阿里未来生活实验室 投稿
量子位 | 公众号 QbitAI
MoE(混合专家模型)已经成为大模型时代的“版本答案”。
从GPT-5到DeepSeek-V3,几乎所有最强模型背后都有MoE的影子。
但你是否想过:你模型里那几十个“专家”,可能都在干同一件事?

在MoE预训练中,原本期望这些专家“各司其职”,最后发现他们竟然“同质化”了?学术界将这种现象称为“专家同质化”(Expert Homogenization)。这直接导致了MoE模型参数的浪费和Scaling能力的封顶。
来自阿里巴巴未来生活实验室的研究团队认为,这背后是MoE预训练过程中的信息缺失。
为了解决这一顽疾,来自阿里巴巴集团的研究团队提出了一种全新的专家分化学习(Expert Divergence Learning)策略。他们利用预训练数据中天然存在的“领域标签”,设计了一种新的辅助损失函数,鼓励不同领域的Token在路由统计信息上表现出差异,从而引导专家分化出真正的专业能力。
这一研究(Expert Divergence Learning for MoE-based Language Models)已中稿ICLR 2026。
核心洞察:多样性≠有效分工
为什么传统的MoE训练会导致专家同质化?团队在论文中揭示了一个被长期忽视的数学盲区。
现有的负载均衡损失(Load-Balancing Loss)虽然能提高总的路由多样性(Total Divergence),但它是一种“盲目”的提升。它只在乎“所有专家都被用到了”,却不在乎“是被谁用到的”。
这就好比公司发奖金,只看大家是不是都忙起来了,却不管是不是所有人都在重复造轮子。
阿里团队提出,真正的专家化,应该建立在“领域差异”之上。需要将总的路由多样性,通过数学手段引导到“域间差异”(Inter-Domain Divergence)上。
基于此,他们提出了专家分化学习(Expert Divergence Learning)。
硬核方法论:如何在预训练中强迫专家“分家”?
为了打破僵局,阿里团队提出了一种纯粹的、即插即用的训练目标函数——专家分化损失(Expert Divergence Loss, LED)。
它的设计灵感来源于一个优美的数学直觉:MoE的路由多样性是可以被“解构”的。
数学原理:多样性分解定理(Divergence Decomposition)
论文在理论部分使用了一个关键公式:
总多样性(Dtotal) =域间多样性(Dinter) +域内多样性(Dintra)
传统做法的缺陷:以前的负载均衡Loss只是盲目地推高左边的Dtotal。但在缺乏引导的情况下,模型倾向于通过增加Dintra(让同一个领域的Token乱跑)来应付考试,而不是增加Dinter(让不同领域的Token分开跑)。
新方法的Insight:LED的本质,就是精准锁定并最大化Dinter。它通过最大化不同领域之间的“排斥力”,分配总多样性的额度给“域间差异”,从而迫使专家发生功能分化。
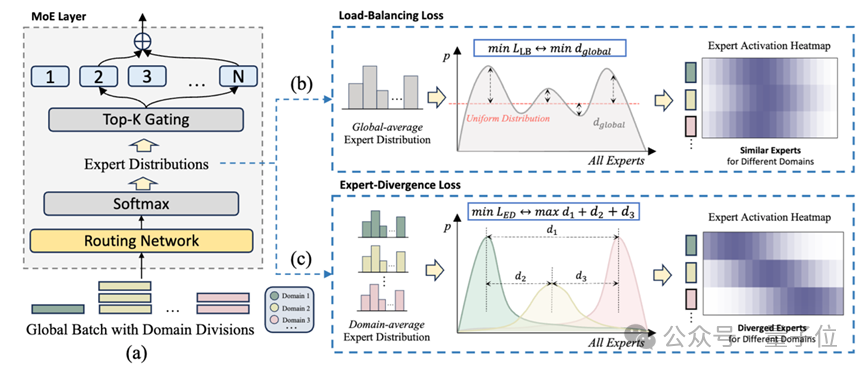
几何直观:把专家“推”向边缘
这个Loss的计算过程可以拆解为三步:
第一步:从Token到领域(Aggregation)在训练过程中,模型通常会接收到不同来源的数据(如数学题、代码片段、新闻)。算法首先计算出当前Batch中,属于“数学域”的所有Token的平均路由分布,以及属于“代码域”的平均路由分布。
第二步:计算“排斥力”(Divergence Computation)有了不同领域的平均路由分布,如何衡量它们的差异?团队选择了JS散度(Jensen-Shannon Divergence)。
JS散度是对称且有界的,非常适合用来衡量两个概率分布的“距离”。
如果“数学专家组”和“代码专家组”的人员构成高度重叠,JS散度就会很低。
如果它们使用的是两套完全不同的人马,JS散度就会很高。
第三步:最大化差异(Optimization)LED的最终目标,就是最大化所有领域对之间的JS散度。
这相当于给梯度下降过程施加了一个强大的“排斥力”:“数学题正在往1号专家那里跑,那么写代码的Token请尽量离1号专家远一点!”
通过这种显式的监督信号,模型不再是随机地分配专家,而是被迫学习出一种与语义高度对齐的路由策略。
粒度实验:49类标签>3类标签
这种分化学习,分得越细越好吗?
