离开Meta的大佬们,留下作品还在陆续发表,今天轮到田渊栋。
这次他带领团队把目光投向了大模型强化学习训练中一个令人困惑的现象:为什么RL训练明明带来巨大性能提升,却只改变了极少数参数。

论文剖析了可验证奖励强化学习(RLVR)的训练动态,戳破了一个误区,参数更新的稀疏只是表面现象,背后是RLVR有个固定的优化偏好。
对于同一个预训练模型来说,无论用什么数据集和RL算法,RLVR只盯着同一小部分参数修改。
团队还提出了一个全新的三门理论(Three-Gate Theory),一步步说明RLVR的参数更新是怎么定位至特定参数区域的。
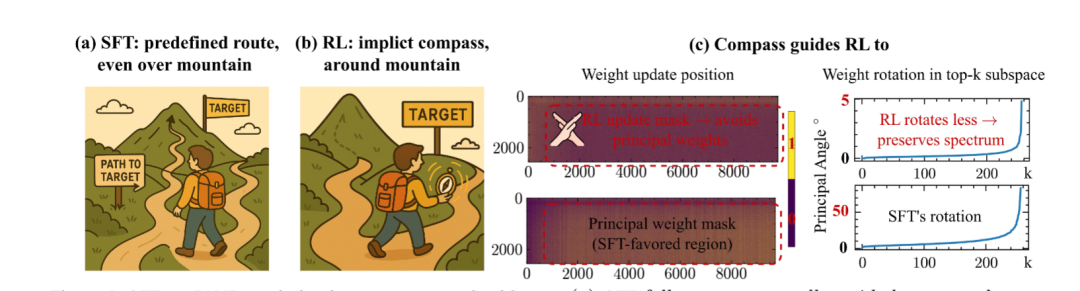
三门理论:RL参数更新的内在机制
像OpenAI-o3和DeepSeek-R1这样的推理模型,都是通过大规模RLVR训练获得数学和编程能力的大幅增强。
按理说,如此巨大的能力提升应该伴随着大量参数的改变,但最近的研究却发现,RL训练产生的参数更新是稀疏的,而监督微调(SFT)的参数更新是密集的。
这种高收益、低变化的悖论引发了Meta团队的关注。
他们分析了包括Qwen系列和DeepSeek-R1-Distill-Qwen在内的多个开源模型,这些模型经过超过3000步的长时间RL训练,涵盖数学、编程、STEM、逻辑谜题和指令遵循等多样化任务。
通过设计一种bfloat16精度感知的探测方法,研究团队准确测量了参数更新的稀疏度。结果显示,SFT的稀疏度通常只有0.6%到18.8%,而RL的稀疏度高达36%到92%,相差了一个数量级。

但更重要的发现是,这种稀疏性只是表面现象,背后隐藏着一个更深层的机制:模型条件优化偏差(model-conditioned optimization bias)。
为了解释这种独特的训练行为,研究团队提出了三门理论,解释了RL更新是如何被约束、引导和过滤的。
第一门:KL锚定(KL Anchor)。
RLVR的核心是 “试错学习”,但他次更新不会让模型的输出风格太偏离(比如原来模型说话简洁,不能越学习越啰嗦)。
这个机制背后原理是,在线策略梯度更新会在每一步施加策略KL界限。
即使在没有显式KL正则项的DAPO算法中,比例裁剪技巧仍然会施加O(ε²)的KL界限。这种锚定效应确保了每步相对于当前策略的漂移很小,进而限制了参数的移动范围。

第二门:模型几何(Model Geometry)。
预训练模型拥有高度结构化的几何特性,比如模型里负责核心逻辑的参数,对应高曲率区域,改动起来影响大,但容易不稳定。
在KL约束下,RL更新倾向于保持模型的原始权重结构,自然偏向于优化景观中的低曲率方向。
反观SFT,因为修改高曲率区域容易接近标准答案,但改多了会把模型原有的能力框架 打乱,反而不利于复杂推理。

