让LLM扔块石头,结果它发明了投石机?
大模型接到任务:“造一个能把石头扔远的结构。”
谁成想,它真的开始动手造了,在一个真实的物理仿真世界里,一边搭零件,一边看效果,一边修改。
最后,它造的投石机,把石头扔了出去。
这就是来自港中大(深圳)、港中大的研究团队(Wenqian Zhang, Weiyang Liu, Zhen Liu)带来的最新研究——《Agentic Design of Compositional Machines》。
他们推出了一个叫BesiegeField的新平台,它就像一个给大模型的“机械工程师训练场”,专门测试AI能不能像人一样,从零开始设计并造出能动的、有功能的复杂机器。
这还没完。BesiegeField支持上百次的并行实验,一旦引入强化学习(Reinforcement Learning),大模型就能“自我进化”:从反馈中调整策略,逐步学会结构设计的物理逻辑,最终学会如何“造出能动的结构”。
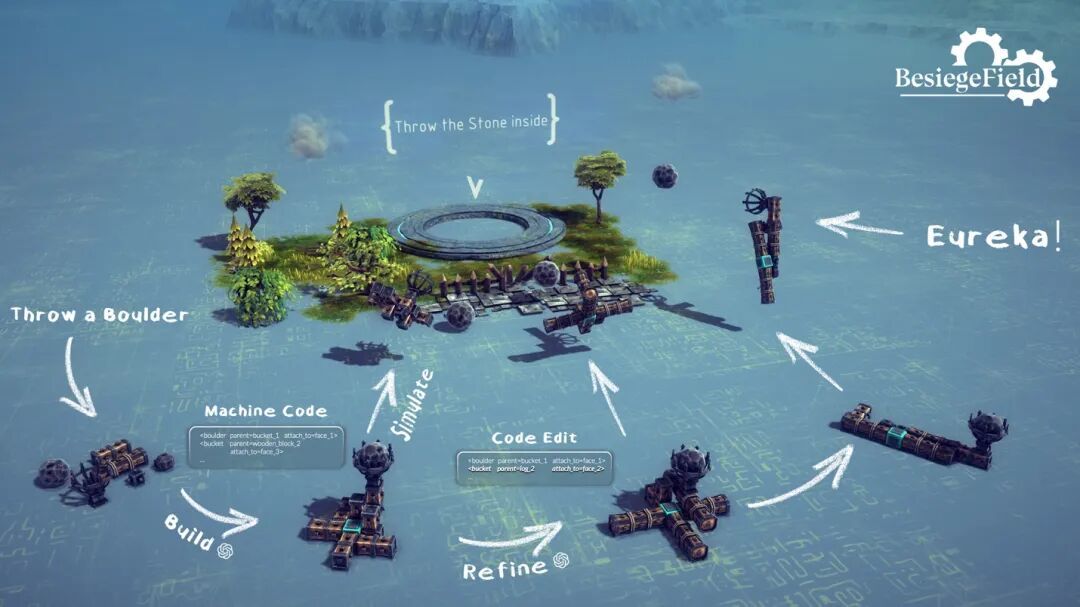
大模型怎么写出一个机械结构
首先得明确,这不是让大模型去画CAD图,它也控制不了三维细节。研究者提出了一种叫“组合式机械设计”(Compositional Machine Design)的方法。
说白了,就是把机械结构限定在“用标准零件组装”这个范围里。每个零件(比如支架、关节)都有标准尺寸和接口,大模型只需要决定:
用哪些零件
它们之间怎么连
这样,复杂的设计就被简化成一个“离散结构组合问题”。到底好不好用?能不能动?稳不稳?交给物理仿真去验证。
