
“VLA只是一个过渡方案。”
作者|刘杨楠
编辑|王博
2021年底,商汤科技在港交所敲钟上市。这个时刻像整个计算机视觉行业的一次成人礼,意味着此前数年的狂欢与争议,终于有了一个暂时的落脚点。
作为商汤智能汽车事业群的灵魂人物,时任商汤绝影智能云研发总经理武伟,见证了十年来商汤从0起步,一路辗转上市的全部经过。可在商汤上市敲钟那一刻,他意识到自己正来到新的岔路口。
“我喜欢初创公司的氛围,大家在一个相对未知的领域快速试错,去突破新技术,直到它真正在产业落地发展。”武伟说。于是,他开始思考自己的下一站该往何处。或是加入某个初创团队,或是干脆自己再创业一次。
直到2022年的CVPR上,武伟碰巧和特斯拉团队做了一次技术交流。当时他们默契地意识到,世界模型是AGI的新基建。
三年后,武伟做出了选择。他告别自己一手打造的“绝影”,在2025年5月创办流形空间(Manifold AI)。他又站上了一个全新的技术风口。

Manifold AI流形空间创始人兼CEO武伟
流形空间成立3个月便连获种子轮以及天使轮两轮共亿元融资,成为了世界模型领域一匹“黑马”。
“Manifold”在数学领域被直译为“流形”,这是一种又简单又通用的几何结构。它在局部简单到可以被线性化,在全局又通用到足以描述复杂的高维空间。数学出身的武伟,正试图找到一种“既简单,又通用”的方案,打造一个能理解并预测物理世界的大脑。
这是一个近乎完美的技术理想,但当下的世界模型赛道实在太过复杂。技术仍在早期,一切尚未收敛,市场热闹程度堪比2023年初LLM的“百模大战”。
就在今天,斯坦福大学教授李飞飞的一篇长文《From Words to Worlds: Spatial Intelligence is AI’s Next Frontier(从词到世界:空间智能是AI的下一个前沿)》,引发了整个硅谷对空间智能、世界模型的讨论。李飞飞提出世界模型要具备的三项能力:Generative、Multimodal、Interactive(生成式、多模态、交互性)。
李飞飞认为,下一代世界模型将使机器在全新的层面上实现空间智能——这将解锁当今AI 统仍大多缺失的关键能力,使用世界模型将为人们构建更美好的世界。
世界模型概念火热,但押注世界模型的厂商必须给外界一个充分的理由,吸引更多资源涌入这个年轻的领域,才有可能让愿景成为现实。
而武伟当下要做的,便是在明确的技术理想和不确定的市场环境之间,维持一种微妙的动态平衡。
1.世界模型与VLA之争

武伟被问过最多次的问题,就是“为什么世界模型比VLA更优” 。
在当下的具身智能领域,世界模型和VLA(Vision-Language-Action)模型是一对“影子对手”。二者常被相提并论,也各自收获了大批信徒。但之所以称之为“影子对手”,是因为这种对比本身难以成立。
在商业世界,脱离场景需求谈技术优劣约等于“耍流氓”。再伟大的技术创新,都难免需要通过服务各行各业,来找到其世俗意义上的“产业价值”。
世界模型和VLA本质是在用不同的方式解决同一件事——让机器理解人类的抽象指令,将其转化为在复杂现实世界中可以执行的具体物理动作,并完成任务。
武伟认为,VLA本质是将高维度的视频域降维到语言域,将视频与文本指令对齐,再通过大量的机器人经验数据(如轨迹数据、动作数据)进行对齐和训练,让机器能够读懂语言指令,并基于模仿学习高效、可靠地完成具体任务。其范式本质是基于已有VLM基座模型在做“机器翻译”任务的“后训练”。
他认为,这种训练方式会造成两个弊端。
