作者|首席人物观官方账号 二毛
在闫俊杰的认知体系里,一个产品要避免“全面优秀”。简单解释这句话,就是“不要把一款产品做成什么都沾一点、什么都不差,但也没有形成一个真正压倒性的东西。”
这不难理解。在创业里,偏科的尖子生,往往比全面发展的中级优等生更容易活下来。
但现在,闫俊杰需要警惕的是,MiniMax似乎正在成为一个“全面优秀”的公司——模型能打,价格够低,产品能跑通,商业化也有起色。但这些“都不差”加在一起,却无法回答市场一个问题:为什么非你不可。
而这,正是MiniMax现在最微妙的地方。
01 中级优等生
某种程度上,闫俊杰本人就是一个中级优等生。
他当然聪明。小学阶段就看初中的书,初中时又看高中,高中又自学了微积分。闫俊杰的父亲是一名中学老师,有段时间,还是小学生的闫俊杰就以给爸爸的学生辅导功课为乐。
一般来说,这类人后来通常会有两种走向。要么一路相信自己“天赋异禀”,要么很早就撞见更大的坐标系,知道自己不过是优秀里的普通人。闫俊杰更像后者。
上大学之后,闫俊杰发现周围有同学在数学方面的天分比自己高,“我不会成为一个很好的数学家了。”
这句话里有一个很重要的分寸:不是不能成为数学家,而是“很好的”那个位置,大概够不上。
后来的媒体访谈里,他曾表达过“做每件事都要做到极致”这样的观点,他的参考标准也永远是行业里成就最高的那一个——罗永浩在播客里夸赞MiniMax旗下的产品都在行业的第一梯队,他会补充“但跟第一还是有差距的”。跟晚点记者对谈时,对方夸赞他的论文在Google Scholar上有接近 3万次引用,他紧跟一句“最top的那个人可能是30万。”

图注:MiniMax成立第一天写下的初心和蓝图
这不仅仅是谦虚,更像是不太愿意在一个不够高的标准上停下来。
所以,当他意识到自己在数学上差着那一步时,没有在原地耗太久。转头开始思考另一个问题:什么东西我感兴趣,而且还和数学有关?
泡了一段时间的图书馆后,他找到了答案:人工智能(那时候还叫模式识别)。它离数学足够近,却又不像纯数学那样需要把人与人的差距过早地锁死在天分上。
对闫俊杰来说,这几乎是一种很早就形成的路径选择:在最吃天赋的位置上认清自己,然后退半步,换到一个仍与核心问题相连,却更奖励勤奋、耐力和工程能力,也更有机会实现突围的战场继续往前。
闫俊杰后来长期用过一个名字:IO。那是《DOTA2》里的一个英雄,上帝小精灵。这个英雄原本更常被放在辅助位,负责连线、补给、提速,不是传统意义上一眼看过去最锋利、最像主角的英雄。
但2019年TI决赛上,Ana把IO拿去打核心位,这让他们战队得到了那年的冠军。闫俊杰说当时觉得这个名字很酷,就拿来用了。
这个偏好放在他身上多少有点意思。因为想把IO玩得好,必须具备的素养里包括:全局意识,节奏判断,冷静思考,以及对于团队的理解和组织能力,而闫俊杰身上就有类似的味道。
这一定程度上解释了:为什么这个中级优等生可以在“天才如林”的AI圈里杀出重围。
02 承接
就技术单点突破而言,闫俊杰未必超越了“天才”,但在一件更难的事上,闫俊杰跑到了一些“天才叙事”前面:他走通了“自研Foundational Model+C端Agent应用(如Talkie/星野)+全球市场验证与变现”的路径,是目前亚洲大模型公司中,少数被证实拥有规模化全球收入的玩家。
