
编译 | 程茜
编辑 | 云鹏
智东西10月20日消息,百度10月16日开源的多语言文档解析模型PaddleOCR-VL,连续三天霸榜Hugging Face趋势榜第一。
PaddleOCR-VL能识别109种语言的文本、表格、公式和图表等复杂元素,包括全球主要语言以及俄语、阿拉伯语和印地语等多种语言。在最新的用于评估现实场景中多样化文档解析性能的基准测试工具OmniDocBench榜单中,PaddleOCR-VL以92.6综合得分拿下全球第一,并且在OmniDocBench v1.5、OmniDocBench v1.0均是第一。
PaddleOCR-VL在OmniDocBench v1.5上实现了整体、文本、公式、表格和阅读顺序的SOTA性能,在所有关键指标上均超越现有流水线工具、通用VLM和其他专用文档解析模型。
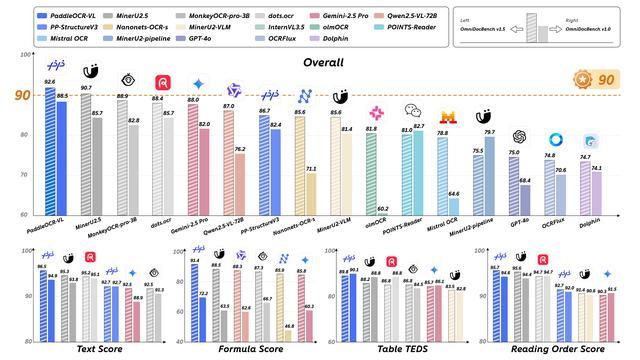
论文中提到,PaddleOCR-VL在文档解析任务中实现了最佳性能,其擅长识别复杂的文档元素,例如文本、表格、公式和图表,适用于手写文本和历史文档等各种具有挑战性的内容类型。
百度给出的官方手写文本示例中,图片中文字写作相对规范,有较少不清晰文字,模型识别结果中错误较少。

手写文本(左)、识别结果(右)
随后智东西上传了一张苏轼手札,相对上面的图片仅凭肉眼很难辨认清楚且有较多繁体字,模型的识别结果中错误较多。

手写文本(上)、识别结果(左下)、古诗文网原文(右下)
该方案的核心组件PaddleOCR-VL 0.9B基于NaViT风格的视觉编码器和ERNIE-4.5-0.3B语言模型构建,具有快速推理和低资源消耗的特点,适合实际部署。
在训练数据方面,研究人员采用了开源数据集、合成数据集、网络可访问数据集和内部数据集。同时,其开发了高质量训练数据构建流程,通过公共数据采集和数据合成收集了超过3000万个训练样本,以基于专家模型的识别结果指导通用大型模型进行自动标注。
一、复杂公式、多语言识别准确,不清晰、反光文字出现少量错误