一方面,VLA模型在训练时与特定的机器人本体强绑定。换一个机器人形态,例如从人形机器人换成四足机器狗,甚至是换一种机器人本体构型,模型就需要大量后训练数据重新适配,部署成本高昂。
另一方面,VLA模型只是“知其然”,但“不知其所以然”。其本质是通过大量模仿学习到某种经验,并在需要的时候将经验复刻出来。它只能执行它见过的动作,当遇到训练数据中从未出现过的、需要推理和规划的新颖场景(即长尾问题中的长尾),它会束手无策,它无法预测一个动作的连锁反应。
而世界模型,则是反其道而行,它将语言升维到视觉域 。它是一种可以模拟所有场景的生成式模型 ,通过学习海量世界知识,让模型理解世界的因果规律,产生“Dreaming(想象)能力”。
在武伟看来,在实际应用场景中,这种预测能力通过两种路径体现。
一种是作为Agent Model(智能体模型),通过在线的模拟和推演获得更优决策。
他举了一个生动的例子:“我看到一个人在哭,我该怎么办?” VLA可能只会基于模仿学习的经验回放给出一个模式化回答;但世界模型会进行推演:“如果我去安慰,对方可能会感激我。”这个推演过程,就是世界模型在进行在线模拟,以得到更好的决策。
一种是作为Environment Model(环境模型),通过离线强化学习使得物理智能体获得更好的泛化能力。武伟希望世界模型成为一个Omni Simulator,即一个可模拟物理智能体交互环境的通用仿真器。
这种通用仿真器与传统依赖图形学的物理仿真引擎有本质区别,因为后者是“不可微”的 ,无法成为一个可学习、可持续进化的系统。
因此,在武伟的蓝图中,VLA只是一个过渡方案。
“世界模型是AGI的重要基建。与传统AIGC不同,世界模型的目标不是还原现实,而是通过预测环境变化来做出更优决策。世界模型让AI第一次具备了心智推演能力——能在脑中模拟因果、预判后果、优化行动。”武伟告诉“甲子光年”。
总的来说,世界模型的心智推演能力,也就是Dreaming能力,本质上依然是一种强大的预测能力。这种能力让世界模型在理论上更能够以更经济的方式,实现跨本体、跨场景的泛化。这也是现阶段,以武伟为代表的一派认为世界模型优于VLA的根本原因。
理论上证明可行性后,接下来的课题,就关于“如何做”。
2.世界模型的技术混战
世界模型是一个极其年轻的战场,最早可以追溯到2018年的论文《World Models》。
这篇文章中提出了“Mental Model”的概念,通过一个RNN对世界状态进行建模,将其编码进隐空间(latent space),再通过隐空间进行状态的迭代预测。
到了2024年,这个方向迎来真正的爆发。OpenAI的Sora成为第一个具备文生视频能力的深度学习模型。自此,AIGC技术路线开始与“视觉世界模型”深度融合。
整体上看,武伟将当下的技术脉络大致归纳为两大派系。
一派是显式物理建模,即用模型复现世界。这一派系的目标是生成与真实物理世界一致的视频形态的可交互空间。
代表性选手之一就是Google Genie系列,以自回归技术路线为主干,将视频和动作(latent action)进行tokenize,转化为离散的token,再通过自回归模型训练。
另一个代表性玩家就是斯坦福大学教授李飞飞创办的WorldLabs。