第三门:精度过滤(Precision)。
bfloat16的有限精度充当了一个透镜,隐藏了在RL不愿施加大改变区域的微小更新。
由于bfloat16只有7位尾数,小于单位最低位(ULP)阈值的变化无法表示。如果RL持续更新路由到特定参数子集,存储的值就不会改变,结果就表现为稀疏性。
如果换成更高精度(比如 float32),会发现更多参数改动。
论文做了很多实验验证上面的逻辑,确认了RLVR和SFT在参数空间中的优化区域完全不同。
通过分析奇异值分解(SVD)重构后的主成分权重,团队发现RL更新与主成分权重的重叠度始终低于随机水平,表明RL有强烈的倾向避开这些权重。相反,RL更新与低幅度权重显示出超随机的重叠,这是因为它们对微小更新的阻力较低。
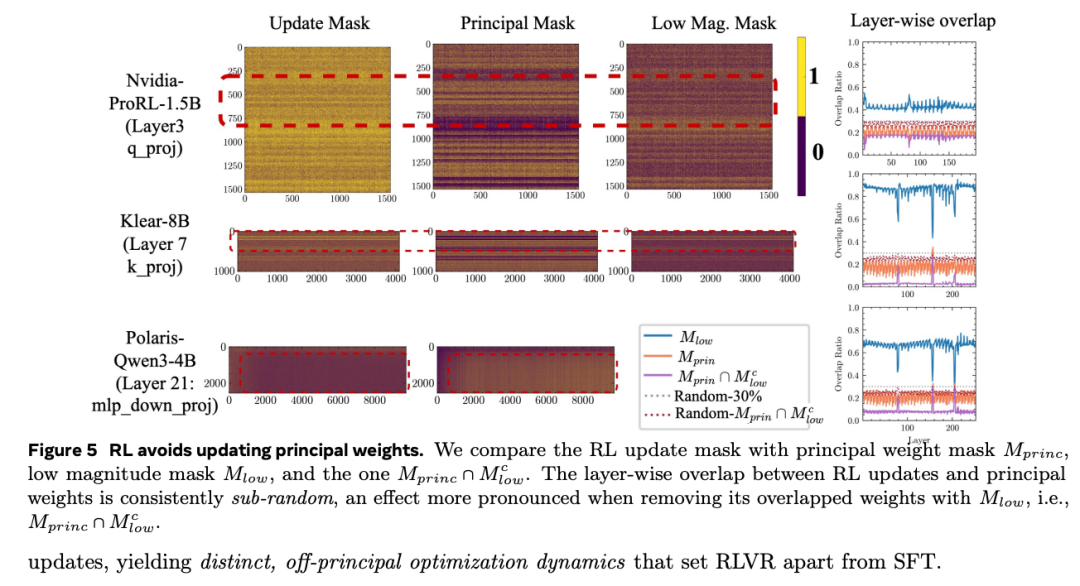
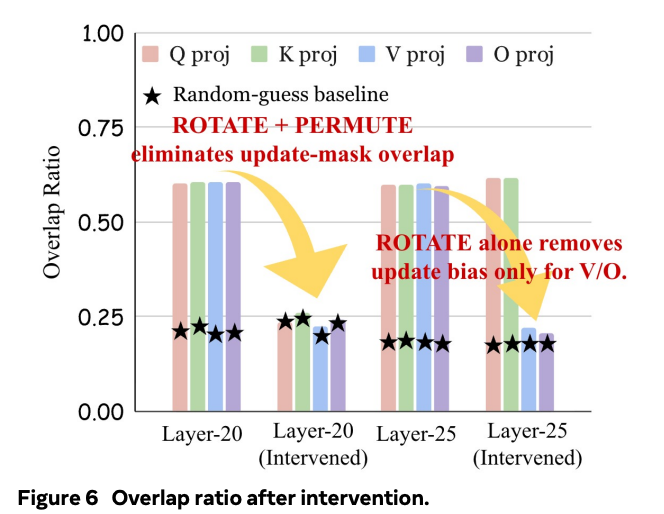
以及因果性验证实验,团队通过正交旋转和头部置换故意”扰乱”Qwen3-4B-Base模型特定层的几何结构。结果显示,在被干预的层中,更新重叠度降至随机水平,而在未触及的层中保持较高,这证明预训练模型的几何结构是优化偏差的来源。
在光谱分析方面,RLVR检查点在顶部主成分内表现出明显稳定的谱:跨层的主子空间旋转一致较小,谱漂移最小。奇异值曲线几乎与基础模型相同。相比之下,SFT在相同指标上引起了显著更大的旋转和明显的漂移。