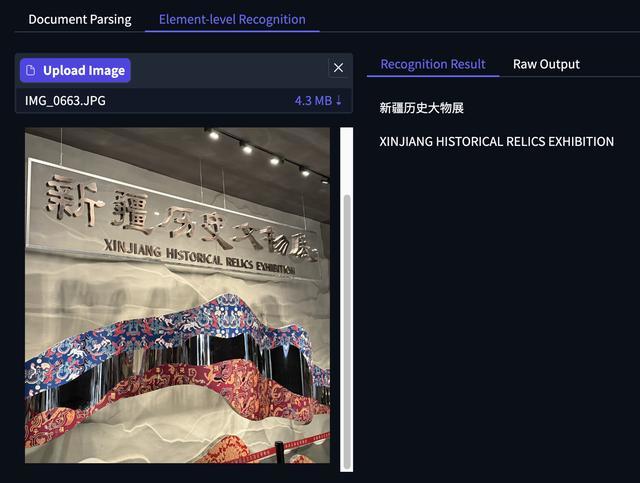
智东西体验了PaddleOCR-VL文档解析能力和元素级识别能力,模型在中英文、韩语以及复杂公式、图表等方面识别准确率都很高,在图片有反光、不清晰时出现极个别错误。
智东西上传了PaddleOCR-VL论文的首页,识别结果中,模型自动识别出了链接、邮箱地址,并准确将图表进行了切分。
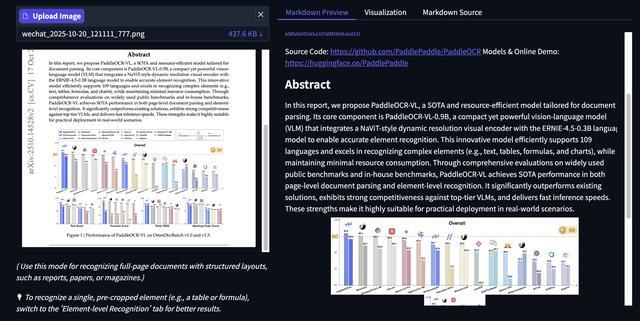
下面是一道物理题目,模型自动识别出了页眉部分的标语,小标题、图表、复杂公式识别准确。
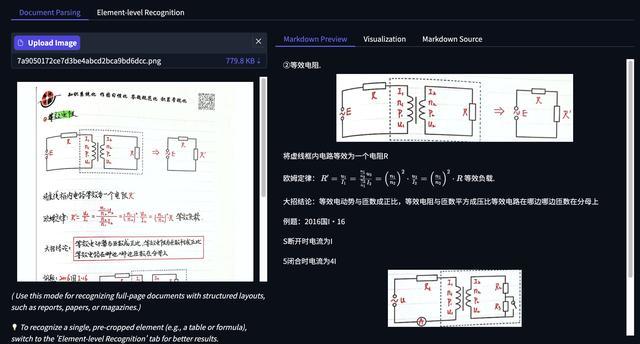
元素级识别能力中,先来看图表识别,图表的每一部分内容及数字表达都清晰准确。
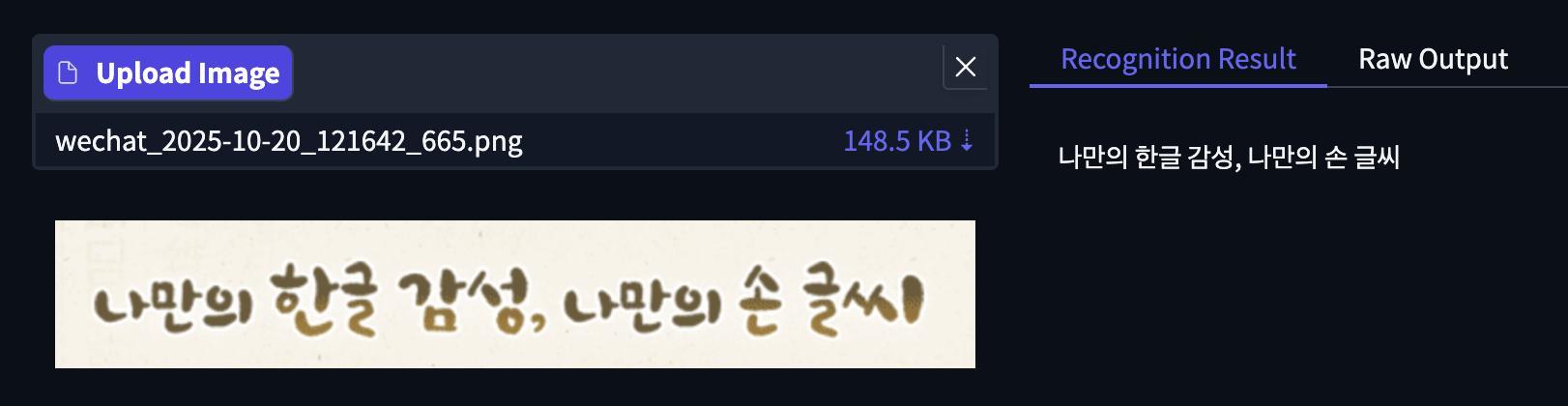
文字识别中,智东西上传了中文、韩语。下面是一张手写体的韩语图片,模型识别结果准确。
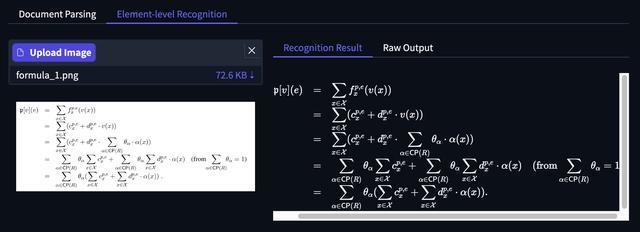
公式识别方面,智东西上传了一张包含公式的图片,模型将复杂公式的细节都进行了准确识别。
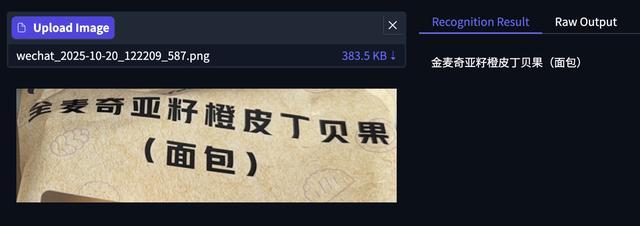
其次为画面不清晰的中文识别,可以看到下面包装袋左上角有褶皱,模型错误将第一个“全”字识别为“金”,其余文字均准确。
下面图片的拍摄角度是侧面,因此右侧文字有反光,模型错误将“文”识别为“大”,但后面的“物”即使有反光+变体,模型的识别结果也没有出错,同时下方的英文识别也完全正确。
二、文档识别先前技术有弊端,百度提出基于视觉语言模型的文档解析方案
文档作为核心信息载体,其复杂性和数量呈指数级增长,使得文档解析成为一项不可或缺的关键技术。文档解析的主要目标是深入理解文档布局的结构和语义,包括识别不同的文本块和列,区分公式、表格、图表和图像,确定正确的阅读顺序,以及检测关键元素等。
