在7000多种人类语言中,只有少数被现代语音技术听见,如今这种不平等或将被打破。Meta发布的Omnilingual ASR系统能识别1600多种语言,并可通过少量示例快速学会新语言。以开源与社区共创为核心,这项技术让每一种声音都有机会登上AI的舞台。
你或许很难想象,在世界上7000多种活跃语言中,只有几百种享受过现代语音技术的“宠爱”。
绝大多数人类语言的使用者——从非洲部落的土著、亚马逊雨林的族群,到乡野小镇仍讲着古老方言的老人—— 一直生活在数字时代的旁白之外。

语音助手、自动字幕、实时翻译,这些AI带来的便利仿佛只为少数“主流”语言而生,其余的语言社区仍被挡在技术大门之外。
这种数字鸿沟如今迎来了破局者。
Meta人工智能研究团队日前发布了Omnilingual ASR系统,一个可自动识别转录1600多种语言语音的AI模型族,让几乎所有人类语言都能被机器“听懂”。

这套系统以开源方式共享给全世界,并能由社区亲手拓展新的语言,让每一种声音都有机会登上AI的舞台。

1600种语言,只是开始
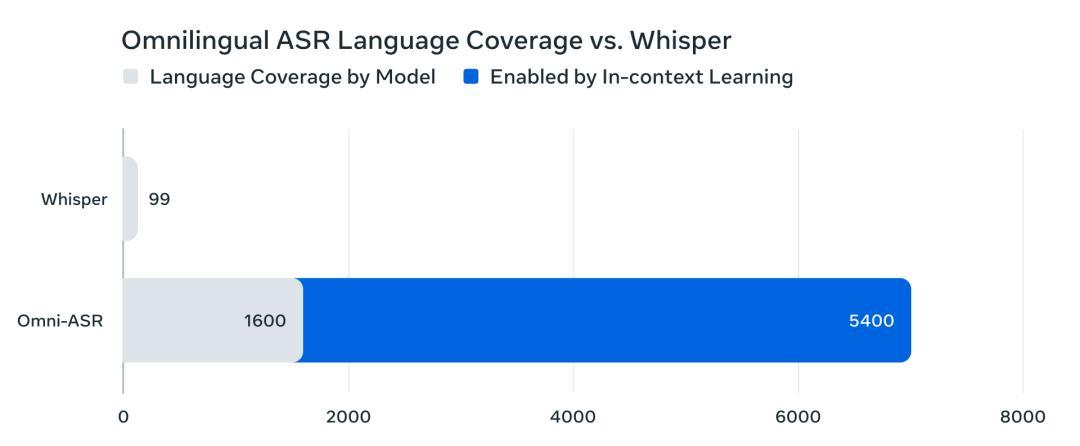
Meta此次推出的Omnilingual ASR创造了语音识别覆盖语言数量的新纪录,支持超过1600种语言,其中包括500种此前从未被任何AI系统转录过的语言。
相比之下,OpenAI开源的Whisper模型只支持99种语言,而Omnilingual ASR几乎将这一数字提升了一个数量级。
对于全球众多使用小语种的人来说,这无疑是一次“数字雪耻”:他们的母语第一次有了被AI流利听懂的可能性。
这套系统的识别性能在很多语种上已达到领先水平。
据Meta提供的数据,在所测试的1600多种语言中,有78%的语种其识别错误率(CER)低于10%,若以10小时以上语音数据训练的语种来看,这一比例更是达到95%。
即使对于训练语料极其稀少的低资源语言,仍有36%实现了CER低于10%的效果。

