作者 | 王涵
编辑 | 漠影
你一定在科幻电影中看到过这样的情节:主角不小心进入了游戏世界,在3D虚拟的场景中探索、漫步。
如今,这不再是只能幻想的场景。世界模型的出现,给这一情节带来了更多在现实中实现的可能性。
经过一年时间的打磨,10月底,智源研究院发布了新一代原生多模态世界模型“悟界·Emu3.5”。
性能上,相较上一版本,Emu3.5在超过13万亿token的大规模多模态数据基础上展开训练,其视频数据训练量时长从15年提升到790年,参数量从8B上升至34B。
在不牺牲性能的前提下,Emu3.5每张图片的推理速度提升了近20倍,首次使自回归模型的生成效率达到顶尖的闭源扩散模型的水平。
智东西获得了Emu3.5的内测资格,第一时间对其文生图和图片编辑功能进行了实测。
首先是文生图功能,我们输入提示词如下:
在一个充满活力的厨房场景中,大窗户外可见郁郁葱葱的绿植。两个动画角色并排站着。左边是一个拟人化的狐狸模样的生物,有着橙色的皮毛、白色的腹部和一双富有表现力的大眼睛,脖子上系着一条绿色的围裙。右边是一个年轻女孩,棕色的头发扎成了辫子,穿着黄色的衬衫,外面套着一件蓝绿色的围裙。两个角色似乎都在忙着做饭,背景中挂着各种厨房用具、锅以及橙子、大蒜等食材。整个环境明亮又欢快,阳光透过外面的树叶洒进来。图像中没有可见的文字。
不到一分钟,Emu3.5就生成了一副很“迪士尼风”的图画。画面颜色明亮轻快,小女孩和狐狸都和提示词形容的十分相似,画面光影、比例和构图都很协调。

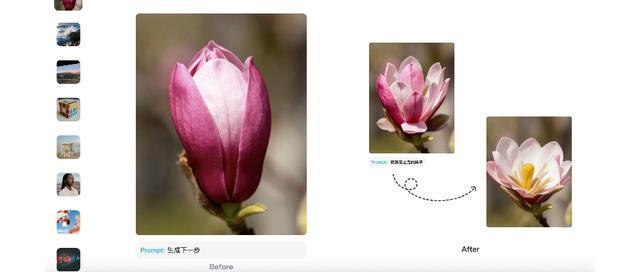
图片编辑方面,我们上传了一张小松鼠的照片,要求Emu3.5将画面中的小松鼠提取出来,背景换成雪地场景。

原图片中,小松鼠和背景色调一致,肉眼都容易看不清楚,Emu3.5却十分精准地识别出了小松鼠的形象。其生成的图片光影、结构准确,连阳光照射在雪地上的反光都十分逼真,在画面的前方和后方背景,还实现了相机般的虚化效果。

此外,Emu3.5还能修改图片视角。我们上传了一张仰视的鼓楼夜景照片,要求Emu3.5将这张照片转化为一只鸟的视角:

Emu3.5不仅能精准实现视角切换,其“下一阶段预测”范式更使其具备自动补全周边环境画面的能力,表现就像一台置于真实场景中的相机。

此外,Emu3.5还可以更改画面中主体的位置关系和动作形态,比如让小狗拥抱小猫:

识别数字和计数一直是多模态模型的弱点,Emu3.5却可以精准识别将图片中的标号,将指定序号的挂画换成另外一张海报:

在画面中加入一个物体也不在话下,Emu3.5可以直接将魔方放置在图片场景中,并且会根据场景的光线和风格自动调整物体的色调,不会出现“不在一个图层”的效果。

再比如,Emu3.5还可以修复老照片,还原老照片本来的颜色和质感:

当然,作为世界模型,Emu3.5也可以创造出一个“世界”。
例如,我们让Emu3.5生成了一个卧室照片。接着,点击继续探索,要求Emu3.5更走近一些。通过一步一步地变换视角,Emu3.5就可以生成一个完整的“世界”:

除了变换视角,Emu3.5还可以“预测”图片场景100年后的样子:

该模型延续了将图像、文本和视频等多模态数据统一建模的核心思想,并在“Next-Token Prediction”范式的基础上,模拟人类自然学习方式,以自回归方式实现了对多模态序列的“Next-State Prediction(NSP)”,从而获得了可泛化的世界建模能力。
那么,NSP是怎么实现的?Emu3.5和其他世界模型有什么不一样的地方?除了生成图片和“世界”Emu3.5还能用在哪里?我深扒了“悟界·Emu3.5”的技术报告,给你一一解答。
一、直接预测下一个状态,厉害在哪?
李飞飞在她的自传《我看见的世界》中写到,5.43亿年前,地球上的生物生活在原始海洋中,没有感官和知觉,因此也没有大脑。后来,“寒武纪生命大爆发”时期到来,生物进化历程从此开始狂飙。
动物学家安德鲁·帕克认为,“寒武纪生命大爆发”之所以会发生,其实是因为生物开始具备“光敏感性”,这也是现代眼睛形成的基础。
简单来说,生命爆发进化是从“看见”开始的。那如果将这个进化路径放在AI上呢?
在Emu的技术沟通会上,王仲远博士也提出了类似的看法,他说:“人类的学习,不是从文本学习开始的。我们每一个人从出生开始,跟其他人的交流,认识物理世界的运行规律,都是从视觉开始的。”
Emu3.5的训练数据中包含超13万亿多模态token,其中视频数据时长累计有790年,覆盖教育、科技、How-to、娱乐等多领域。与传统方法不同,Emu3.5的训练语料库旨在捕捉长时程、交错的多模态语境。
具体而言,该子集来源于大规模互联网视频的连续视频帧和时间对齐的音频转录文本,这些内容本身就保留了时空连续性、跨模态对齐性和语境连贯性。
在训练框架上,Emu3.5基于单一自回归Transformer架构,采用端到端原生多模态建模,无需依赖扩散模型或组合式方法,就实现了图像、文本、视频等多模态数据的“大一统”处理。
进而,在大规模多模态数据和Next-Token Prediction(NTP,下一个token预测)的基础上,Emu3.5扩展出“Next-State Prediction(NSP,下一状态预测)”即直接预测多模态序列的完整动态状态,而非孤立token。
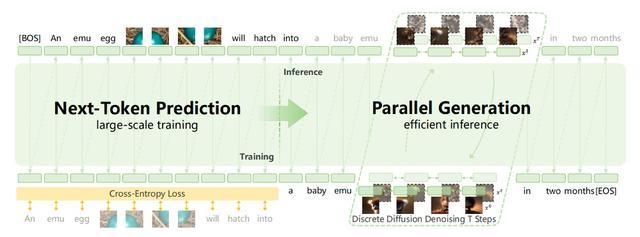
NSP厉害就厉害在,它可以让模型从多模态数据中自主学习世界的动态规律,例如物理动态、时空连续性、因果关系,进而实现“理解——预测——规划”的完整能力。
NSP还能将高层意图转化为可执行的多步行动路径,接受指令后,Emu3.5能基于视频中学到的 “物体移动规律”,规划符合物理逻辑的连贯步骤,这正是AI从“感知”进化为“认知”的核心标志。