但现代文档较为复杂,其包含密集文本、复杂表格或图表、数学表达式、多种语言和手写文本。因此这一领域目前有两种技术方法,一是采用基于专门的模块化专家模型的流水线方法,但这种方法在处理高度复杂文档时,会受到集成复杂性、累积误差传播和固有限制的阻碍;二是利用多模态模型的端到端方法简化工作流程并实现联合优化。然而这些方法通常难以保持正确的文本顺序,在面对冗长或复杂的布局时甚至会产生幻觉,同时还会为长序列输出带来大量的计算开销。
基于此,百度研究人员推出基于视觉语言模型的高性能、资源高效的文档解析解决方案PaddleOCR-VL,该方案将布局分析模型与视觉语言模型PaddleOCR-VL-0.9B相结合。
首先,PaddleOCR-VL会进行布局检测和阅读顺序预测,获取文本块、表格、公式、图表等元素的位置坐标和阅读顺序。论文中提到,与依赖基础和序列输出的多模态方法相比,PaddleOCR-VL的方法推理速度更快、训练成本更低,并且更易于扩展新的布局类别。
随后,这一方案会根据元素位置对其进行分割,并输入PaddleOCR-VL-0.9B进行识别。PaddleOCR-VL-0.9B专为资源高效的推理而设计,擅长文档解析中的元素识别。其通过将NaViT风格的动态高分辨率视觉编码器与轻量级ERNIE-4.5-0.3B语言模型相结合,提升了模型的识别能力和解码效率。
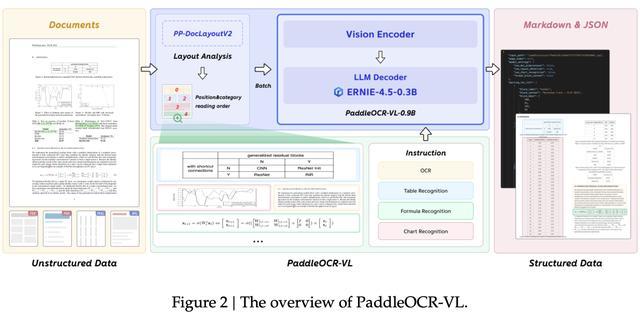
PaddleOCR-VL概览
为了训练强大的多模态模型,研究人员开发了高质量训练数据构建流程,其通过公共数据采集和数据合成收集了超过3000万个训练样本,以基于专家模型的识别结果指导通用大型模型进行自动标注。同时进行数据清理,以去除低质量或不一致的标注。此外,研究人员还设计了评估引擎,通过评估集合将每个元素划分为更详细的类别,基于此分析当前模型在不同场景下的训练性能。
最后,其还会结合少量极端情况进行人工标注,最终完成训练数据的构建。
三、文档解析、元素识别均采用两阶段训练方案,训练数据来源有四类