为了验证这一点,研究团队构建了两种不同粒度的领域标签体系:
1. 粗粒度(3-Class):简单分为英文、中文、数学。
2. 细粒度(49-Class):利用分类器将数据细分为49个具体主题(如物理、历史、计算机科学、法律、医学等)。
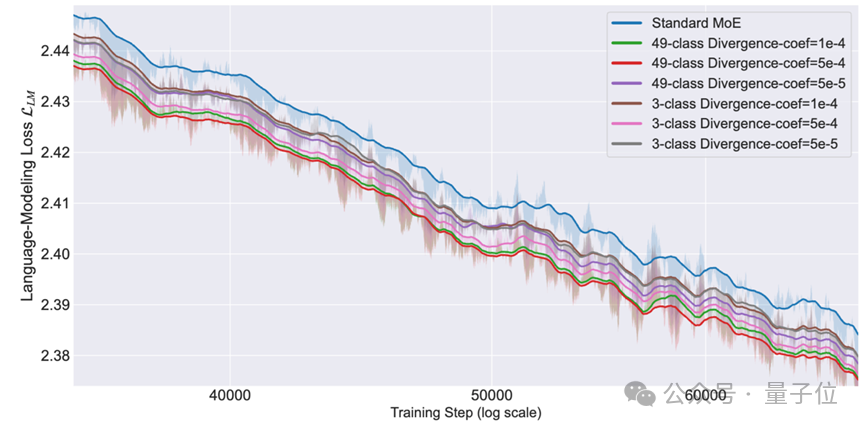
后续实验结果呈现出明显的“粒度缩放定律”:使用49类细粒度标签训练的模型,性能显著优于使用3类标签的模型。
这说明,给专家的分工指令越具体(例如:“不仅要区分文理,还要区分物理和化学”),MoE模型涌现出的专业能力就越强。
实验实锤:SOTA性能与可视化证据
研究团队在3B、8B、15B三种规模上,进行了长达100B Tokens的从零预训练(Training from scratch)。
在预训练阶段最重要的训练损失对比上,专家分化学习在语言建模损失上展现出来稳定且显著的训练收益。
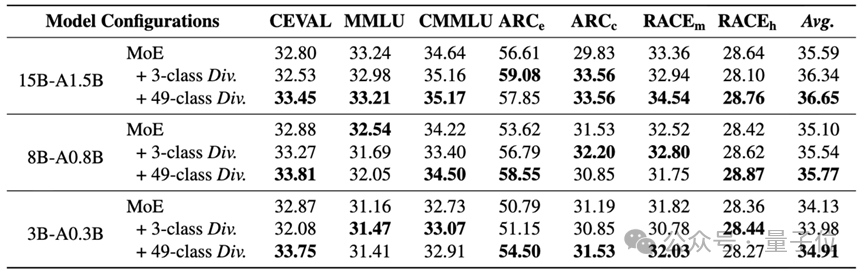
全面超越基线在MMLU、C-Eval、CMMLU、ARC等7个主流基准测试中,搭载了专家分化学习的模型全面超越了标准MoE基线。特别是在15B模型上,细粒度策略带来的平均分提升超过1个百分点——在预训练领域,这通常意味着数百亿Token的训练差距。
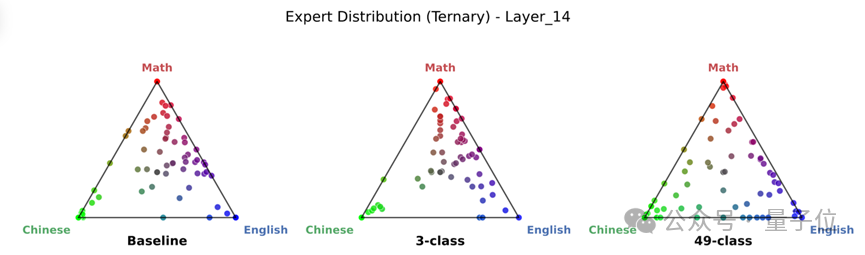
可视化:一眼看穿“伪专家”与“真专家”
为了直观展示专家是否真的“分家”了,团队绘制了极具说服力的三角单纯形图(Ternary Simplex Plot)。
下图中,三角形的三个顶点分别代表“数学”、“中文”、“英文”三个纯粹领域。
左图(Baseline):所有的点都挤在三角形中间。这说明无论输入什么领域,激活的专家都差不多,专家是混日子的“通用工”。
右图(Ours):点明显向三角形的三个顶点发散,紧贴边缘。这证明处理数学的专家、处理中文的专家,已经是两拨完全不同的人马,实现了真正的专精特新。
不仅效果好,还省资源值得一提的是,LED计算非常轻量级,仅涉及Router输出的低维向量运算。实验数据显示,相比标准MoE,新方法的训练吞吐量几乎没有下降(TPS保持一致),且额外推理成本为零。

总结
阿里团队的这项工作(Expert Divergence Learning),并没有盲目地堆砌算力或修改模型架构,而是从损失函数的数学本质入手,重新思考了MoE的“专家”定义。
它证明了:利用数据中天然存在的“领域结构”作为监督信号,是挖掘MoE潜力的最高效途径。同时,这种充分挖掘语料“立体结构信息”的训练范式,在高质量数据日趋枯竭的今天,或许能帮助预训练突破瓶颈,走向一个新的Scaling维度。