文|强调Next
这是过去一年里Meta最需要一个好消息的时刻。Llama4的基准造假丑闻让开发者社区彻底寒了心,旗舰项目Behemoth迟迟没有下文,与此同时OpenAI、Anthropic和Google的军备竞赛越打越猛。
扎克伯格今天把Muse Spark推到了台前。
这是Meta超级智能实验室(MSL)交出的第一份答卷,也是汪韬(AlexandrWang)加入Meta九个月后,第一次向外界证明这笔143亿美元的赌注没有白下。发布当日,Meta股价盘中最高涨超10%,收涨约9%,市场给出了它想看到的那个答案。
一、九个月,从废墟里盖起来
要理解MuseSpark,先得理解它是怎么来的。
去年夏天,Llama4的基准测试被抓了现行:Meta承认拿了针对特定任务微调的专用版本去刷分,普通用户能用到的那个,跟公布的数据压根对不上。这件事对MetaAI的品牌伤害不小,但更深的问题在于,就算没有造假,Llama4也没能在前沿模型序列里站稳脚跟。
扎克伯格再次推倒重来。
他找来了时年29岁的ScaleAI联合创始人汪韬,花143亿美元买下ScaleAI49%的非投票股权,把汪韬塞进Meta首席AI官的位置,同时成立Meta超级智能实验室,从OpenAI、Anthropic、Google高薪挖人,据报道部分研究员的薪酬包含股权在内达到数亿美元。
然后是整整九个月的沉默。
汪韬在X上写道:“九个月前,我们从零开始重建了AI技术栈。新的基础设施、新的架构、新的数据流水线。”不是在原有基础上打补丁,是字面意义上的重头来过。
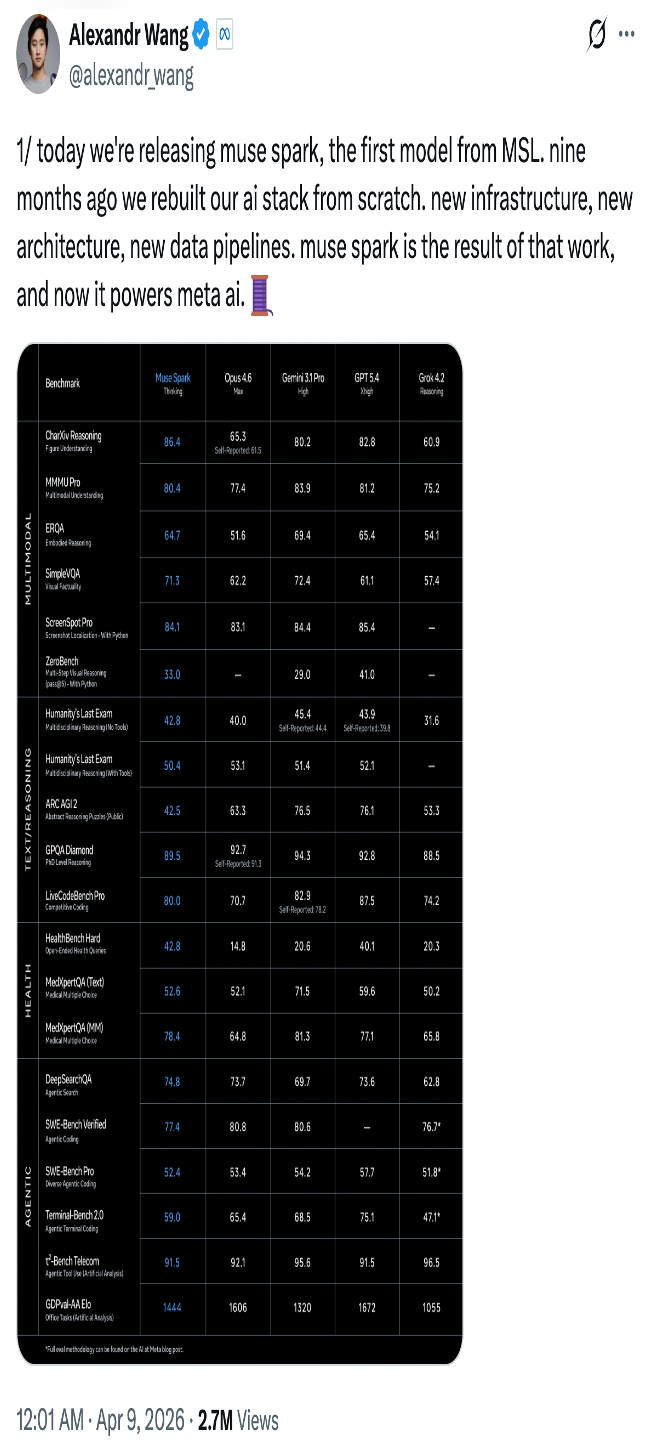
结果就是MuseSpark。内部代号Avocado,是Meta新Muse系列的首个型号,定位轻量、快速,但具备完整的推理能力。
二、“思维压缩”:效率才是真正的护城河
Muse Spark最让人意外的数字,不是某个基准测试的排名,而是计算效率。