PaddleOCR-VL将文档解析任务分解为两个阶段:第一阶段PP-DocLayoutV2负责布局分析,定位语义区域并预测其阅读顺序;第二阶段PaddleOCR-VL-0.9B利用这些布局预测对各种内容进行细粒度识别。最后,轻量级的后处理模块将两个阶段的输出聚合在一起,并将最终文档格式化为结构化的Markdown和JSON格式。
在用于版式分析的PP-DocLayoutV2的训练方案方面,研究人员采用PP-DocLayoutV2模型来执行布局元素定位、分类和阅读顺序预测。PP-DocLayoutV2通过添加一个指针网络(Pointer Network)来扩展RT-DETR(基于Transformer的实时目标检测模型),该网络负责预测检测到的元素的阅读顺序。
其训练过程采用两阶段策略:首先训练核心RT-DETR模型进行布局检测和分类,然后冻结其参数,并单独训练指针网络进行阅读顺序预测。
第一阶段研究人员遵循RT-DETR的训练策略,使用PP-DocLayout_Plus-L预训练权重初始化模型,并在其自建的20000多个高质量样本数据集上训练100个epoch;第二阶段,模型输出一个表示任意两个元素之间成对排序关系的矩阵,并根据真实标签计算广义交叉熵损失,其使用恒定学习率2e-4和AdamW优化器训练200个epoch。
在用于元素识别的PaddleOCR-VL-0.9B训练方案方面,PaddleOCR-VL-0.9B包含三个模块:视觉编码器、投影仪和语言模型。其采用预训练模型的后自适应策略,视觉模型使用Keye-VL的权重初始化,语言模型使用ERNIE-4.5-0.3B的权重初始化。
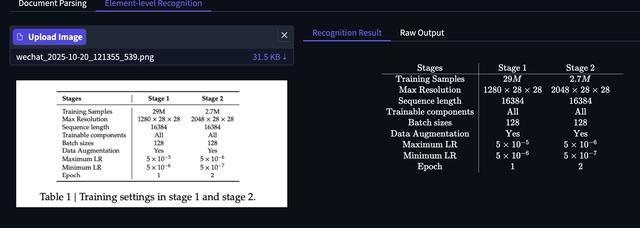
其训练方法分为两个阶段,第一阶段初始阶段专注于预训练对齐,模型学习将图像中的视觉信息与相应的文本表示关联起来,这一关键步骤基于包含2900万个高质量图文对的海量数据集进行;第二阶段预训练完成后,模型将进行指令微调,使其通用的多模态理解适应特定的下游元素识别任务,此阶段使用270万个样本数据集。
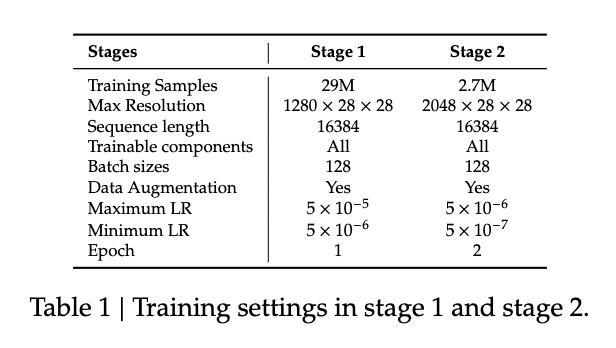
