All eyes are on Nvidia this week, as the company reports its 2026Q4 earnings.
Metric | Q4 2026 Estimate | YoY Growth | Context |
Revenue | $65.0B – $65.8B | ~67% | Up from $39.3B in Q4 '25. Reflects peak Blackwell ramp. |
Adjusted EPS | $1.46 – $1.53 | ~71% | A massive jump from last year’s $0.89. |
Gross Margin | ~75.0% | +140 bps | Seeking a recovery from Q3's 73.6% "dip." |
Data Center Rev | ~$59.9B | ~66% | ~90% of total company revenue. |
NVIDIA’s projected financials for Q4 2026 reflect a company still in its peak growth phase. Revenue is estimated to land between $65.0 billion and $65.8 billion, representing a 67% year-over-year increase from the $39.3 billion reported in Q4 2025. This surge is primarily driven by the "Blackwell" architecture, which has reached its peak production ramp. The Data Center segment continues to be the undisputed engine of the company, accounting for approximately $59.9 billion, or 90% of total revenue.
Profitability also shows signs of stabilization. Adjusted Earnings Per Share (EPS) is expected to jump to between $1.46 and $1.53, a significant leap from the $0.89 seen last year. Perhaps most importantly for investors, Gross Margins are expected to recover to 75.0%. This follows a temporary dip to 73.6% in the third quarter, which was attributed to the lower initial yields of the complex Blackwell series and a $4.5 billion inventory write-off. However, a new challenge looms: a 25-30% increase in memory prices could exert downward pressure on these margins, potentially creating a headwind of 2 to 3 percentage points in the coming quarters.
At the earnings call, investors will also pay close attention to any updates regarding the product line.
Generation | Architecture | Year | GPU Models | CPU Models | Key Advancement |
Upcoming | Feynman | 2028 | F100 | Vera Next | Targeted for the next wave of "Physical AI." |
Current / Future | Rubin | 2026 | R100 / Rubin Ultra | Vera (88-core) | HBM4 memory, 3nm process, 1.8 TB/s NVLink. |
Newest | Blackwell | 2024-25 | B100, B200, B300 | Grace (72-core) | First "dual-die" GPU; 208 billion transistors. |
Legacy / Mature | Hopper | 2022-23 | H100, H200 | Grace | Introduced the "Transformer Engine" for LLMs. |