财报显示:MiniMax 2025年总收入7900万美元,同比增长158.9%,其中AI-native产品收入5310万美元,开放平台和企业服务收入2600万美元,同比增长197.8%;全年超过70%收入来自海外,累计服务了2.36亿用户和21.4万企业客户及开发者。
确立这样的“全局意识”,源自于闫俊杰在商汤时的经历:
中科院博士毕业后,闫俊杰以实习生身份加入刚刚起步的商汤,仅用了两年多时间,不到28岁的闫俊杰就完成了从实习生到商汤科技研究院副院长的身份跃迁,更是主掌了商汤最核心、最庞大的“智慧城市”安防业务,也是在这个过程里,闫俊杰意识到“产品与技术同行”的必要性:
商汤的人脸识别、图像理解、AR技术,都曾是行业里最能打的那一批。到2021年,商汤对外披露,其AR技术在全球合作应用中的日活用户规模已经达到约1亿,微博、B站、小红书都在用它。

图注:闫俊杰(左一)在CVPR沙龙活动现场
问题是,这1亿日活不属于商汤,而属于那些真正拥有产品、流量和用户关系的平台。商汤提供的是能力,但能力被嵌进别人的产品里之后,用户感知到的往往只是“这个功能很好用”,而不是“这是商汤做的”。
“如果没有足够好的产品能力来承接,即使你有了一些技术进展,这些东西最终也不是你的。”闫俊杰生出这样的感慨。
除此之外,没有产品承接,公司的生存也将面临挑战。
智慧城市的业务很重,链条很长,交付复杂,技术看上去落进了真实世界,但商业上却并不好看。
根据商汤2025年上半年财报,商汤称加强了收款管理。公司称,大部分历史收入来自智慧城市业务,按账龄看,超过3年的贸易应收账款为39.97亿元,较去年年底的38.21亿元改善不大,2至3年的应收账款由去年年底的17.48亿元降至10.08亿元,2年以下的应收账款数额稍有上升。总起来,2025年年中的贸易应收账款为65.97亿元,较2024年底的69.74亿元稍有下降——聊胜于无的下降。
投资人圈子里曾经对“商汤系”创业者(如闫俊杰、Vivix AI 的刘宇等)有一个高度统一的评价:他们身上没有那种纯学者的清高,反而对“搞钱”、做产品和精细化运营有着近乎狂热的执念——
缺钱的苦,吃一次就够够的了。
所以到了MiniMax,这几乎成了闫俊杰重新定方向时最先修正的一件事:大模型和产品必须同时发力,技术不能悬在半空里,必须落到用户能感知的产品上。不仅要让产品把模型接住,同时公司还具备造血能力。
2023年,在高瓴的牵线下,前今日头条用户产品负责人张前川加入MiniMax,“字节基因”让这位产品经理人深谙流量变现,用户下沉心理、买量漏斗以及在产品里植入极其世俗的“抽卡(Gacha)”系统。
那也是MiniMax产品化动作最密集的一段时间:Talkie在海外长期是买量大户,投放素材累计突破10万条;到 2024年底,星野甚至一度登上AI App买量素材榜日榜第一。
这条路走到最用力的时候,MiniMax甚至像一家重新长在大模型上的互联网公司。到2025年前九个月,MiniMax面向个人用户的AI原生产品已经贡献了约71.1%的收入,第二大收入源甚至直接来自Talkie/星野的广告。
03 回调
但闫俊杰并没有在这条路上一直走下去,或者更准确地说,他很快又意识到,产品和增长这套东西一旦跑顺,公司就会在不知不觉中滑向另一种叙事:不是模型驱动产品,而是产品反过来定义公司。
