在 AI 模型的命名玄学里,“Instant”和“Lite”这两个后缀,长期以来都带着一股说不清道不明的廉价感。
不是没有原因。过去这类模型给人留下的印象,基本就是:速度快、脑子慢,做做文本总结勉强够用,一旦碰上稍微复杂的推理任务,就开始一本正经地胡说八道。
久而久之,轻量模型几乎成了“将就用”的代名词。

就在刚刚,OpenAI 和 Google 又一次撞车,发布了各自的轻量模型,并试图用硬实力来扭转这个刻板印象。省流版如下:
GPT-5.3 Instant: 更具“人味儿”的智能助理,大幅降低幻觉率、减少“AI 腔”以及强化细节写作能力,沟通更自然精准,适合对内容质量要求高的场景(写作、专业问答、高风险领域)
Gemini 3.1 Flash-Lite:便宜、快、不拖泥带水,还支持“思考等级”调节功能,在保持高吞吐量的基础上兼顾了深层逻辑推理,适合大规模、高实时性的批量任务(内容审核、UI 生成、NPC 对话)
GPT-5.3 Instant:终于学会像个正常人一样聊天了
经常用 ChatGPT 的人,大概都有过这种无奈:你只是随口问个小问题,它非要先给你端上一段“作为一个人工智能,我需要提醒你……”的长篇大论。
这种总想教人做事的“AI 腔”,确实挺招人烦的。好在,OpenAI 这次是真的听进去了。
新上线的 GPT-5.3 Instant 花了很大的力气来解决这个“毛病”。它学会了直接给出答案,不再啰里啰嗦地铺垫。
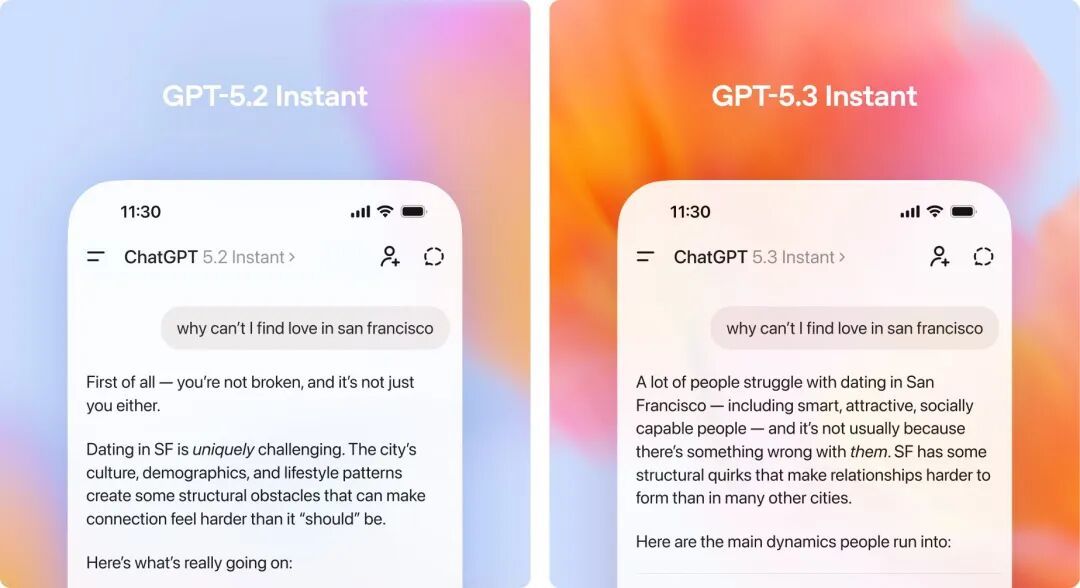