The Stock Price Hit a Ceiling
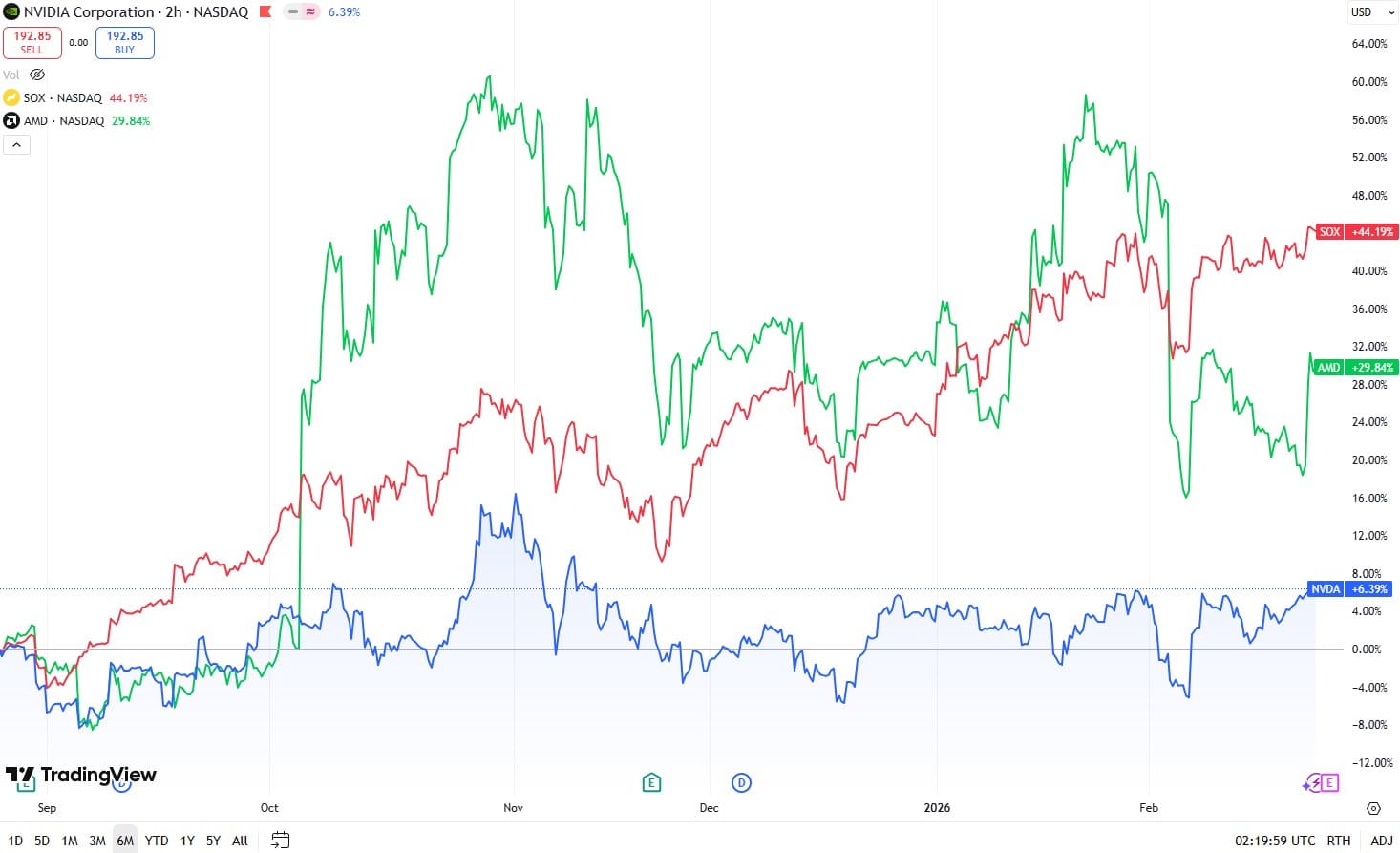
Source: TradingView
Despite these "impressive numbers," NVIDIA’s stock has only climbed 10% over the last six months. To put this in perspective, its primary rival AMD is up 23%, and the broader SOX semiconductor index has surged 48% in the same period. This underperformance is particularly puzzling given that the "hyperscalers"—Amazon, Alphabet, Meta, and Microsoft—all significantly increased their capital expenditure (Capex) guidance for 2026.
Logically, more Capex from these tech giants should equate to more revenue for NVIDIA GPUs. Yet, when Amazon announced a 56% increase in Capex to $200 billion, NVIDIA’s stock remained flat. Similar reactions followed massive guidance increases from Alphabet (+98%) and Meta (+74%).
Company | 2026 Capex Guidance | YoY Increase | NVDA Price Reaction |
Amazon | $200 Billion | +56% | Flat / -1.2% |
Alphabet | $180 Billion | +98% | Flat / +0.5% |
Meta | $125 Billion | +74% | Flat / -0.8% |
Microsoft | $140 Billion | +59% | Flat / -2.1% |
The Threat of Vertical Integration: Google’s TPU
The most prominent threat to NVIDIA’s dominance comes from Google’s Tensor Processing Units (TPUs). Google has successfully demonstrated that it can bypass NVIDIA for its most critical internal workloads. Currently, Gemini 3 and 4 are trained almost entirely (95-100%) on Google’s internal TPUs, with NVIDIA GPUs handling effectively 0-5% of that specific workload. For internal inference tasks, such as those powering Search and YouTube, TPUs still handle roughly 85-90% of the volume.
This shift creates a narrative shift for investors: if the leader in AI models is moving away from NVIDIA, will others follow? However, the reality is more nuanced when looking at Google as two separate entities. While "Internal Google" is self-sufficient, "External Google Cloud" still relies heavily on NVIDIA to satisfy its customers. External clients continue to prefer NVIDIA GPUs for approximately 60-65% of their workloads, largely because Google TPUs may not fit their specific architectural needs or because they are locked into the CUDA software ecosystem.