“通过模型能力推动产品和业务变好,和通过移动互联网时代的经典打法让它变好,这两条路可能都是对的,但没法共存。”
这不难理解。因为它们争的是同一个方向盘:技术驱动是模型定义产品,产品驱动则是增长和运营反过来定义模型。两条路都能带来增长,但资源、节奏和判断标准完全不同,放在一家公司里,最后只会彼此拉扯。
一个曾经的失误后来被他反复提起:
2022年底,Glow出现了一个很小的算法bug,它把对话体验拉低约15%,直接导致DAU在三天里就掉了40%;问题修回来之后,用户又很快回来。这让闫俊杰认识到:在这一阶段,决定产品生死的,往往还是模型本身。
当然,最狠的冲击还是来自于同行。
2025年,没有大模型公司能逃过DeepSeek的冲击,MiniMax也深刻感受到了“震感”。DeepSeek用MoE、极致工程优化和开源,把“更低成本也能逼近顶级能力”这件事做成了现实。原来那套靠高价API和产品想象力支撑起来的安全感,被它一下子打穿了。
与此同时,MiniMax早期依靠Glow、Talkie/星野跑通的“产品反哺模型”模式,也开始显出边际——情感陪伴和闲聊数据可以让模型更像人,却很难继续把代码、推理、agent 这些决定下半场位置的能力往上抬。

换句话说,前一阶段产品能把公司托起来,到了下一阶段,真正决定你还能不能留在牌桌上的,还是模型本身。
闫俊杰再次校准,重新聚焦技术驱动。他一边公开承认海螺文本“没有坚持技术驱动”,年初定目标时还在套用移动互联网的逻辑;一边把M2.5这类主打coding、agent和低成本调用的模型推到台前。
而这次校准的代价,也很快反映在产品侧的人事上。
2024年9月,星野及海外版Talkie的产品负责人张前川淡出日常管理,转任顾问;2025年初,负责商业化的副总裁魏伟离职,官方的说法是“国内B端业务进入新的发展阶段”;再往后,连核心模型研发骨干也陆续出现变动。
几件事放在一起看,时间点并不随机:它们几乎都发生在 MiniMax开始重新把重心收回技术、收回底层、收回模型之后。
如果说前一个阶段,MiniMax需要的是能把产品跑起来、把流量做起来、把商业化做出来的人,那么这次校准之后,公司要的就不再是这些。当前端产品的边际开始显现,传统To-B的销售逻辑又被DeepSeek式的低价和开源冲得站不住脚,原来那套围绕C端爆发和B端兜售所配置的人,自然就开始失去位置。
人事变动不只是结果,它本身就是路线变化的一部分:当闫俊杰决定把公司重新拉回技术驱动,那些不再匹配这套新系统的角色,也就只能被系统本身一点点排出去。
这些是战略层面的校准,当然,闫俊杰在 MiniMax 里做的,远不止是“产品驱动”与“技术驱动”的来回切换,他更习惯把这种校准一路做到底层去:
早期MiniMax做得还是数字人方向,后又转向了多模态和基础模型;别人还在 dense 上反复打磨时,他押了当时并不算主流的 MoE;再往后,MiniMax 内部一度尝试过更省算力的 Linear Attention,最后发现这条路在复杂任务上撑不住,又硬生生校准回 Full Attention。
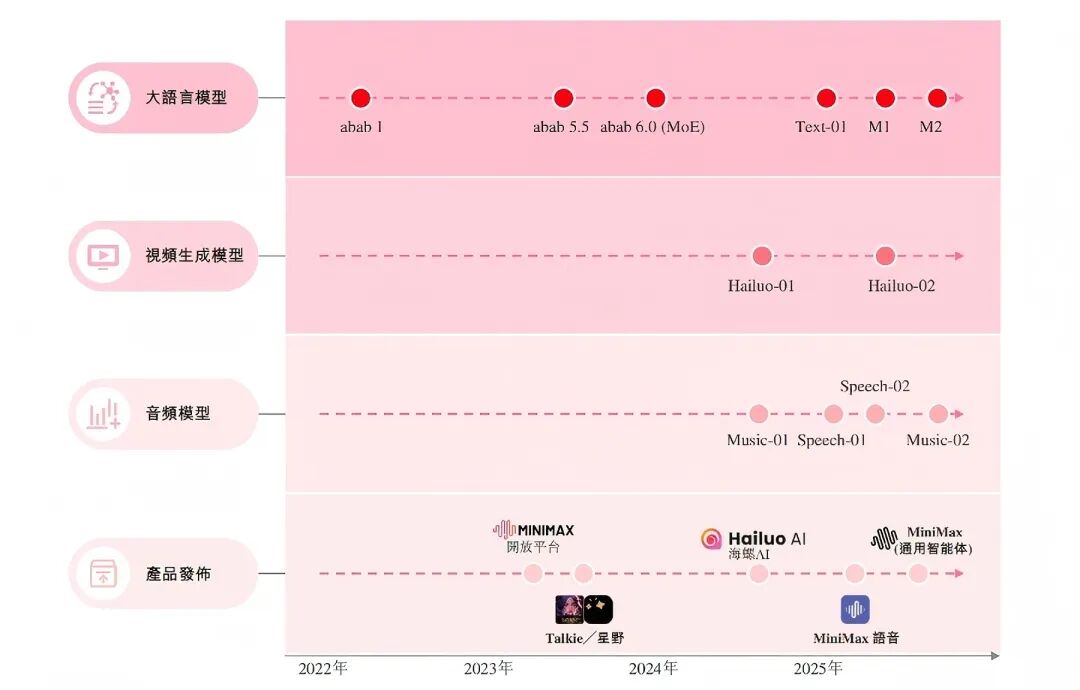
图注:MiniMax各产品线的发布时间
很多时候,他不是在选择一条已经被证明正确的路,而是在不断试错、不断回撤、不断把公司从一个局部最优里拽出来。