第1阶段和第2阶段的训练设置
研究人员采用的数据主要有四个来源:开源数据集、合成数据集、网络可访问数据集和内部数据集。
获取原始数据后,研究人员利用自动化数据标注流程进行大规模标注。首先其使用专家模型PP-StructureV3对数据进行初步处理,生成可能存在误差的伪标签;随后通过提示工程创建包含原始图像及其相关伪标签的提示,并将其提交给更先进的多模态大型语言模型ERNIE-4.5-VL和Qwen2.5VL。
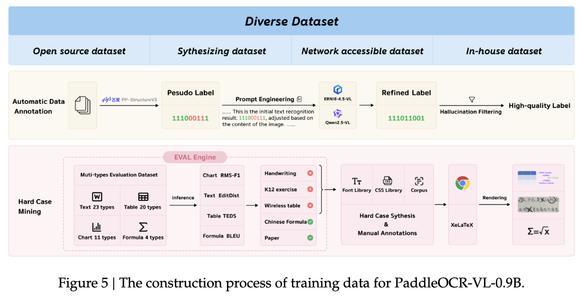
PaddleOCR-VL-0.9B训练数据的构建过程
这些模型通过分析图像内容来细化和增强初始结果,从而生成更优质的标签。最后,为了确保标签的质量,系统会执行幻觉过滤步骤,消除大型模型生成的潜在错误内容。
四、PaddleOCR-VL在文档解析能力测试集中,达到SOTA
为了评估PaddleOCR-VL的有效性,研究人员对其页面级文档解析和元素级识别进行了性能比较。
首先是页面级文档解析,研究人员使用OmniDocBench v1.5、OmniDocBench v1.0、olmOCR-Bench三个基准对PaddleOCR-VL的端到端文档解析能力进行了评估。
OmniDocBench v1.5是全面评估文档解析能力的测试集,PaddleOCR-VL在OmniDocBench v1.5上实现了整体、文本、公式、表格和阅读顺序的SOTA性能,在所有关键指标上均超越现有流水线工具、通用VLM和其他专用文档解析模型。
具体来看,PaddleOCR-VL模型取得了92.56的综合最高分,超过了排名第二的MinerU2.5-1.2B(90.67)。PaddleOCR-VL在子任务中取得了新的SOTA成绩,包括最低的Text-Edit距离、最高的Formula-CDM分数以及Table-TEDS、Table-TEDS-S。论文提到,这表明该模型在文本识别、公式识别和复杂表格结构分析方面拥有较高准确率。
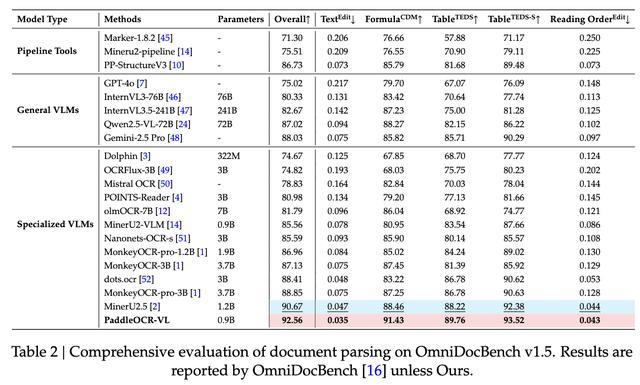