为了让模型好理解和修改,研究者用了一种类似XML的“结构化表示机制”,设计机械就变成了一种语言模型擅长的结构生成任务。

一个自进化训练场
上面说的这一切,都发生在BesiegeField这个仿真平台里。它跑在Linux集群上,能同时跑几百个机械实验,并给到完整的物理反馈——比如速度、受力、能量变化、投掷距离、稳不稳定、机械损坏度等等。
这些反馈不仅能验证设计,还能作为强化学习的“奖励信号”,指导模型改进策略。
在这个平台里,模型的设计形成了闭环:生成 → 仿真 → 拿反馈 → 调整 → 再来一次。
就算不更新模型参数,它也能靠反馈优化输出;如果引入强化学习,模型就能通过这些量化的奖励信号,系统性地提升设计能力和成功率。
平台还设计了一系列从易到难的任务,比如直线行驶、投掷、抓取,甚至还有过障碍、地形坡度、穿环投掷等更复杂的场景,构成了一个多样化的实验空间。
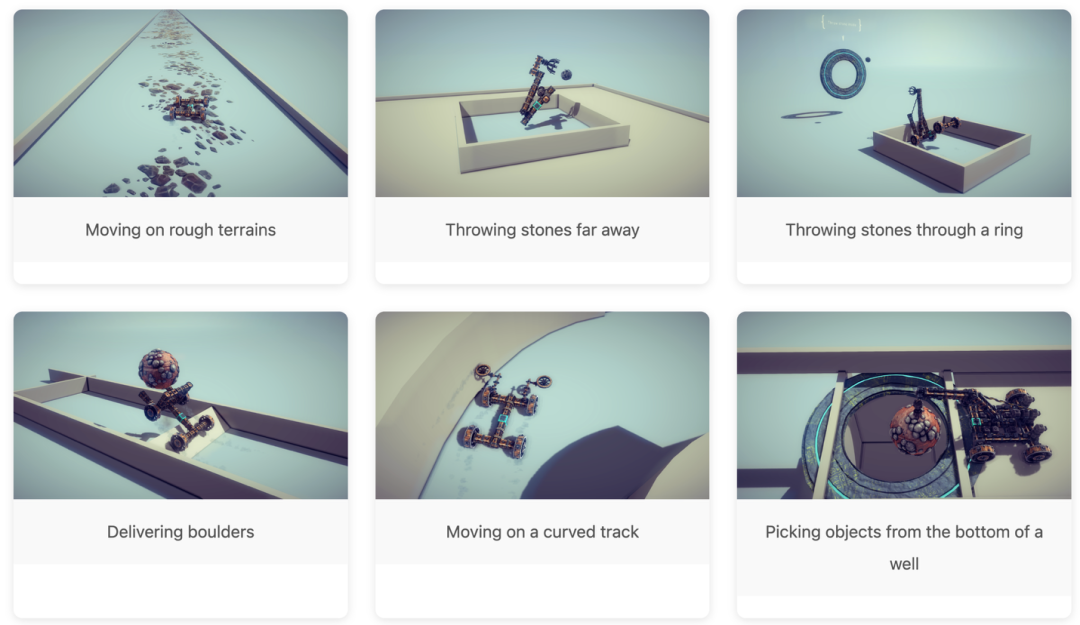
为什么造机器这么难
造机器的挑战,不在于零件多少,而在于它们能不能“在动态中协同工作”来完成复杂功能。
拿投石机来说,配重、支点、发射臂必须在关键时刻协同发力,才能把能量精准地扔出去。
只要一个地方偏差,整个机器就可能失效:没配重,打不出去;缺支点,原地转圈;少了杠杆,石头飞不起来。

这些问题,只有在真实仿真中才能被发现,也只有这样,模型才能一步步搞懂“结构到底是怎么动起来的”。
差距有多大?人类设计的投石机能投近200米,而大模型设计的,常常连30米都到不了。
这其中,差距就在于对“结构协同”和“发力效率”的理解。
这也是BesiegeField要解决的核心问题——让它懂得结构之间“如何协同去完成任务”。