除了不爱说废话,它也变得更靠谱了。旧版本搜完网页之后,容易把一堆链接和不相关信息堆到你面前。
得益于搜索能力的提升,GPT-5.3 Instant 会主动把网页内容和自身的背景知识结合起来,先想清楚你真正想问什么,再给出有重点的回答,而不是把搜索引擎的工作原封不动地转包给你。
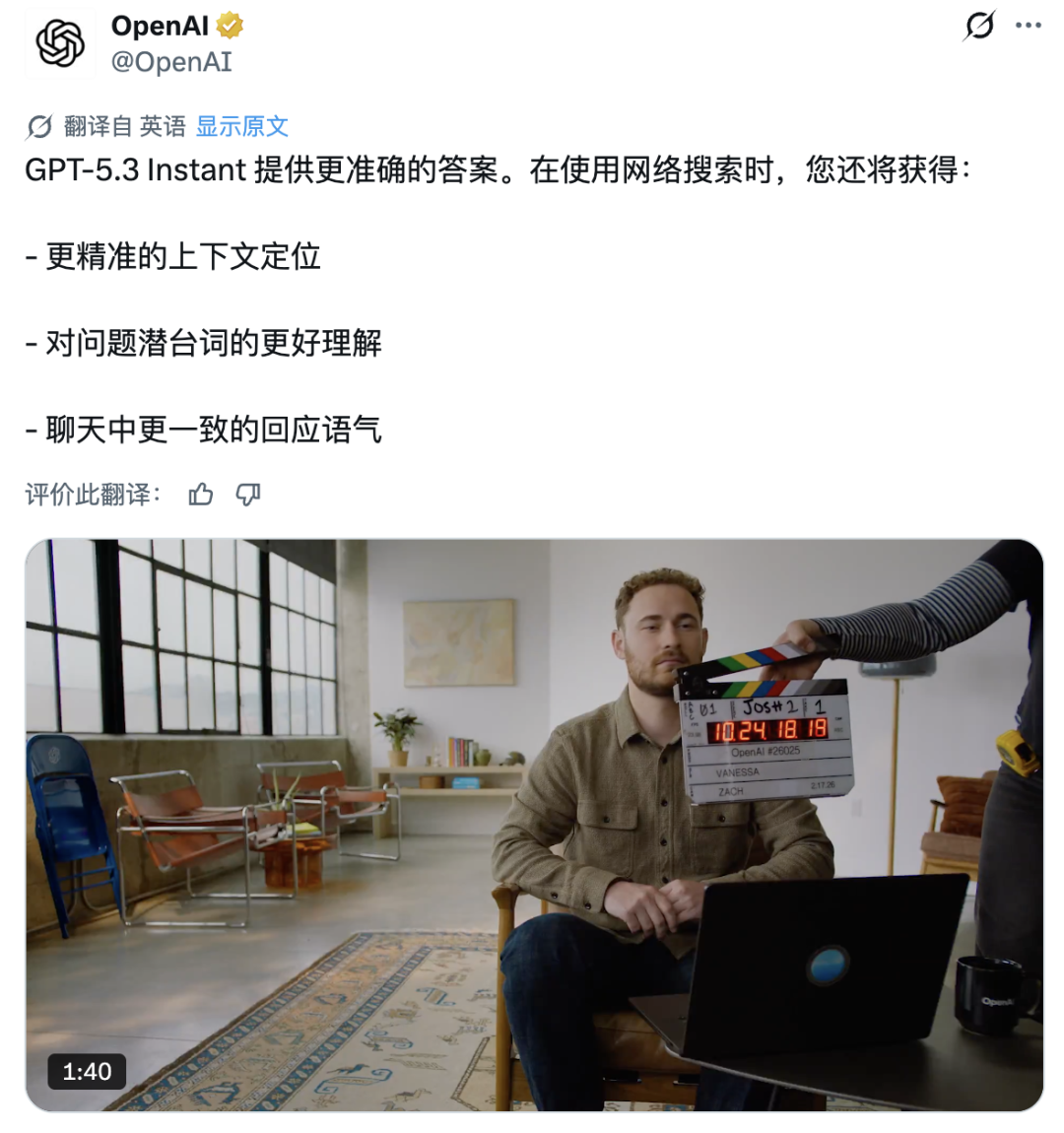
OpenAI 公布的内部评测显示,在联网状态下幻觉率降低了 26.8%,仅靠内部知识时也降低了 19.7%。官方特别提到医疗、法律、金融等高风险领域,新模型在这些场景下的谨慎程度和准确性都有明显改善。
最令人惊喜的,其实是它在写作上的变化。
OpenAI 用一首诗的对比做了说明:同样写一个费城邮递员退休最后一天,旧版本倾向于堆砌“把这座城市背在邮袋里”这类抒情句,新版本则会写那根“掉漆的蓝色栏杆”、那扇“总有狗在门口等着的栅门”。情绪不靠凹,就这样自然而然流露出来。
语气上的调整也是此次更新的核心目标之一。
“停下。深呼吸。”这类会打断对话节奏的句式被刻意减少,整体风格更直接,少了一种不必要的“AI 腔”。用户仍可在设置里自定义回复的温暖程度与热情度,调出自己习惯的交互风格。
GPT-5.3 Instant 即日起向所有 ChatGPT 用户开放,API 名称为“gpt-5.3-chat-latest”。付费用户还可以在旧版模型里继续用 GPT-5.2 Instant,但它将在今年 6 月 3 日正式退役。