今天,李飞飞从空间智能的角度,系统阐述了她对“世界模型”的定义,在业内很受关注。她认为,一个真正具备空间智能的世界模型应具备三项核心能力:生成式(Generative),能生成具有几何与物理一致性的世界;多模态(Multimodal),能处理并理解图像、视频、文本、动作等多种形式的输入;交互性(Interactive),能根据输入的动作预测世界的下一个状态。在她看来,这是让AI超越语言理解,真正连接想象、感知与行动,从而解锁创造力、机器人学和科学发现的关键。
《From Words to Worlds: Spatial Intelligence is AI’s Next Frontier》,图片来源:李飞飞博客
而在技术策略上,武伟认为,WorldLabs的方法和Google略有不同,采用了Geometry Forcing(几何强迫)或“物理注入”的方式。它们在数据标注阶段就引入了稠密点云、三维一致性等显式物理信息 ,强行将物理约束注入训练,从而生成更具3D一致性的场景。
一派则是隐空间交互。这一派系的目标不是复现世界,而是训练出一个能与世界交互的智能体。
Google Dreamer系列是这一派系中最具代表性的工作 。其核心思想是通过世界模型将真实世界压缩到一个“隐空间”(latent space)。在这个虚拟的隐空间里训练智能体。
这条路径让Dreamer v3真正拥有泛化能力,其在一个游戏(如Atari)中训练后,无需修改参数,就能直接部署到一个全新的、从未见过的游戏环境里完成泛化 。
Dreamer系列之外还有另一条路径,就是Meta的V-JEPA系列。它本质上也是在构建一个空间世界模型,同样是在隐空间中进行表征推演。
但与Google的Dreamer依赖强化学习去逼近最优策略不同,V-JEPA系列引入了一个新的思路:通过sampling(采样)与能量函数评估的方式,去搜索最优的执行状态。因此,它不再仅仅依赖强化学习去做最优策略逼近,而是在能量空间中寻找最优解,这是一种更“可解释”、物理一致性更强的智能体建模方式。
这种方法下,V-JEPA2可以利用海量的视频数据,尤其是第一人称视角视频数据,再加上少量的机器交互数据训练出一个世界模型。
尽管进展迅速,但武伟认为现有路径存在共同短板,即任务适应性不强,且跨尺度泛化能力弱,也就是一个为自动驾驶训练的模型,无法用于室内机器人。
流形空间要做的,就是能在不同尺度之间迁移与统一的“具身世界模型”。
武伟告诉“甲子光年”,Google、WorldLabs等国外团队对世界模型的研发策略更多是“Top-down”(自上而下),甚至很多是出于学术研究,而非产业落地。相比之下,国内尤其初创企业更适合采用“Bottom-up”(自下而上)路径,这更像特斯拉的路线,即先做领域模型,同时做一些落地应用,通过场景反馈数据不断完善模型能力,进而训练基座模型,在循环往复,不断优化上层的领域模型,形成数据飞轮。
目前,流形空间自称是全球唯一布局全域世界模型的团队 ,团队成员早期参与研发了自动驾驶世界模型DriveScape,近期又自研了机器人场景的RoboScape和无人机场景的AirScape。
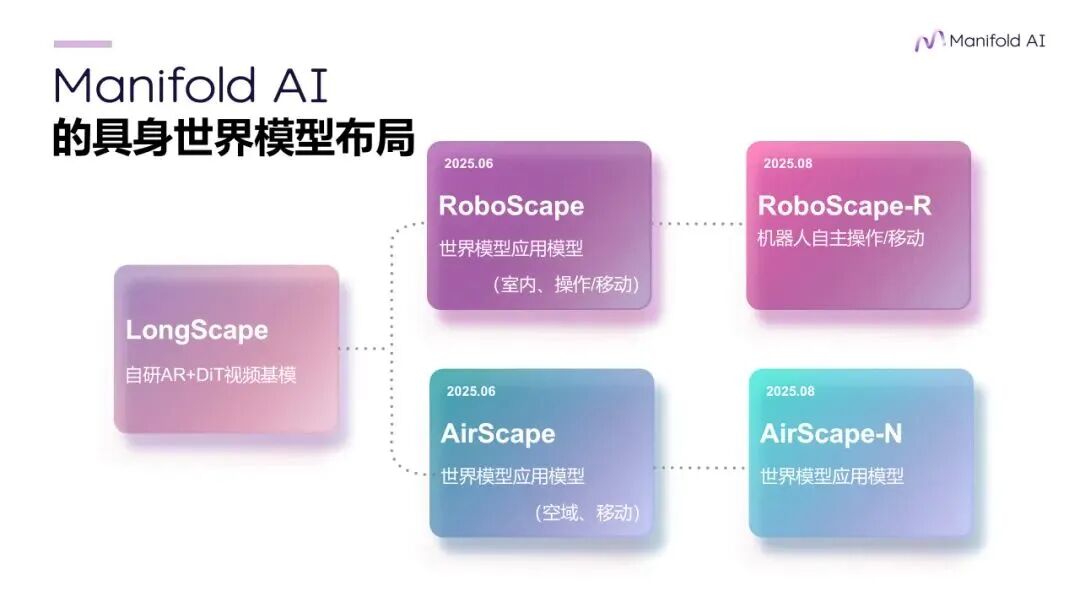
这些领域模型均基于自研的LongScape架构,结合了Auto-regressive+DiT混合建模。因为架构相对同构 ,它们能被方便地用MoE的方式“混合”成一个更通用的基座模型。
武伟坦言,如何用世界模型实现具身智能这件事,目前还没人想清楚,大家都在自己的技术理解中摸索一些可行路径。而流形空间最为与众不同,甚至优于VLA的核心,就在于一个关键决策:选择从预训练开始做起 。
3.一定要做预训练吗?