模型真学会造结构了吗
为了解决单个模型“想不明白”的难题,研究团队构建了一套“智能体工作流”(Agentic Workflow),让多个AI协作。
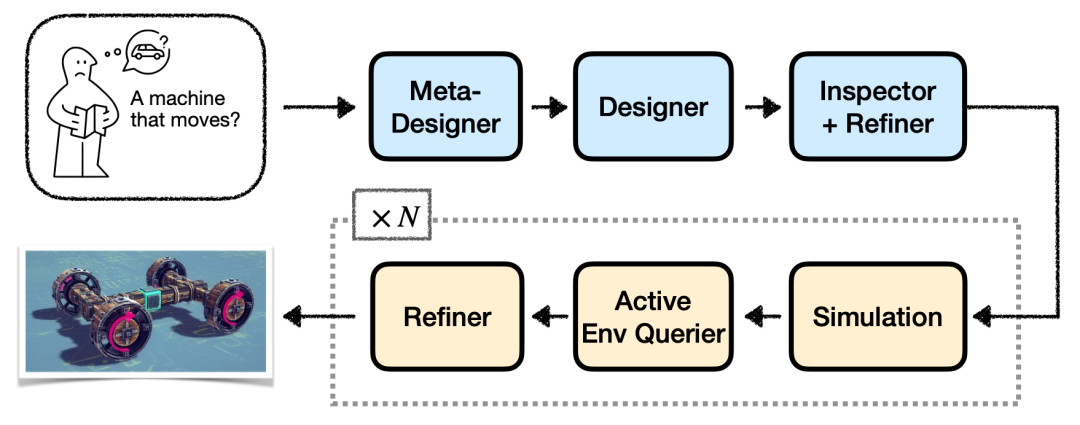
这套系统里有不同角色:
总设计师(Meta-Designer): 负责拆解任务。
结构设计师(Designer): 搭建初始方案。
审查员(Inspector + Refiner): 检查结构和连通性。
反馈查询员(Active Env Querier): 跑仿真并从大量反馈数据内抽取对任务最有用的信息报告。
分析/优化员(Refiner): 解读反馈,提出修改。
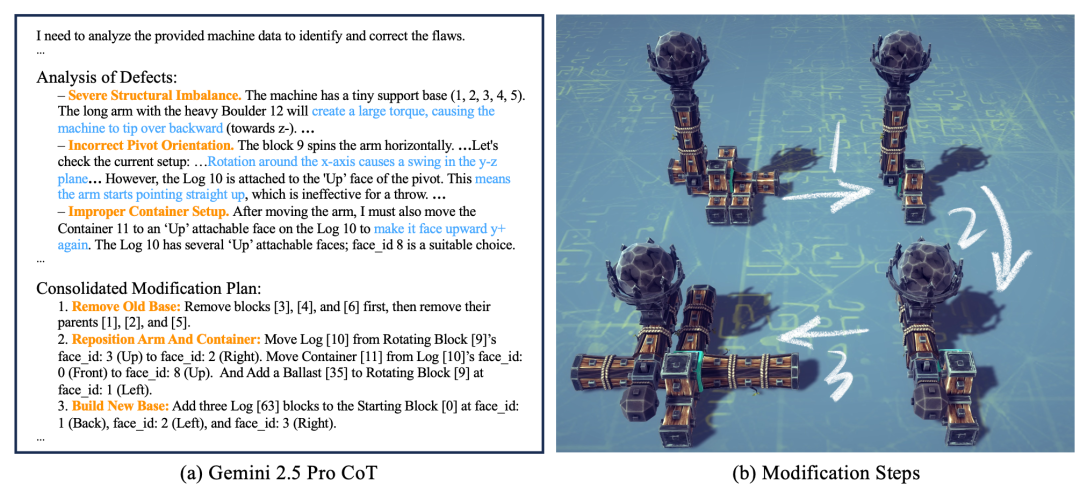
团队测试了多个主流模型,发现在这套工作流下,Gemini 2.5 Pro的表现很突出。

比如在优化投石机时,Gemini 2.5 Pro能根据仿真反馈,识别出“底座太小导致结构失衡”、“旋转轴方向错误导致无法发力”等问题,并提出“移除旧底座”、“重新定位手臂和容器”、“构建新底座”等修改方案。
对比表格显示,这套“多角色分层设计”(Hierarchical Design)策略,在投石机(Catapult)和小车(Car)任务上,其平均分(Mean)和最高分(Max)都显著优于以Gemini为代表的部分“单一模型”或简单的“迭代修改”策略。
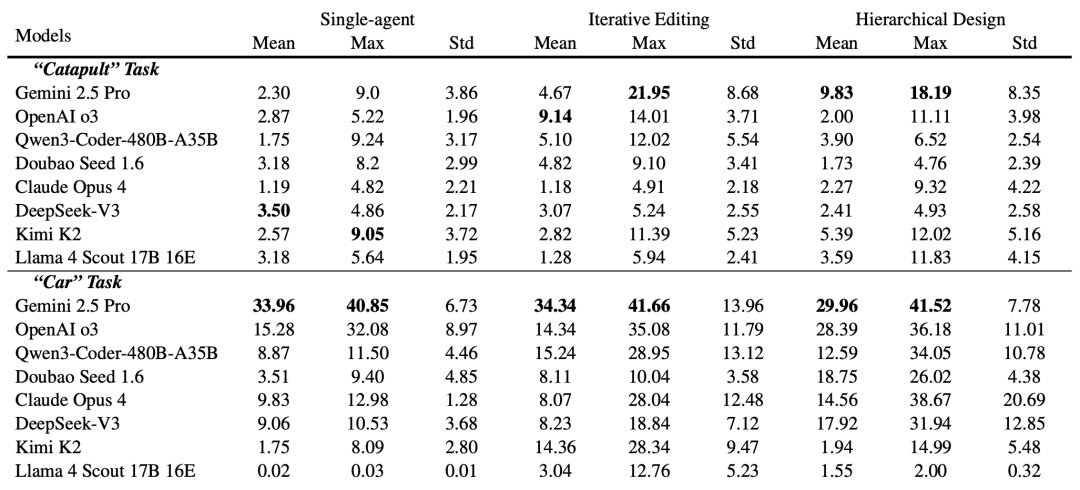
关键这些成果是模型自己在真实反馈里逐步学会调整的。
怎么让AI越造越聪明?