Meta声称,Muse Spark达到Llama4Maverick同等性能水平所需的计算量,减少了十倍以上。背后是一种叫做“思维压缩(ThoughtCompression)”的训练技术:在强化学习阶段,对模型过度思考的行为施加惩罚,迫使它用更少的推理token解决同样的问题,同时不牺牲准确率。
这件事的战略意义比表面看起来大得多。
AI军备竞赛进入2026年,算力成本依然是最核心的约束之一。Meta今年的AI基础设施支出上限调至1350亿美元,比上年几乎翻倍。但光砸钱不够,烧得更高效才是差异点。如果十分之一的计算量能跑出同等智力水平,那意味着同样的预算可以跑更多次实验、迭代更多代模型。
从这个角度看,“思维压缩”不只是一个技术细节,它意味着这套新架构是可以规模化的。
三、偏科的“视觉天才”
评估一个新模型,先看它的长板和短板分别在哪里。Muse Spark的性格相当鲜明。
长板:多模态与健康
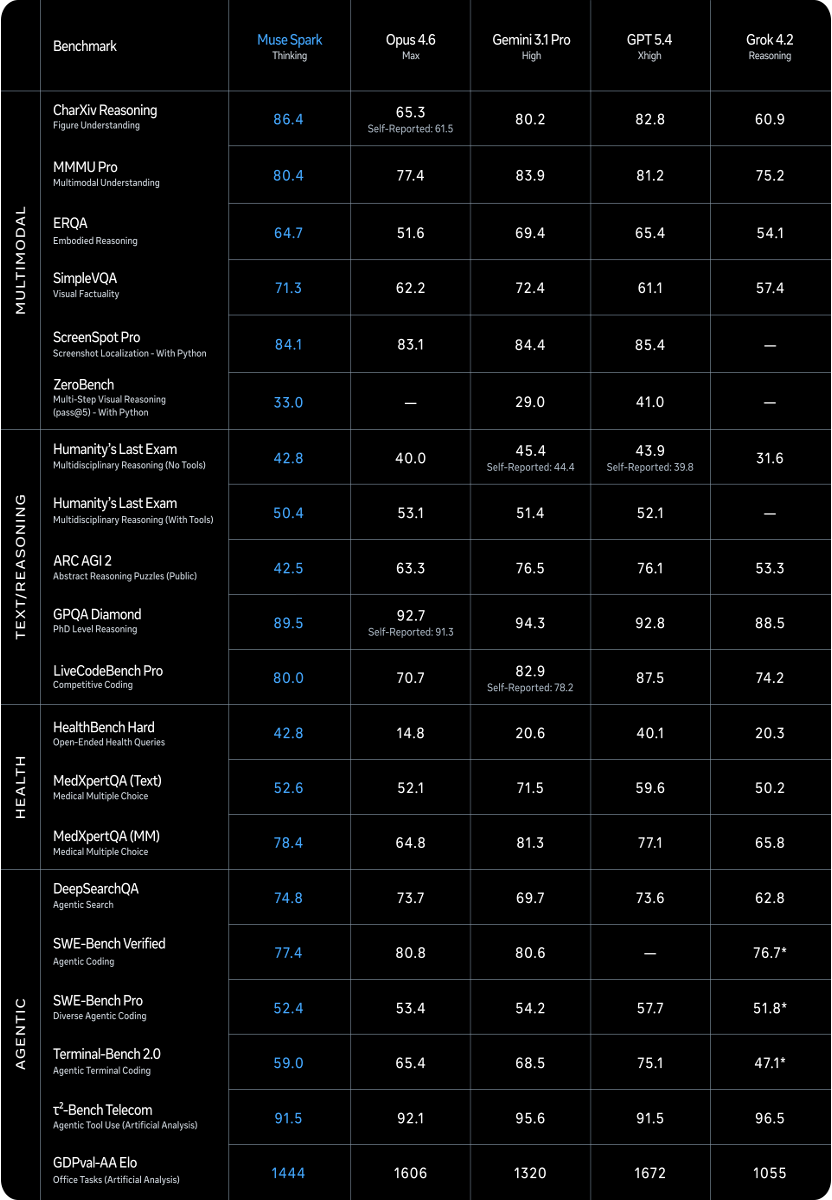
第三方机构ArtificialAnalysis的独立评测,给Muse Spark打出了52分(满分参照系中),在IntelligenceIndexv4.0排名第四,位列Gemini3.1Pro(57)、GPT-5.4(57)和ClaudeOpus4.6(53)之后。
但在具体科目上,Muse Spark的多模态能力是真实的强项。视觉理解(MMMU-Pro)排名第二,得80.5,仅次于Gemini3.1Pro的82.4。图表推理(CharXivReasoning)得86.4,力压Gemini的80.2和GPT-5.4的82.8,全场第一。
HealthBenchHard上,Muse Spark拿了42.8,超过GPT-5.4的40.1,把Gemini3.1Pro的20.6甩开一大截。Meta号称与超过1000名医生合作,专门为健康场景定制了训练数据。
短板:逻辑推理与代码
然后是短板,同样明显。
ARCAGI2(抽象推理):Muse Spark得42.5,而Gemini3.1Pro得76.5,GPT-5.4得76.1。差距将近一倍,这个分布不像是追分的问题,更像是架构层面的结构性缺口。