对参数高效微调方法的启示
这项研究不仅解释了观察到的现象,还为RL训练算法的设计提供了指导。
团队的发现表明,许多SFT时代的参数高效微调(PEFT)方法,特别是通过稀疏或低秩先验与主方向对齐的方法,在RLVR中的迁移效果很差。
在稀疏微调实验中,仅更新主成分权重(SFT偏好的方向)会产生最差的优化轨迹,KL曲线上升缓慢,显示出过度干预和退化的训练动态。
相反,更新非主成分、低幅度权重恰好符合理论预测的离主成分区域,能够紧密跟踪密集RLVR轨迹。
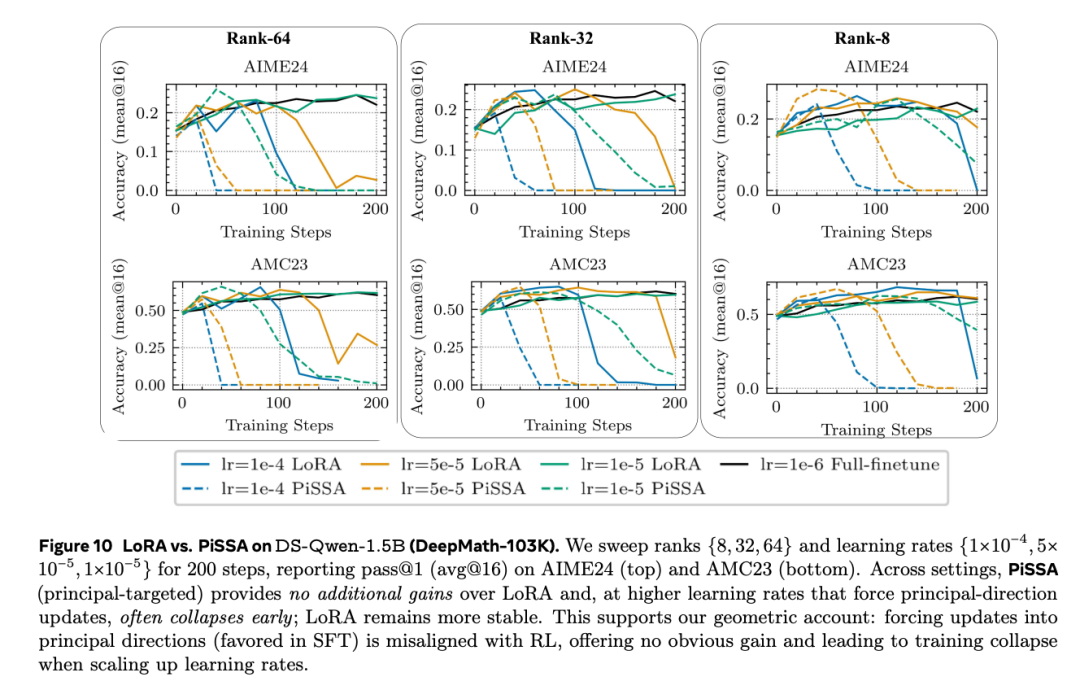
对于最近流行的LoRA变体,研究发现主成分定向的PiSSA并没有比标准LoRA带来额外收益。
在用于匹配全参数性能的较高学习率下,PiSSA经常变得不稳定并提前崩溃。这是因为在PiSSA中扩大学习率会强制沿主方向更新,而这些方向具有更高曲率和谱扭曲特性,正是RLVR倾向于避免的方向。
论文地址:https://arxiv.org/abs/2511.08567