OmniDocBench v1.5文档解析综合评估
OmniDocBench v1.0专门用于评估现实世界的文档解析能力。PaddleOCR-VL在OmniDocBench v1.0上实现了几乎所有指标的总体、文本、公式、表格和阅读顺序的SOTA性能。
PaddleOCR-VL平均整体编辑距离为0.115。模型在中文和英文文本编辑距离方面分别取得了SOTA最佳成绩(0.062)和相当的SOTA最佳成绩(0.041)。不过在英文表格TEDS中,该模型仅为88分,论文提到其原因是OmniDocBench v1.0中拼写错误相关的标注错误。
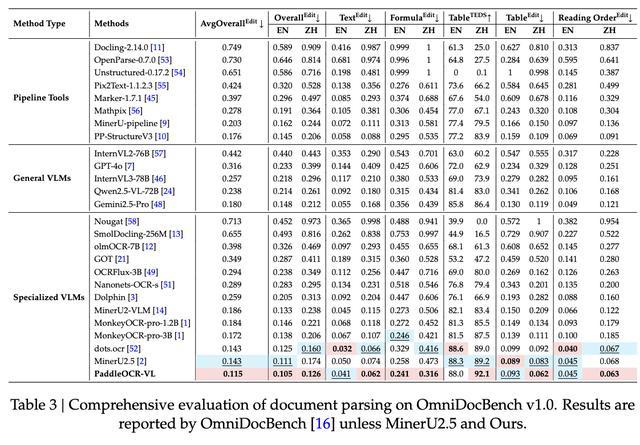
OmniDocBench v1.5文档解析综合评估
在阅读顺序编辑距离方面,该模型在中文中取得最佳成绩0.063,在英文中取得了相当的SOTA最佳成绩0.045。
olmOCR-Bench主要通过简单、清晰且机器可验证的单元测试来评估工具和模型。PaddleOCR-VL在olmOCR-Bench评测中取得了80.0±1.0的最高总分,在ArXiv(85.7)、页眉和页脚(97.0)方面领先,并在多列文本(79.9)和长小文本(85.7)方面排名第二。
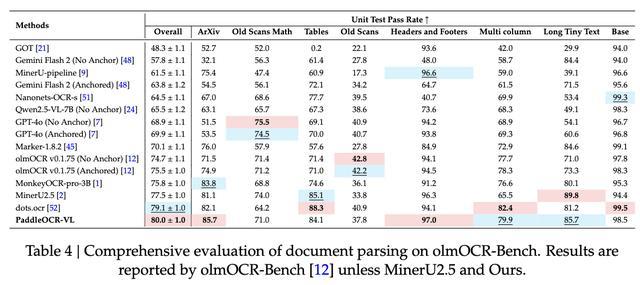
olmOCR-Bench文档解析综合评估
其次是元素级评估。在文本识别中,PaddleOCR-VL几乎在OmniDocBench-OCR-block评估的所有类别中都实现了最低的错误率;百度内部自建的文本评估数据集,模型在多语言指标、文本类型指标中都展现出较高的准确率。
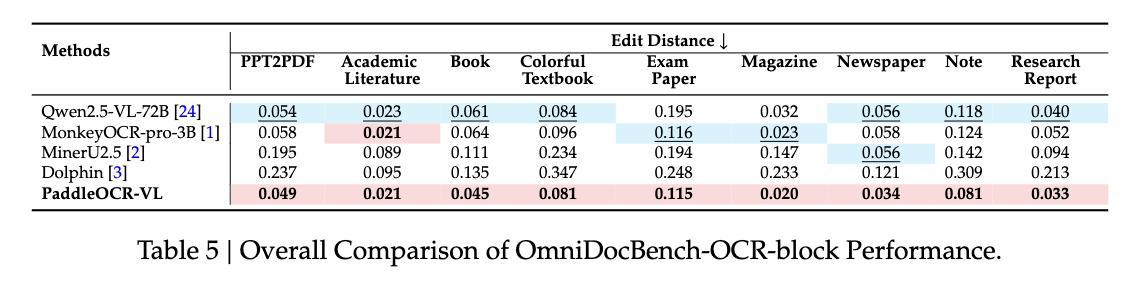
OmniDocBench-OCR-block性能的总体比较
Ocean-OCR-Handwritten是一个行和段落级别的手写评估数据集,模型在英文中实现了0.118的最佳编辑距离,并在F1得分、精确度、召回率、BLEU和METEOR方面表现出色,模型在中文中编辑距离为0.034。