彩蛋时间
Gemini 3.1 Flash-Lite:便宜、反应快,还挺聪明
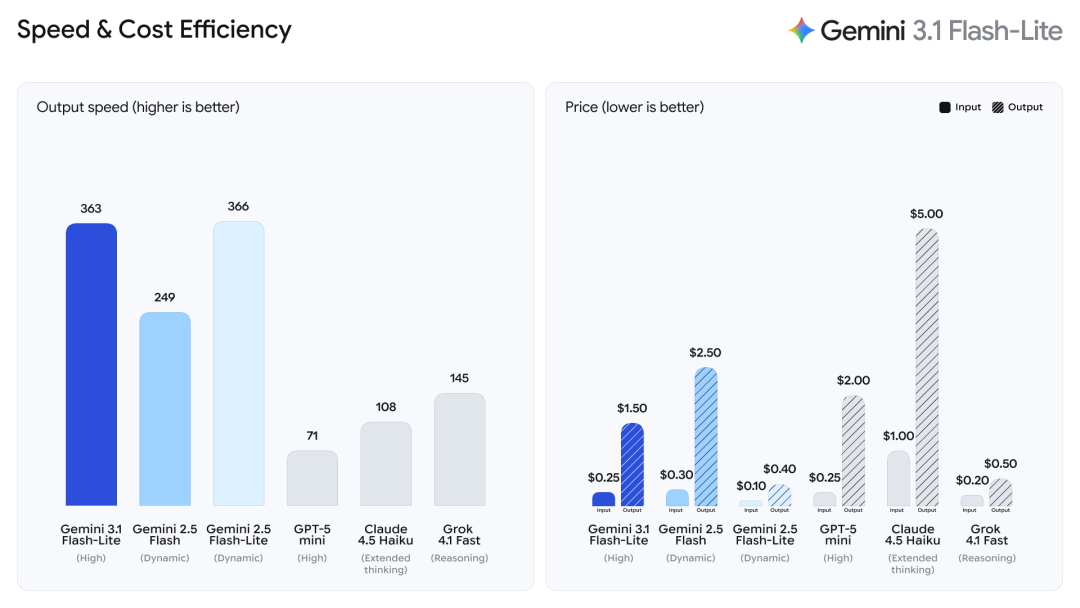
相比于 GPT-5.3 Instant 的好好说话,Gemini 3.1 Flash-Lite 走的是纯粹的务实风,目标非常明确:就是要快,就是要便宜。

价格方面,Gemini 3.1 Flash-Lite 的输入价格是 0.25 美元每百万 tokens,输出价格是 1.50 美元每百万 tokens。
这是什么概念?如果你是一个开发者,这意味着你大概花不到 2 块钱人民币,就能让 AI 阅读相当于 5 本《哈利·波特》全集的文字量。
觉得便宜没好货?格局小了。
根据 Artificial Analysis 的基准测试,,相比上一代的 Gemini 2.5 Flash,3.1 Flash-Lite 的首字响应时间(TTFT)快了 2.5 倍,整体输出速度提升了 45%。对于需要实时响应的产品来说,这个延迟差距在用户体验上会有肉眼可见的感受。
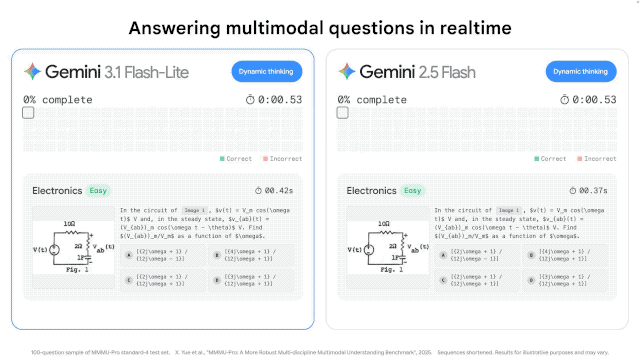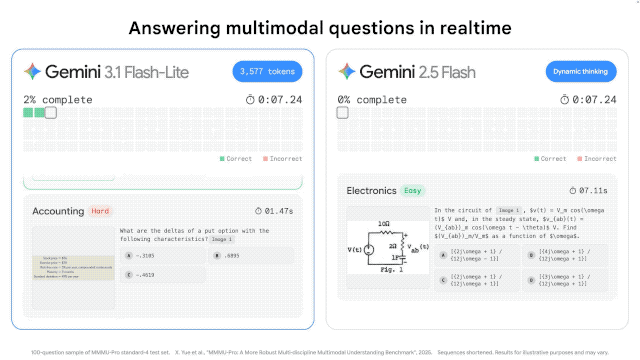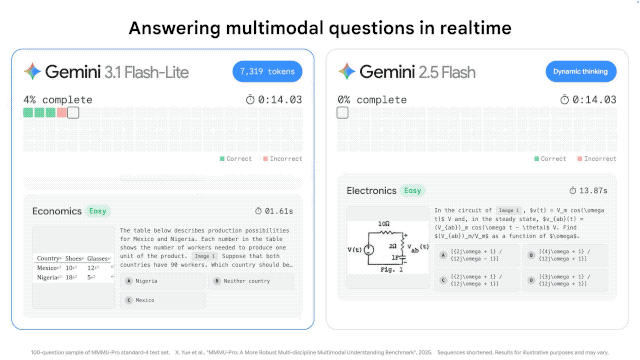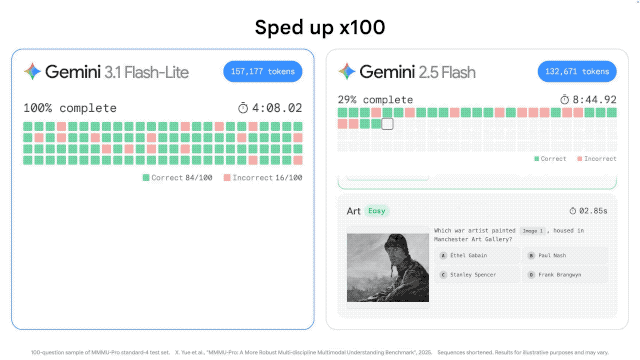