为了提高推理效率,研究团队提出了离散扩散自适应(DiDA)方法,它将逐token解码转换为双向并行预测,在不牺牲性能的情况下,将单图像推理速度提升了约20倍。
研究团队还构建了多维度奖励系统,对NSP的 “多步骤规划准确性”“因果逻辑连贯性” 进行定向优化,提升了Emu3.5的步骤分解与物理规律匹配度。
从性能表现来看,当前Emu3.5参数量为340亿,训练所用视频数据累计时长达790年,仅占全互联网公开视频数据的1%以下,但模型性能已达到“产品级”水准。
“自回归架构”+“大规模强化学习训练”+“下一状态预测”(NSP)范式,至此,Emu3.5找到了多模态世界模型的Scaling Law方向,多模态模型性能可以像大语言模型(LLM)一样,随计算和参数规模的增长而可预测地提升。
“Emu3.5很可能开启了第三个Scaling范式。”王仲远博士这样形容Emu3.5,毫不夸张。
二、教机器人抓拿握,不用再不同场景分开学了
正是因为在“下一状态预测”上的技术突破,EMU3.5 模型具备了学习现实世界物理动态与因果的能力,展现出对复杂动态世界进行预测和规划的能力。这就让EMU3.5可以在具身智能方面大展身手。
在场景应用层面,模型可实现跨场景的具身操作,具备泛化的动作规划与复杂交互能力,并能在世界探索中保持长距离一致性与可控交互,兼顾真实与虚拟的动态环境,实现自由探索与精准控制。

据介绍,Emu3.5已经开始了在具身智能方面的实践探索。
过去,数据采集多局限于固定场景,机器人真机只能采集到具体有限的数据,通过Emu3.5它可以产生泛化的数据,使得模型产生了泛化的能力。
而得益于Emu系列采用的自回归架构,其可扩展性极强,并且能够支持视觉与文字Token的输出。这能够极大的提高模型,包括具身机械人、机械手臂,实际场景中处理泛化性的能力,自然而然就会推动整个具身更快进入一些真实的场景中
在真实场景测试中,应用Emu3.5后,未知场景中,机器人行动的表现成功率可直接达到 70%,而其他模型的表现成功率往往接近零。
“泛化”这一方向就是是智源研究院的重点发力的领域,目前正进一步扩大技术验证规模,在真机上对各类场景展开尝试。
三、只有原生多模态大模型,才能让AI感知世界、理解世界
从上文中对Emu3.5的技术解读不难发现,智源研究院一直坚持的技术路线核心就是“原生多模态”。
从Emu3到Emu3.5,模型均采用单一自回归Transformer架构,实现图像、文本、视频数据的 “端到端统一处理”,无需依赖扩散模型(DiT)或混合架构,从底层解决 “多模态数据对齐” 与 “跨模态推理” 的核心痛点。
智源研究院的研究团队认为,世界模型不等同于视频预测模型。真正的世界模型应该理解“杯子掉落→破碎”“点燃木头→燃烧”等深层因果关系,并且可以“举一反三”,将一个场景中的能力泛化到其他场景,真正做到像人一样思考。
原生多模态大模型的研发,能够把多模态的理解和多模态的生成统一起来。智源研究院认为,只有这样,才能够真正让AI看到、感知、理解这个世界,才能够让AI真正进入物理世界,真正解决现实生活中更多现实的问题。
结语:世界模型进入“下一个状态预测”范式
从“下一Token预测”迈向“下一个状态预测”,Emu3.5的发布标志着世界模型的发展进入了一个新阶段。
其意义不仅在于视频生成功效的提升,更在于通过“原生多模态”与“下一状态预测”的路径,让模型获得了对物理世界动态与因果关系的深层理解能力。这为AI在真实场景中实现可靠的规划与决策奠定了基础。
在行业落地上,这一能力更是直接瞄准了具身智能、自动驾驶和工业仿真等行业的痛点。在这些领域,AI不仅需要“看得见”,更需要“看得懂”,并能预测“接下来会发生什么”。
随着“状态预测”范式的确立,世界模型的技术竞争正从“生成质量”的比拼,升级为“世界理解深度”的较量。