越来越多海外开发者及“龙虾”(OpenClaw)用户,对中国大模型愈发青睐,从而引发中国“Token出海”现象。
一名新加坡开发者,曾用美国模型公司Anthropic的旗舰模型Claude Opus 4.6编程,发现“好用但贵”,单日Token(词元,模型输入与输出基本单位)消耗数千万个,每日成本动辄上百美元。这名开发者转而拥抱中国大模型公司MiniMax的M2.5开源模型,干活性能相当,Token消耗所产生的费用却仅为美国头部模型的十七分之一。碾压级的性价比,催生高频调用。
此非个案,而是风潮。全球AI模型聚合平台OpenRouter是见证者。该平台允许开发者通过单一API(应用程序接口)访问全球超300款主流大模型,无需再为每个模型单独注册或适配接口。数据显示,近一个月来,在中美大模型API调用量的较量中,中国模型更胜一筹,调用量第一、第二和第四均为中国模型,分别为MiniMax M2.5、阶跃星辰Step 3.5 Flash,以及DeepSeek V3.2。另外,平台前十模型的Token总消耗量的60%以上来自中国模型。
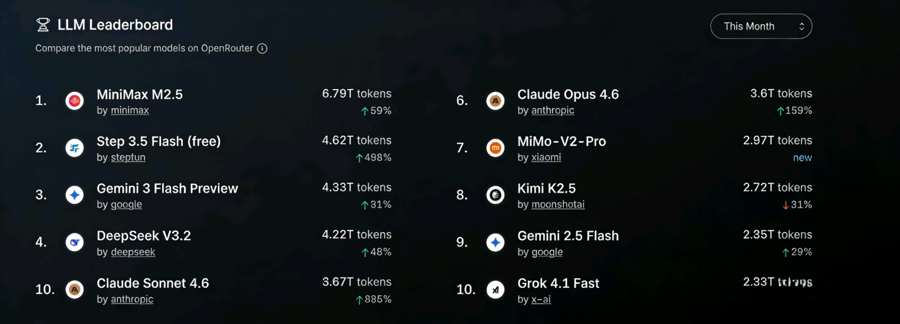
OpenRouter数据显示,近一个月来,在中美大模型API调用量的较量中,中国模型更胜一筹。
这意味着,全球开发者更喜欢调用中国大模型,愿意为调用所消耗的Token付费。大模型推理所需算力、电力均在中国完成,却创新实现了“Token出海”这一数字服务贸易形式。
这其中,我国低成本电力无疑是核心优势之一。利用乌兰察布、宁夏等地可再生能源丰富及气候优势,我国实行“东数西算”,绿电价格较美国电价低50%到70%,从而降低了数据中心运营成本。字节、阿里等大厂均在中西部地区布局数据中心。

腾讯贵州贵安七星数据中心。
但“Token出海”的更硬核辅助,在于中国大模型的技术实力,以及硬件厂商的高质量算力。
MiniMax多次登顶OpenRouter调用量第一,创始人闫俊杰本月中在2026上海全球投资促进大会开幕式上透露,MiniMax致力于AI普惠,早在“龙虾”大火前就定下目标:复杂Agent(智能体)运行1小时,成本1美元。

闫俊杰在2026上海全球投资促进大会开幕式上。
MiniMax的M2.5的确做到了。在编程最硬核的SWE-Bench Verified榜单上,M2.5拿到80.2%的高分,几乎逼平Claude Opus 4.6。但M2.5的推理速度是主流模型的约两倍,输入、输出价分别为0.3美元/百万Token、2.4美元/百万Token。也就是说,这个大模型不仅脑子好使,还不卡顿,更有极致性价比。
具体来看,其一,MiniMax率先投入资源,研究MoE架构,于2024年初上线国内首个基于MoE架构的大模型。此架构将模型分成多个专家子网络,视情动态激活,以节省计算开销。其二,在模型传统注意力机制中,Token长度与算力消耗呈平方关系。MiniMax成为全球首家敢于投时间、人力、算力资源,去验证“线性注意力机制”可行性、并最终用于大规模商业化部署的模型厂商,已实现Token长度增加后算力消耗的线性增长。其三,M2.5早在RL(强化学习)阶段,就引入MiniMax自研的Forge架构,从而绕过Agent场景下逻辑断裂、训练效率受重复前缀拖累两大痛点。
可见,中国模型实现能力、速度、价格之间的平衡,均基于颠覆式创新。
国内芯片企业同样励志,正全力适配自主创新大模型的研发。据记者了解,国内某头部模型厂商与国内自主芯片企业的合作算力已达数千卡规模,海外芯片正逐渐让位于国内芯片。国产GPU在易用性与成本上的综合优势,对于日均Token调用量上亿乃至十几亿的头部大模型而言,是其商业竞争力的关键因子。
据悉,这一波“Token出海”,寒武纪、昆仑芯、天数智芯等技术领先的芯片企业已率先实现适配及应用。如阶跃星辰Step 3.5 Flash等多款模型的推理和训练微调,均在天数智芯的通用GPU集群上完成,天数智芯加速卡还为多家AI企业大模型研发提供算力资源支撑。

天数智芯今年初在港交所上市。
在天数智芯副总裁宋煜看来,“Token出海”浪潮下,算电协同下的高质量算力,成为助力中国大模型持续提升全球竞争力的关键力量。他认为,评判高质量算力,有高效率、可预期、可持续三大维度。
高效率,指在真实训练和推理场景中,将电力、带宽、显存和互联尽可能转化为有效吞吐;可预期,指在大规模集群、复杂业务负载和功率约束下,算力性能、时延和稳定性能被准确评估并持续兑现。如天数智芯有业内独家的IX-SIMU全栈软件仿真系统,可在集群部署前仿真模拟实际运行效果,从而避免盲动,减少“上线后发现不行”的风险;可持续,则指芯片不只跑今天的算法,还能持续向“后”兼容。当前大模型几乎“三月一迭”,算力芯片须尽力适配,保障客户在采购后能支撑后续新模型的运行。
大模型推理,产出的是代码、分析、翻译和创意,是一种更深层的嵌入。一旦开发者对模型形成习惯,其切换成本会随时间积累而越筑越高。此番Token高质量出海,大幕刚刚拉开。
(文章来源:上观新闻)