炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
来源:Univer梦数科技
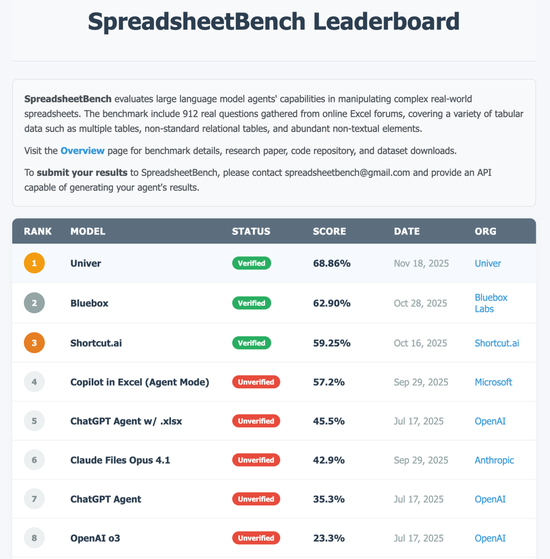
在最近一轮的 SpreadsheetBench 评测中,UniverAgent 取得了 68.86% 的 Pass Rate,位列排行榜第一,超越了包括 ChatGPT Agent 和 Excel Copilot 在内的主流方案。(对技术有兴趣的朋友,欢迎点击左下角“查看原文”到我们的 Github 转转,顺手给个⭐️)
SpreadsheetBench 是当前电子表格自动化领域最具权威性的公开基准之一,微软与 OpenAI 均曾在官方文章中引用其测试数据,微软现任 CEO 萨提亚·纳德拉(Satya Nadella)也曾在社交媒体上发表其评测结果。


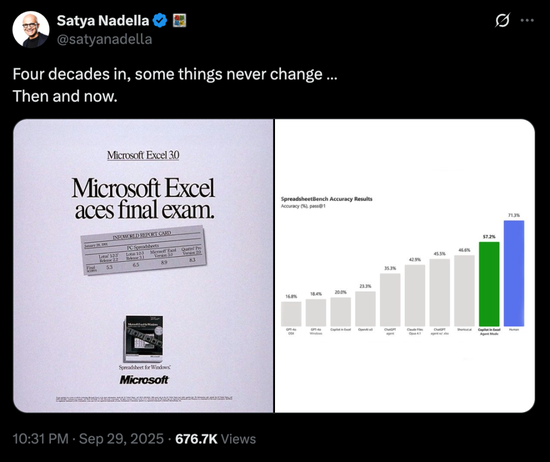
这是该榜单出现的第一支中国团队。与榜上多数仍依赖 Excel 环境执行任务不同,UniverAgent 基于自研的 Univer SDK,实现了全程脱离 Excel 的表格计算与推理能力,可视为一次从底层重构电子表格智能的技术跃迁。这一成绩的取得,并非单纯依赖于更强的基座模型,而是源于我们对“电子表格 Agent”这一命题的系统性重构:从“生成脚本操作文件”的辅助工具,转向“基于在线环境、具备混合执行能力的自主智能体”。
本文将从技术视角拆解 UniverAgent 在 SpreadsheetBench 上的表现,探讨它是如何在理解(Understanding)、准确性(Accuracy)和定位(Positioning)三个维度上建立优势的。
一、SpreadsheetBench:真实业务场景的试金石
许多 AI Demo 看起来很美,但在真实业务中往往“一碰就碎”。SpreadsheetBench 的价值在于它提供了一个基于真实任务的严谨参考框架。
它包含 912 个来源于真实场景的任务,涵盖了从数据清洗、复杂计算到格式调整的全流程。与简单的“玩具数据集”不同,SpreadsheetBench 重点考察三个互相关联的维度:
1. UNDERSTANDING(理解能力):能否准确理解自然语言指令中的业务意图,并正确识别相关的数据区域(而非误用无关区域)。
2. ACCURACY(结果准确性):数值计算是否精确,公式逻辑是否正确,数据类型(如日期、货币)是否符合规范。
3. POSITIONING(定位准确性):结果是否写入了指定的工作表和单元格,且不破坏原有的表格结构。
这三个维度彼此牵制、很难被单一技术路径同时兼顾:单纯的 Python 脚本容易算对数值(Accuracy),但很难处理复杂的格式和位置约束(Positioning);单纯的 Excel 公式能处理位置,但难以应对复杂的逻辑推理(Understanding)。
UniverAgent 的高分,正是因为它通过系统设计,在这三个维度上取得了平衡。
二、核心差异:系统工程胜于模型参数
在 SpreadsheetBench 榜单上,我们可以看到多种技术路线。UniverAgent 的核心差异在于:我们没有把电子表格简单视为一个 CSV 文件或一个 API 对象,而是围绕其结构化、富交互、在线化的特性,设计了一整套 Agent 架构。
这套架构包含三个关键支柱:
1. 表格友好的上下文工程:通过 `SpreadsheetOverview` 和 `GetRangeData`,构建高信噪比的“地图”与“放大镜”。
2. CodeAct + Planning 执行策略:引入多轮思考循环与自适应缓存,替代脆弱的“一次性脚本”。
3. 在线混合执行架构:Python 负责重数据分析,JavaScript (Univer SDK) 负责精细表格操作,两者在在线环境中无缝协作。
三、上下文工程:构建高信噪比的“地图”与“放大镜”
电子表格任务的一大挑战是上下文(Context)爆炸。一个几千行的表格直接转为文本会瞬间耗尽 Token 预算,且丢失关键的结构信息(如合并单元格、公式引用)。
UniverAgent 设计了两层上下文抽象来解决这个问题。
1. SpreadsheetOverview:全局“地图”与信息压缩
`SpreadsheetOverview` 的作用是让 Agent 在消耗极少 Token 的前提下,看清整个工作簿的结构。它不仅仅是数据的截断展示,更包含了一系列智能压缩策略。
以一个简单的销售数据表为例,原始电子表格中的内容大致如下(只展示关键列):
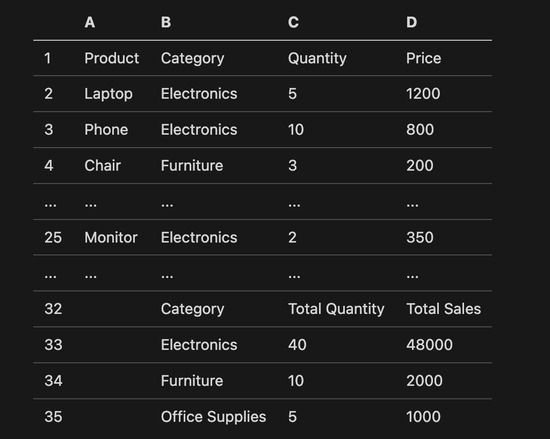