Workload Type | % Handled by Google TPUs | % Handled by NVIDIA GPUs |
Internal AI Training (Gemini 3/4) | ~95% - 100% | ~0% - 5% |
Internal AI Inference (Search/YouTube) | ~85% - 90% | ~10% - 15% |
External Google Cloud (Customer Rents) | ~35% - 40% | ~60% - 65% |
The Rise of the AI CPU and the AMD Rivalry
As the AI industry matures, the focus is shifting from training models to "inference"—the act of running a trained model to answer user queries. In this new phase, the Central Processing Unit (CPU) is regaining relevance. Unlike training, which requires the raw parallel power of a GPU, inference often involves "branchy" logic—a series of rapid "if/then" decisions that CPUs are better equipped to handle.
This shift plays into the hands of AMD, whose CPUs are often considered more powerful and cost-effective on a standalone basis compared to NVIDIA’s "Grace" or "Vera" offerings. In the current market, many external cloud clients use a "hybrid" approach: NVIDIA GPUs paired with AMD CPUs. This "a-la-carte" business model offered by AMD contrasts with NVIDIA’s "set meal" approach, where they attempt to sell the GPU and CPU as a tightly integrated package.
NVIDIA’s goal is to break this hybrid trend by proving that their own CPUs (like the Vera model) work better within their ecosystem than a third-party AMD Venice CPU. While AMD wins on "raw logic" and IPC (Instructions Per Cycle), NVIDIA’s Vera CPU offers ultra-high power efficiency through its ARM-based architecture and is highly optimized for AI-specific software.
Preferred GPU | Preferred CPU | |
Google Internal Usage | Google TPUs | Google Axion |
Google External Clients | Nvidia GPUs | AMD CPUs |
Networking: NVIDIA’s Secret Weapon
The true strength of NVIDIA’s moat lies in a segment that is often overlooked: networking. Networking now represents about 15% of total Data Center revenue, or roughly $8.2 billion, growing at a staggering 162% year-over-year. This is NVIDIA’s "hidden weapon" because it creates the bridge between the CPU and the GPU that competitors struggle to replicate.
For example, when a client uses an AMD CPU with an NVIDIA GPU, they are limited by the speed of the PCIe 6.0 connection, which tops out at 128 GB/s. However, when using an all-NVIDIA stack (Vera CPU and Rubin GPU), the proprietary NVLink 5.0 networking equipment allows for speeds of 1,800 GB/s—more than 14 times faster than the standard connection.
Metric | AMD EPYC "Venice" | NVIDIA "Vera" CPU |
Raw CPU Logic | Winner (Higher IPC / x86) | Good (ARM Neoverse) |
CPU-to-GPU Speed | 128 GB/s (PCIe 6.0) | 1,800 GB/s (NVLink) |
Power Efficiency | High | Ultra-High (ARM) |
Software Choice | Open (Runs everything) | Closed (Optimized for AI) |
This performance delta is the primary catalyst NVIDIA is using to convince clients to switch away from AMD CPUs. If the speed of the whole system is the bottleneck, the "raw logic" advantage of an AMD CPU becomes irrelevant. Recent moves, such as Meta purchasing large quantities of NVIDIA CPUs, suggest that this long-term strategy to scale the CPU business via networking integration is beginning to take hold.
Conclusion
NVIDIA is no longer just a chip maker; it is a full-system provider. While the "GPU battle" was won years ago, the "AI CPU battle" is just beginning. The market’s current skepticism reflects the fear that NVIDIA cannot dictate high prices or maintain dominance as the industry shifts toward inference and custom silicon. However, by integrating GPUs, CPUs, and high-speed networking into a closed, optimized ecosystem, NVIDIA is building a moat that is difficult to bridge with "a-la-carte" components. The upcoming earnings call will likely see CEO Jensen Huang emphasize this full-stack dominance as the key to maintaining their 75% margins despite rising competition.
Find out more