这些数字意味着,Omnilingual ASR不仅覆盖面广,而且在大多数语言上都能给出实用且高质量的转录结果。
然而,1600种语言还不是Omnilingual ASR的终点。
更大的意义在于,它打破了以往ASR模型支持语言范围固定死板的局限,让语言覆盖从“定量”走向“可扩展”。
Omnilingual ASR借鉴了大语言模型(LLM)的思路,引入了零样本的“上下文学习”机制。
这意味着即便某种语言最初不在支持列表中,用户也可以通过提供几段该语言的音频和对应文本作为示例,在推理过程中即时让模型学会一种新语言。
无需耗费数月收集大型语料、无需专业深度学习训练,只需简单的少样本学习(few-shot)即可学会新语言。
凭借这种革新性的范式,Omnilingual ASR的潜在语言覆盖能力骤然扩张。
官方表示,理论上该系统可以扩展到超过5400种语言,几乎涵盖所有有文字记录的人类语言!
无论多冷门的口语,只要有对应的书写体系和几句示例,它就有机会被Omnilingual ASR捕捉记录。
在AI语音识别领域,这是从静态封闭走向动态自适应的范式转变——模型不再束缚于训练时预设的语言清单,而成为一个灵活开放的框架,鼓励各地社区自行加入新语言。
对于那些长期缺席于技术版图的族群来说,这无异于掌握了一把可以随时亲手“解锁”新语言的大门钥匙。
开源与社区,打破语言鸿沟
Omnilingual ASR的另一个显著特点在于其开源和社区驱动的属性。
Meta选择将这一庞大的多语种ASR系统在GitHub上完全开源,采用Apache 2.0许可发布模型和代码。

无论是研究人员、开发者还是企业机构,都可以免费使用、修改、商用这套模型,而无需担心繁琐的授权限制。
对比此前一些AI模型带有附加条款的“半开源”模式,Omnilingual ASR的开放姿态可谓十分坦荡,为技术民主化树立了榜样。
为了让各语言社区都能受益,Meta不仅开放了模型,还同步释放了一个巨大的多语言语音数据集——Omnilingual ASR语料库。
该语料库包含了350种语料稀缺的语言的转录语音数据,覆盖了许多以前在数字世界中“失声”的语言。
所有数据以CC-BY协议开放提供。
开发者和学者可以利用这些宝贵资源,去训练改进适合本地需求的语音识别模型。
这一举措无疑将帮助那些缺乏大规模标注语料的语言跨越数据门槛,让“小语言”也有大作为的机会。
Omnilingual ASR能够囊括前所未有的语言广度,离不开全球合作的支撑。
在开发过程中,Meta与各地的语言组织和社区携手收集了大量语音样本。
他们与Mozilla基金会的Common Voice项目、非洲的Lanfrica/NaijaVoices等机构合作,从偏远地区招募母语人士录制语音。
为确保数据多样且贴近生活,这些录音往往采用开放式提问,让说话人自由表达日常想法。
所有参与者都获得了合理报酬,并遵循文化敏感性的指导进行采集。
这种社区共创的模式赋予了Omnilingual ASR深厚的语言学知识和文化理解,也彰显了项目的人文关怀:技术开发并没有也不应该居高临下地“拯救”小语种,而是与当地社区合作,让他们自己成为语言数字化的主角。
技术规格上,Meta提供了一系列不同规模的模型以适配多样化的应用场景:从参数量约3亿的轻量级模型(适合手机等低功耗设备)到高达70亿参数的强力模型(追求极致准确率)一应俱全。
模型架构采用自监督预训练的wav2vec 2.0语音编码器(拓展到70亿参数规模)提取通用音频特征,并结合两种解码器策略:一种是传统的CTC解码,另一种则是融入Transformer的大模型文本解码器,后者赋予了模型强大的上下文学习能力。

庞大的模型需要海量数据来支撑——Omnilingual ASR训练使用了超过430万小时的语音音频,涵盖1239种语言的素材。
这是有史以来最大规模、多样性最高的语音训练语料之一。如此大体量的数据加上社区贡献的长尾语言语料,确保了模型对各种语言都学到稳健的语音表示,甚至对完全没见过的语言也有良好的泛化基础。
正如研究论文所指出的,“没有任何模型能预先涵盖世界上所有语言,但Omnilingual ASR让社区能够用自己的数据持续拓展这份清单”。
这标志着语音AI从此具备了自我生长的生命力,能够与人类语言的丰富多样性共同进化。
当技术放下傲慢,以开源姿态拥抱多元,当每一种语言的声音都有机会被聆听和记录,当没有任何一种语言被数字世界遗忘,我们离真正消弭语言鸿沟又近了一大步,人类的连接才能真正开始消除边界。
参考资料:
https://ai.meta.com/blog/omnilingual-asr-advancing-automatic-speech-recognition