# Spreadsheet Context
📊 Spreadsheet Overview - Total Sheets: 1 - Active Sheet: ‘Sales’ ## 📄 Sheet: ‘Sales’ - Sheet Used Range: A1:D35 (35 rows × 4 columns) - Tables Found: 2 - Formulas Found: 2 ### Table 1: A1:D25 |A1,Product|B1,Category|C1,Quantity|D1,Price| |A2,Laptop|B2,Electronics|C2,5|D2,1200.00| ...(中间行被省略) |A25,Monitor|B25,Electronics|C25,2|D25,350.00| ### 🔢 Formulas (0 formula group) - None ### Table 2: B32:D35 |B32,Category|C32,Total Quantity|D32,Total Sales| |B33,Electronics|C33,40|D33,48000.00| |B34,Furniture|C34,10|D34,2000.00| |B35,Office Supplies|C35,5|D35,1000.00| ### 🔢 Formulas (2 formula groups) - C33:C35 ← C33: =SUMIF($B$2:$B$25,B33,$C$2:$C$25) - D33:D35 ← D33: =SUMPRODUCT(($B$2:$B$25=B33)$C$2:$C$25$D$2:$D$25)
关键技术点在于:
●结构识别:自动识别 Table 边界(如 A1:D25),而非盲目读取整张表;
●层次化视图: Spreadsheet -> Sheet -> Table / Formula, 层层递进,既展示了结构,又避免了信息过载;
●公式组聚合:如上例所示,`C33:C35` 的公式逻辑完全一致,系统将其聚合为一条描述 `C33:C35 ← C33: ...`。这种处理方式能将上百行的冗余信息压缩为一行,Token 占用减少 90% 以上。
在实测中,即便是 7000 行的大型工作簿,其 Overview 上下文体积通常也能控制在 0.5KB 以内。这为 Agent 提供了清晰的全局视野,显著提升了 UNDERSTANDING 指标。
2. GetRangeData:结构化的“放大镜”
当 Agent 需要深入处理特定区域时,`GetRangeData` 提供了结构化的局部视图。它返回的不仅仅是二维数组,而是一个包含丰富元数据的对象:
============================================================
📊 Range Data: A1:F32 ============================================================ 📋 Metadata: • Shape: 32 rows × 6 columns • Formula groups: 3 (74 total cells) • Styled cells: 15 📄 Data Preview: (showing first 10 rows) A B C D E F 1 SN DATE ... TOTAL ... ... 2 001 1/1 ... 1200 ... ... ... 🔢 Formula Groups: (top 15 of 3) • D2:D74 ← D2: =IFERROR(INDEX(...)) • E2:E74 ← E2: =VLOOKUP(...) 🎨 Style Definitions: (top 5 of 5) • 01gvvu6: fs:11|bl:1|bg:#FFFF00 (3 cells) ============================================================
这个 `RangeData` 对象包含三个维度的信息:
●Values:直接映射为 `pandas.DataFrame`,便于 Python 进行向量化计算。
●Formula Groups:延续聚合策略,准确描述区域内的计算逻辑。
●Styles:将样式定义(如 `bg:#FFFF00`)与引用解耦,使 Agent 能感知颜色、字体等视觉线索(这在处理“标红异常值”类任务时至关重要)。
这种分层设计,确保了 Agent 既能“看全”也能“看细”,为后续的精准操作打下基础。
四、执行策略:从“一次性脚本”到 CodeAct 循环
面对 SpreadsheetBench 中的复杂任务,试图生成一段完美的“一次性脚本”往往是徒劳的。UniverAgent 采用了 CodeAct (Code as Action) 架构,将执行过程拆解为多轮交互循环:
Thought(思考)→ Code(编码/工具调用)→ Observation(观察结果)
1. 动态规划与自我纠错
在每一轮循环中,Agent 都会根据 `Observation` 修正自己的认知。
● 如果发现数据格式与预期不符,它会调整清洗逻辑;
● 如果写入结果后发现位置偏移,它会读取结果区域并重新调整坐标。
这种“小步快跑、实时反馈”的机制,极大地提升了任务的 ACCURACY 和 POSITIONING 表现。
2. 自适应消息缓存(Adaptive Message Cache)