这套动作单独看都没有问题,甚至都很像一个技术出身的创始人应有的敏锐:方向偏了就修,架构错了就换,组织不匹配就调整。只是当这些校准一次次叠上去,MiniMax 也慢慢长出了另一种样子——
它几乎在每一个关键节点上都做了正确的事:模型上,M2.7已经站进国内第一梯队,价格还打得足够低;产品上,Talkie/星野、海螺都跑出过成绩,C端收入和全球化也不难看;商业化上,B端从2024年的870万美元增至 2025年的2600万美元,同比增长197.8%,增速快于C端 AI-native产品收入的143.4%,且公司还在主动补平台能力;战略上,它既做多模态,也做开放平台,既懂产品化,也重新收回技术驱动。
问题正在这里:这些优点单拎出来都成立,放在一起却没有长成一个压倒性的“第一”。在今天这个越来越奖励单点极致、奖励“偏科尖子生”的行业里,这种状态最危险的地方就在于:你几乎什么都能参与,却很难成为任何一场关键竞争里的唯一答案。
而这,恰恰是闫俊杰原本最该警惕的状态。
04 “全面优秀”
a16z(顶级风险投资公司,以投资包括Facebook、Twitter、Airbnb以及众多前沿科技企业而闻名)在2025 年对100位CIO(首席信息官)的调研里写得很直接:企业采购正在越来越像传统软件采购,买方会更严格地看评测、托管和benchmark,而不是只看价格;
同一份调研还提到,企业如今更成熟地“混用多个模型”,按性能和成本共同优化。
到了2026年初,a16z又给出一组更关键的数据:54%的受访者认为reasoning models(推理模型)加速了LLM采用,原因不是便宜,而是更快见效、更少prompt engineering、更容易接进内部系统,也因为准确性和可解释性而更值得信任。
在这种采购逻辑下,企业往往更愿意为“偏科但顶尖”的模型买单——把推理、代码、多模态等不同赛道的尖子生分别纳入体系,整体成本未必贵出多少,却能拼出一支性能近乎无短板的“模型舰队”;
相比之下,主打便宜、各项都不错但没有一项绝对领先的中等优等生,处境反而最尴尬——MiniMax刚好就有这样的尴尬。
目前为止,MiniMax最容易被市场记住的,是性价比。
我们横向比较几家主流模型的API定价:MiniMax M2.7/M2.5的报价是输入0.3美元、输出1.2美元/百万 tokens,明显低于OpenAI GPT-5.4的2.5/15美元、Claude Sonnet 4.6的3/15美元、Kimi K2.5的0.6/3美元,也低于智谱GLM-5-Turbo的5/22元人民币;它虽然不比DeepSeek-chat的0.27/1.10更低,但已经稳稳打进了第一梯队。
再看模型能力:
Artificial Analysis(AI基准测试和分析平台,被称为独立AI测试的黄金标准)上,MiniMax M2.7的Intelligence Index(智能指数)是50,和智谱GLM-5持平,比Kimi K2.5的47略高,但仍低于Claude Sonnet 4.6自适应版的 52,以及GPT-5.4、Gemini 3.1 Pro的57。
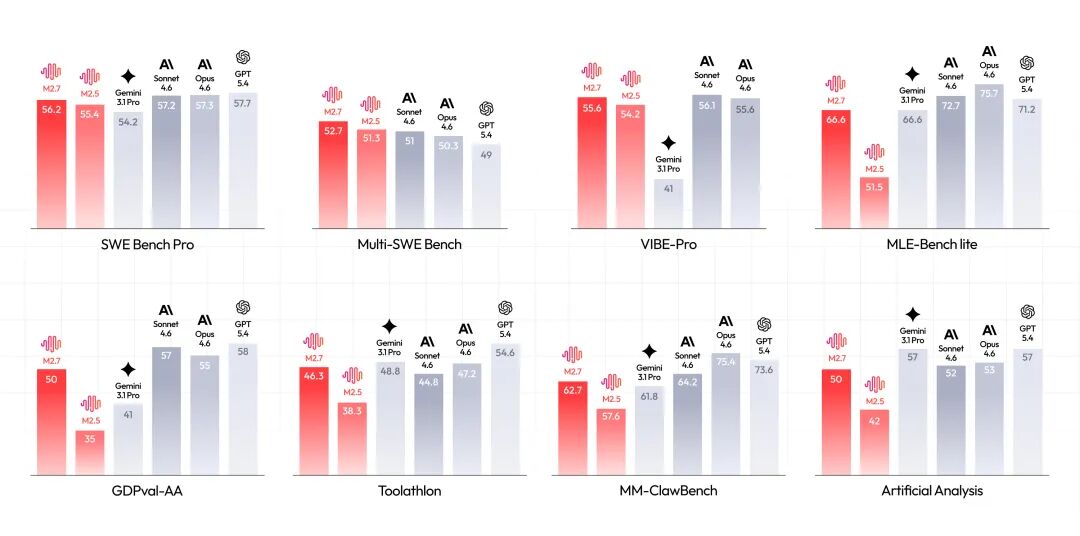
图源:MiniMax M2.7使用文档