有了工作流还不够,还得让模型能“自我进化”。研究团队引入了强化学习(RL),具体用了一种叫RLVR(基于可验证反馈的强化学习)的策略。
BesiegeField的仿真反馈就是现成的“奖励信号”(Reward):比如投掷距离多远?能不能成功执行任务?能运行多久?
研究团队用了Pass@k Training方法(即在k次尝试中选奖励最大的那个样本作为训练信号),对Qwen2.5-14B-Instruct这个模型进行持续微调。
效果很明显。随着迭代次数增加,模型设计的结构越来越好,投掷距离也越来越远。

定量数据也显示,在“Cold-Start + RL”(用少量好例子启动+强化学习)的策略下,模型在小车任务上的最高分达到了45.72,投石机任务的平均分和最高分也都是最优的。

这是首次证明,LLM确实能借助RL,在仿真反馈中持续提升机械设计能力。
AI创造力的新边界
总的来说,BesiegeField带来的不只是一个仿真平台,更像是一种新的“结构创造范式”。
它把复杂的机械设计,转变成了一个AI擅长的“结构化语言生成任务”;
它提供了一个闭环,让模型能在真实的物理反馈中,学会理解力学规律和结构协同;
它支持任务难度可控、流程模块化、结果可定量评估;
更重要的是,它提供了一个观察AI如何获得“空间智能”和“物理智能”的起点。
研究团队期待,未来AI造的不仅是投石机,而是能奔跑、搬运、协作的各种复杂结构——让语言模型真正具备“造出会动的东西”的能力。
项目主页:https://besiegefield.github.io
论文地址:https://www.arxiv.org/abs/2510.14980