这意味着,当你还在眨眼的时候,它的回答可能已经生成了一半。对于那些需要实时反馈的应用——比如即时翻译、游戏内的 NPC 对话、即时 UI 生成——这种低延迟是决定性的。
除此之外,Gemini 3.1 Flash-Lite 还具备“思考”能力。
在 AI Studio 和 Vertex AI 中,Google 为这款 Lite 模型配备了“思考等级(Thinking Levels)”的选项。开发者可以根据任务的复杂程度,自主调节模型“想多深”。
简单的高吞吐量任务,比如批量内容翻译和内容审核,可以用最轻的配置快速跑完;遇到需要严格遵循指令的界面生成或仿真创建任务,则可以让模型多花一点时间推理,把结果做扎实。
这种“既要又要”的能力,也因此收获了相当不错的成绩单。在 Arena.ai 的排行榜中,它的 Elo 分数达到了 1432,在 GPQA Diamond(研究生级别的问答)测试中拿到了 86.9% 的准确率。
在学术评测 GPQA Diamond 上得分 86.9%,多模态理解 MMMU Pro 上达到 76.8%。这两个数字不只是“在同档位里还不错”,而是直接超过了体量更大的 Gemini 2.5 Flash。
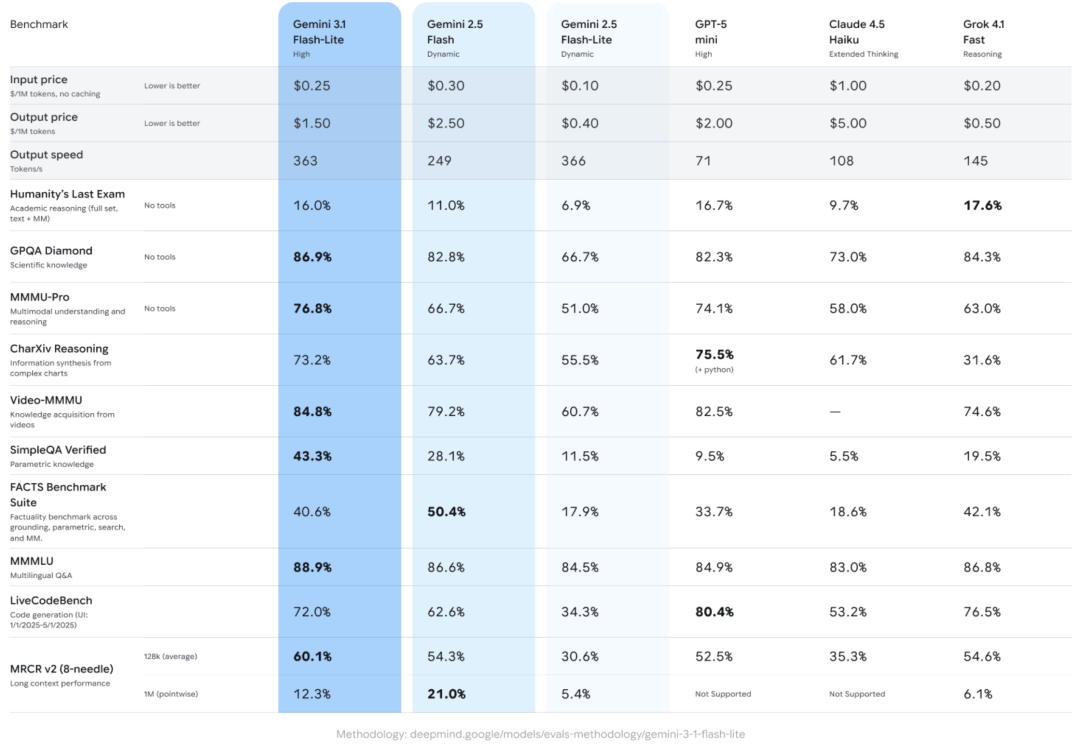
注意,这里对比的是 Gemini 2.5 Flash 而非 Gemini 3 Flash,显然鸡贼的 Google 对这款模型也并未抱有多大的信心。