往下一档,M2.5的Intelligence Index只有42,基本就是和GLM-4.7、DeepSeek V3.2同一区间;再往前一代,M2.1是39,被GLM-4.7的42、DeepSeek V3.2的41压住,更麻烦的是,M2.5虽然agentic表现提升,但它的 AA-Omniscience(Artificial Analysis用于评估模型在跨领域知识上的事实准确性和自我认知能力)指数从-30掉到 -41,幻觉率回升到88%;
到了视频端,Hailuo 2.3在Artificial Analysis的文生视频榜排第23、老的T2V-01甚至排到第49,离可灵、SkyReels 这些头部还有距离;图生视频榜排第20,谈不上头部统治力。
也就是说,除了M2.7(3月18日刚刚发布)这种少数单点突破之外,整个模型家族在文本、视频等主赛道里更多时候只是处在第一梯队边缘,很少形成持续、稳定、跨代际的领先。
大模型行业注定会是一场全球性的竞争,且MiniMax成立之初就确定了要走“国际化”路线,仅这一点就注定了它强敌环伺,没有“绝对主线优势”,便意味着很难同时拿到用户心智、商业定价权、资源配置权和长期生存空间。
MiniMax能够通过优化MoE架构,将M2.5/M2.7模型的混合定价强行压制到极低水平,这确实是极其优秀的工程胜利。但在当前极其透明的学术与开源生态下,这种工程优化的保密周期极短。
Artificial Analysis的报告显示,2025年Q3,40+ intelligence index区间的模型推理价格普遍下降了约 50%或更多,而且模型还在同时变得更智能、更快,这意味着“便宜”本身的半衰期极短。
Menlo Ventures(一家硅谷风险投资公司,领投了Anthropic)数据显示,Anthropic、OpenAI、Google 三家已经占到88%的企业LLM API使用份额,说明客户最终会把预算集中给那些“更强、更稳、更适配场景”的头部玩家,而不是长期奖励一个单纯靠低价取胜的供应商。
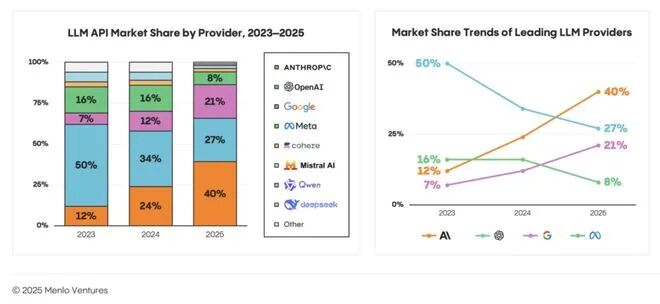
图注:企业LLM API使用份额
这提醒闫俊杰:工程能力当然重要,但到了下半场,真正决定位置的,还是技术能力本身。
闫俊杰在商汤时打过一场攻坚战:
那是商汤的人脸识别项目,他的起手并不漂亮。每次技术测试,他的成绩都排在后面,相当于考试时总考倒数,“而且当时公司最多的资源都是支持我来做这件事,”他说。对于一个优等生而言,这个过程中的压力与痛苦可想而知。
死磕了一年半,闫俊杰把这个项目做到了行业第一,并且在之后的每一次测试里,他的第一都巍然不动。
或许这就是他的做事方式:路一旦选定,接下来就是往里走,走到头。
闫俊杰今年37岁了,刨除掉漫长的求学生涯,“工程师”的身份伴随了他7年,后来,他又以“创业者”的身份存在了4年。罗永浩曾问他喜欢管理吗?闫俊杰的答案是这样的:不喜欢,因为管理带来的杠杆太低了,而做一些有突破的东西带来的杠杆更高,所以我不喜欢管理,但喜欢研究组织。
学者的内啡肽来自于‘突破’,但企业家讲究回报率。从这个角度看,闫俊杰显然已经具备了企业家的属性:他依然相信技术,依然迷恋突破,但已经不再满足于把问题解出来,而是开始要求这些答案最终变成产品、收入、组织和市场位置。
只不过,MiniMax能不能因此逃开“全面优秀”的陷阱,仍然是另一道更难的题。