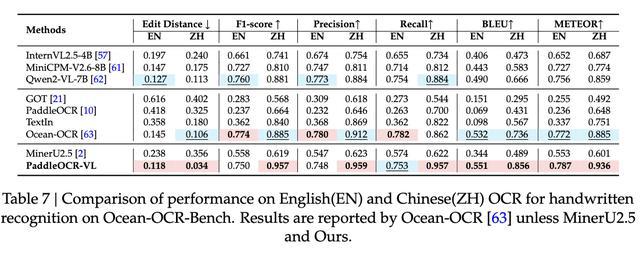
Ocean-OCR-Bench上英文和中文OCR手写识别性能比较
表格识别方面,PaddleOCR-VL在OmniDocBench-Table-block基准测试中领先,超越Seed1.6等模型;在百度自建的表格评估数据集上,模型在总体TEDS、结构TEDS、总体编辑距离和结构编辑距离方面均取得了最高分。公式识别方面,模型在OmniDocBench-Formula-block获得最佳的CDM得分0.9453;图表识别,在百度内部数据集上,PaddleOCR-VL不仅优于专业的OCR VLM,甚至超越了一些72B级别的多模态语言模型。
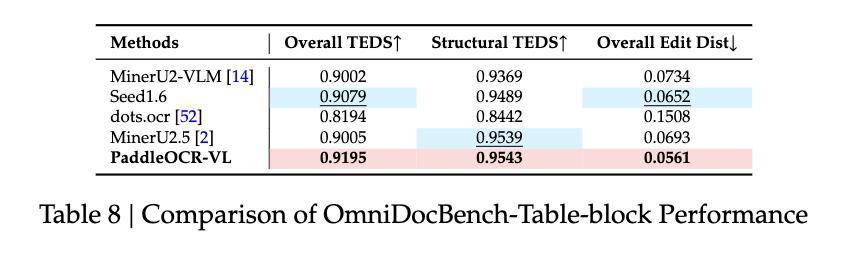
OmniDocBench-Table-block性能比较
推理性能方面,研究人员在OmniDocBench v1.0数据集上测量了端到端推理速度和GPU使用情况,并在单个NVIDIA A100 GPU上以512个批次处理PDF文件。PaddleOCR-VL在处理速度和内存效率方面均展现出明显且一致的优势。与领先的基准MinerU2.5相比,部署vLLM后端后,其页面吞吐量提高了15.8%,token吞吐量提高了14.2%。此外,PaddleOCR-VL GPU内存占用比dots.ocr减少了约40%。
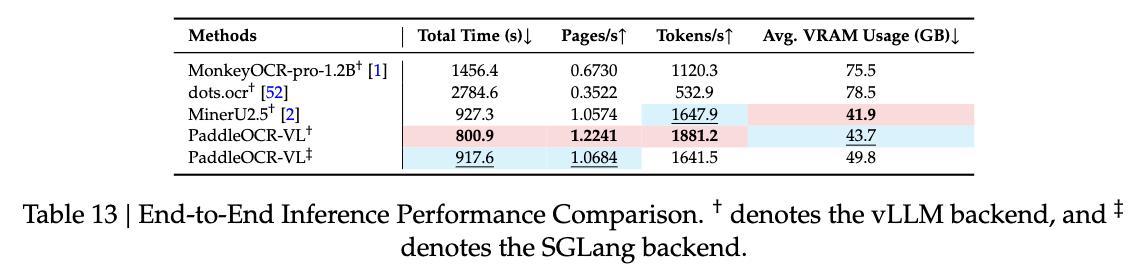
端到端推理性能比较
结语:或加速复杂文档信息高效提取
研究人员基于PaddleOCR-VL增强了模型的识别能力和解码效率,并在保证识别高精度的同时减少计算需求,使其非常适合高效实用的文档处理应用程序。
PaddleOCR-VL广泛的多语言支持和强大的性能有望推动多模态文档处理技术的应用和发展,或将显著提升RAG系统的性能和稳定性,使研究人员从复杂文档中提取信息更加高效,从而为未来的AI应用提供更可靠的数据支持。