多轮交互虽然稳健,但会带来上下文过长的问题。UniverAgent 引入了自适应消息缓存机制,充分利用 LLM 的 Prompt Caching 功能。系统会根据对话轮数自动插入缓存断点,使得历史上下文(包括庞大的表格结构信息)无需重复计算。这不仅降低了推理成本,更显著提升了长链路任务的响应速度。
五、架构优势:在线环境与混合执行
UniverAgent 的另一大护城河,在于其运行环境。与基于 `openpyxl / VBA` 等依赖 Excel App 操作本地文件的离线方案不同,UniverAgent 直接运行在 Univer 在线表格引擎 之上。
1. Python + JavaScript 混合双打
在处理复杂任务时,单一语言往往力不从心。UniverAgent 创造性地采用了混合执行模式:
●Python (pandas/numpy):负责“重”逻辑。例如多表合并、透视分析、复杂统计。Python 在数据处理上的生态优势在这里得到了最大化释放。
●JavaScript (Univer SDK):负责“细”操作。例如设置条件格式、调整列宽、插入图表、精确写入单元格。这些是 DOM 无关的 Headless 环境,保证了渲染的一致性。
示例场景:
下面我们用一个简单例子展示混合执行模式的优势:
任务:从某个销售明细区域中,按类别汇总销售额,并把结果写回到当前表格的指定区域。
import pandas as pd # 1. 通过工具获取数据 range_data = get_range_data(“A1:C100”)# 假设列为: Category, Item, Amount df = range_data.to_dataframe() # 2. Python 侧进行数据分析 totals = df.groupby(“Category”)[“Amount”].sum() categories =list(totals.index) values =list(totals.values) # 3. JavaScript 侧写入结果 js_code =f“”“ () => {{ const workbook = univerAPI.getActiveWorkbook(); const sheet = workbook.getActiveSheet(); const categories = {categories!r}; const values = {values!r}; // 从第 0 行第 5 列开始写入结果(也就是 F1 开始) for (let i = 0; i < categories.length; i++) {{ const row = i; // 0-based 行号 const colCategory = 5; const colAmount = 6; sheet.getRange(row, colCategory).setValue(String(categories[i])); sheet.getRange(row, colAmount).setValue(Number(values[i])); // 金额列设置为货币格式 sheet.getRange(row, colAmount).setNumberFormat(“$#,##0.00”); }} return {{ success: true, writtenRows: categories.length }}; }} “”“ result = eval_js(js_code) print(result)# => {‘success’: True, ‘writtenRows’: N}
这种分工使得 UniverAgent 既拥有数据分析的深度,又具备原生表格操作的精度。
2. 在线协作的天然优势
基于在线架构,UniverAgent 的每一次操作都是对“活”的表格进行的。这意味着:
●状态自然保持:无需反复读写文件,中间状态实时驻留在内存中。
●所见即所得:Agent 的操作可以实时同步给人类用户,便于人机协作与监督。
●版本控制:利用在线表格的版本回滚能力,Agent 的误操作可以被轻松撤销,大大降低了实验成本。
六、结语:迈向自主电子表格工程
SpreadsheetBench 的 68.86% 只是一个数字,它背后反映的是电子表格自动化从“玩具”走向“工具”的技术跨越。
UniverAgent 的实践证明,通过极致的上下文工程、稳健的 CodeAct 循环以及原生在线的混合架构,AI 完全有能力胜任复杂的电子表格工作。我们不再是在生成一段辅助脚本,而是在构建一个能够理解业务、精准执行、自我纠错的电子表格工程师。
未来,随着模型能力的提升和工具链的完善,我们期待看到更多企业级场景下的自动化落地,让数据处理真正回归价值本身。
文末最后打个小广告,近期团队正在招募 AI Agent 相关人才,如果你看了对我们正努力的方向很感兴趣,欢迎联系我们:developer@univer.ai
新浪声明:此消息系转载自新浪合作媒体,新浪网登载此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,不构成投资建议。投资者据此操作,风险自担。责任编辑:何俊熹