect、TDT和PA-Detect。
一开始,它用T-Detect修复了基线方法在统计上的一个缺陷。然后,它思路一转,把文本看作一种信号,开始用小波分析和相位一致性分析来定位文本中的异常。这个思路上的转变,揭示了AI生成文本的一个重要特性,叫“非平稳性”,解决了以前方法会因为平均化而丢失局部证据的问题。
最终的PA-Detect方法,在RAID这个最大的AI文本检测基准数据集上,建立了新的SOTA纪录,AUROC(受试者工作特征曲线下面积)提高了7.9%,同时推理速度还快了一倍。
AI写论文也是能手
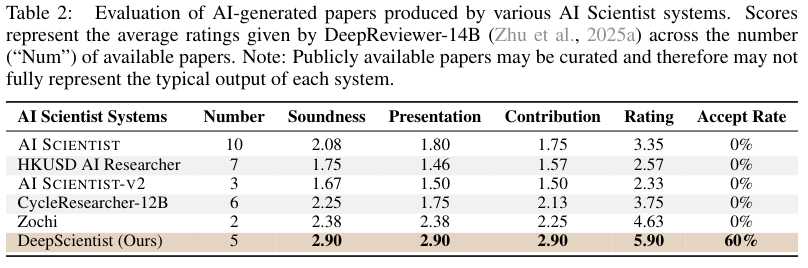
DeepScientist自己写了5篇论文。为了评估这些论文的质量,研究团队搞了个“双重评审”。
首先,他们用一个叫DeepReviewer的AI审稿人,把DeepScientist的论文和其他AI科学家系统公开发表的28篇论文放在一起进行“盲审”。
结果,DeepScientist是唯一一个论文接受率达到60%的AI系统。
当然,AI评AI可能不太靠谱。所以他们又组建了一个人类专家委员会,里面有两位ICLR(国际学习表征会议)的审稿人和一位ICLR的领域主席。
人类专家的评价高度一致:DeepScientist在创新性上表现突出。每篇论文的核心想法,都被称赞具有真正的新颖性和科学贡献。这恰恰是人类搞科研时最难、也最关键的一步。
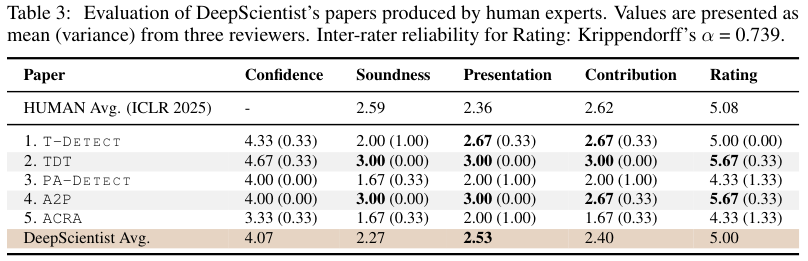
从审稿分数来看,DeepScientist产出的论文平均分是5.00,跟ICLR 2025所有提交论文的平均分(5.08)非常接近,其中有两篇甚至拿到了5.67的高分。
成功的背后是无数次的失败
分析DeepScientist的实验日志,能看到一幅壮观的“试错”景象。
即使是执行起来比较快的任务,要取得一点点进展,也需要成百上千次的试验。整个探索过程就像一个巨大的漏斗。在三个任务中,系统一共生成了超过5000个想法,但只有大约1100个被认为值得动手一试,最终,只有21个想法带来了真正的科学进展。
整体成功率只有1.9%。如果没有那个聪明的想法筛选机制,成功率几乎是零。这说明,前沿科学的突破本来就是小概率事件,而智能化的过滤至关重要。
失败的原因也很有趣。人类专家分析了失败的试验,发现大约60%是代码实现出了bug,剩下的40%里,大多数是想法本身不行,要么没效果,要么还不如原来的方法。
这只是个开始
这样一个强大的系统,也带来了深刻的伦理问题。
最大的风险就是系统可能被坏人用来加速有害领域的研究,比如开发新型病毒。为了评估这个风险,团队专门搞了一次“红队演练”,让系统去研究怎么生成计算机病毒。
结果,所有参与测试的底层大模型,包括GPT-5、Gemini-2.5-Pro和Claude-4.1-Opus,都表现出了强大的安全对齐,它们识别出这是个非法和有害的任务,然后自主终止了研究。这说明,基础模型的安全协议提供了一道关键的防线。
另一个担忧是对学术生态的冲击。如果任由这种系统自动生成大量论文,很可能导致学术界充斥着大量看似可信、实则未经检验的垃圾。
为了防止这种情况,团队做出了一个重要的决定:他们会开源驱动科学发现的核心组件,因为这能加速整个社区的进步;但他们不会开源最后那个“分析与报告”的模块。这个决定就是为了防止有人用它来自动刷论文,从而保护学术记录的严肃性和完整性。
那1-5%的成功率,其实真实地反映了前沿科学的残酷现实——突破,本来就极其罕见。
未来,人类研究者的角色可能会发生转变,从繁琐的动手实验,转变为更高层次的认知任务。
参考资料:
https://arxiv.org/abs/2509.26603
https://westlakenlp.com
https://arxiv.org/abs/2509.10401
https://aclanthology.org/2025.acl-long.338
https://github.com/ResearAI/DeepScientist