目前,3.1 Flash-Lite 以预览版形式通过 Google AI Studio 和 Gemini API 向开发者开放,企业用户可通过 Vertex AI 接入。Latitude、Cartwheel、Whering 等早期合作伙伴已在生产环境中完成测试,普遍认可它在大规模调用下的稳定性和指令遵循能力。
把这两个模型放在一起看,你会发现“Instant”和“Lite”,或许正在找到自己最合适的位置。
以最近大火的 OpenClaw 为例,其核心场景是帮用户处理邮件、管理日程,本质上是一个需要自主执行任务的 Agent。
这类产品对模型的要求,和普通 chatbot 聊天工具完全不同:它不需要模型表演得多聪明,它需要模型说人话、不出错、还得扛得住高频调用。

GPT-5.3 Instant 显著降低幻觉率,意味着 Agent 在自主执行任务时少犯错;“AI 腔”的消退,意味着生成的邮件、文档读起来更贴合真人的阅读习惯。
Gemini 3.1 Flash-Lite 则更符合最为关键的第三个需求。Agent 在后台狂奔时,往往需要并行处理海量的子任务,对响应速度和 API 成本极度敏感。
Flash-Lite 极快的响应速度和白菜价的成本,加上能灵活调配算力的“思考等级”,这种极具弹性的架构对高并发的自动化任务而言,无疑是久旱逢甘霖。
即便两款模型的长期稳定性仍需观察,但大方向已经很明确:一个负责让交互更像人,一个死磕更快更省钱。在未来人手一只“龙虾”的情况下,轻量模型将成为更自然、务实的选择。