当下,绝大多数VLA甚至世界模型,都是在已有的视频或语言模型上做“后训练”。
“你如果没有一个很好的预训练,或者说模型没有在预训练中获得Dreaming能力,那么它在没有见过这种样本的数据之上,它其实并不知道物理世界的运行规律是什么样。”武伟解释道。由此导致的结果就是,模型需要很多的后训练数据去补充,导致模型的部署成本很高。
流形空间则试图通过预训练,让模型真正学习到物理世界的先验知识,理解因果规律。
“在我们的方案里面,世界模型有个比较好的预训练,它见过几乎人类所有的动作空间和任务完成的数据。”武伟说 。当这个拥有强大先验知识的基座模型去适配一个新的机器人本体或场景任务时,后训练所需要的数据量就会更少,这会大大降低模型的部署成本。
这个选择实则也是从GPT的成功中汲取了灵感。武伟回忆,在GPT出现前,AI需要为翻译、客服、QA等不同任务单独训练模型。而OpenAI通过海量预训练让模型获得了强大的先验知识,使其在下游任务上仅需few-shot(少样本)甚至zero-shot(零样本)就能完成任务。
为了实现这个目标,流形空间在数据管线、模型架构设计以及训练方法上均有相应创新。
在数据方面,武伟坦言,由于技术完全没有收敛,并没有相关标准明确规定什么样的数据更适合训练世界模型。
流形空间的做法是,整体数据构成是70%的互联网数据和30%的真机采集。其中,互联网数据也有严格的筛选倾向。流行空间选择用大量ego-centric(第一人称视角)数据,因为它和机器人的推理domain差异更小。同时,用于训练世界模型的数据最好能包含更多任务数量,这对数据的variance(方差)更有帮助。一个值得注意的细节是,流形空间还更倾向于使用带有失败状态恢复的数据,这会增强模型的纠错能力。
在模型的架构设计和训练方法上,流形空间提出的具身基座模型强调Reasoning(推理)、Dreaming(想象)、Acting(执行)三位一体的能力。
武伟解释道:“世界模型通常仅强调Dreaming能力,但对于具身基座世界模型,Reasoning和Acting同样重要。Reasoning能力代表具身智能体的思维链,有助于解决常识问题;Acting是一种特殊的Dreaming模态,是具身智能体优化的最终目标。”
实现这三种能力的协同提升,是目前世界模型面临最大的技术挑战。因为三种模态的数据本身是异构的,要让它们的能力同步提升,就涉及大量架构设计和训练技巧。这些复杂的工作都需要在预训练中完成,才能最大程度降低后期模型在实际部署中的难度和成本。
武伟表示,传统的视频生成模型虽然也经过大量预训练,但其对于每一帧画面中的“主体”关注度不够,而是会关注每一帧画面中的所有细节,很难把算力用在最需要的地方。
流形空间则采用创新方案,在视频生成质量和动作(action)质量之间建立起一种正相关。这使得模型在训练中,Dreaming能力的提升可以一致的反馈到动作质量的提升上来。
“我们应该是业内首个能做到这一点的。”武伟表示。实现这一点后,流形空间接下来的目标十分明确,就是要同步探索世界模型的产品化。这是一家初创企业为了走得长远所产生的必然选择。
4.攀登高峰,沿途下蛋
在公司发展战略上,武伟的策略非常务实,他将其总结为一句中国创业圈的黑话:“攀登高峰,沿途下蛋”。
“攀登高峰”是做出通用的具身世界模型基座;“沿途下蛋”则是在这个过程中,将RoboScape、AirScape等领域模型(Sub-domain)提前做一些产品化和商业化 ,以产生营收,支撑团队走得更远。
在落地场景上,武伟做出了一个出人意料的决定:优先考虑机器人和无人机领域,但不会考虑自动驾驶。
这在外人看来是种反差,毕竟他曾是自动驾驶领域的顶尖玩家 。但武伟的想法异常清醒:“并不是说世界模型在自动驾驶这块作用不高,反而它作用其实还是比较高的” 。
他放弃的原因在于产业结构。武伟判断,自动驾驶产业正在产能出清,巨头正在形成和收敛。在这个阶段,算法迭代只是环节之一,差异化有好似更多的是这么多年的工程化的部署以及和合作伙伴的一些深度的协同。
相比之下,机器人和无人机市场更加碎片化 。武伟认为,“人有多少工种就会有多少工种的机器人” ,这个市场能容纳更多的玩家。
更重要的是,具身智能是一个强调软硬件综合能力的赛道,从自动驾驶过往的行业经验来看,大厂在软硬件系统的打造上并未体现出太大优势。
“大厂更擅长ToC、偏软的事情,而具身是偏软硬一体的、更碎片化的市场。自动驾驶领先的地平线和Momenta是创业公司,无人配送的新石器也是创业公司,都不是大厂孵化的。具身需要很强的落地部署和软硬件系统工程能力,这不一定是大厂擅长的,组织大了对新技术反应反而慢,这都是创业公司的机会。”武伟分析道。
具体来看,在无人机和机器人领域,流形空间将重点放在如何让硬件本体拥有自主推理能力上。

基于RoboScape的机器人预测执行能力

基于AirScape的无人机预测执行能力
武伟表示:“现在机器人和无人机主要还是人类控制阶段,无人机出货量虽大但主要靠人工飞手控制;机器人硬件快速发展,但更多还是用遥控器操作。我们聚焦往智能化、自主推理方向发展。”
不过,武伟预计,长期来看,世界模型产品化还有一个关键前提,就是轻量化。流形空间已经将模型量化蒸馏部署到边缘端的推理系统中,能驱动机器人自主移动操作和无人机自主导航。武伟表示:“我们从算力角度选择了英伟达的芯片,未来也会考虑国产芯片作为多元化选项。”
事实上,从流形空间目前的业务版图来看——世界模型的预训练、不同的领域模型以及世界模型的产品化,每一项都是一个行业级别的复杂课题。从创业公司目前的体量来看,要真正做到“攀登高峰”的同时“沿途下蛋”,十分考验掌舵者的能力。
5.用数据驱动的方式做事
毕竟,创业不比在大公司做高管,除了思考如何“做事”,更大的挑战在于如何处理“人”和“钱”的问题。
从千人规模的龙头高管,到几十人规模的初创公司CEO ,武伟的心态也在转变。他的团队可划分为两队人马,一队是工业界老司机,一队是天才00后。相比砸钱挖人,他更注重人才的密度,而不是数量。
他甚至把AI的训练思维迁移到团队管理上,要用“数据驱动”的方式来做事。
传统的管理像是“监督学习”,而他更倾向于“强化学习”。
“如果这个团队的同学能够完成这件事情,得到一个正向的结果,那你其实就应该鼓励这种成果,要及时地给出一个reward(奖励),用类似强化学习的方式,让整个团队逼向最优解。” 武伟告诉“甲子光年”,“你不能强行让天才00后都听‘老司机’的想法,让他去避坑,这样有一些闪光点反而会被埋没掉。”
目前,流形空间已获得了亿元级别的融资,并计划在2025年底至2026年初,正式发布其第一代基于WMA路线的基座模型。武伟透露:“我们希望成为产品驱动的公司。整体融资节奏还是与产品研发节奏匹配。”
对于公司的长期规划,武伟有着严肃的思考。他希望流形空间能“推动Physical AI Agent向前一大步” ,并希望公司“自研加上赋能的机器人数量超过市场总量的10%”。
正如他引用物理学家费曼的那句名言:“如果我不能创造它,我就无法理解它。”