终端编程(Terminal-Bench2.0):Muse Spark得59.0,GPT-5.4是75.1,Gemini是68.5。Meta自己的技术博客里也直接承认,“长程agentic系统和代码工作流”是当前的重点投入方向。
三级推理模式
模型提供三种模式:Instant(即时)、Thinking(思考)、Contemplating(沉思)。Contemplating模式最有意思——它并行启动多个子智能体,分头处理任务再综合结论。Meta宣称在这个模式下,HLE(人类最后考试)得分达到58%,FrontierScienceResearch达到38%,能跟GeminiDeepThink和GPTPro在同一个场上竞争。
值得一提的是,Muse Spark的token效率也很出色——在IntelligenceIndex测评中使用了约5800万输出token,与Gemini3.1Pro相当,远低于ClaudeOpus4.6的1.57亿。
四、深水炸弹:这对DeepSeek意味着什么?
Muse Spark走向闭源,不仅是Meta的转型,更是全球AI生态的一次大洗牌。首当其冲的,就是一直以“开源高效率”著称的DeepSeek。
DeepSeek此前凭借极致的算力利用率在开源界封神,但Muse Spark提出的“思维压缩”直接在闭源侧把效率拉到了新高度。如果闭源模型不仅智力更强,连推理成本都下探到开源模型的水平,DeepSeek这种“平替”的性价比优势将被大幅削弱。
当然,Meta撤出开源,意味着开源界失去了一根定海神针。这给DeepSeek留下了巨大的市场空间去接管那些“被背叛”的开发者,但同时也让DeepSeek陷入了孤军奋战。没有了Llama作为行业标准,DeepSeek必须独自面对闭源巨头们更厚的技术壁垒。
不过,汪韬主导的这次重建,在多模态融合和推理效率上的思路,与DeepSeek追求的方向高度重合。这意味着接下来的竞赛将不再是“开源vs闭源”的意识形态之争,而是纯粹的、关于“谁能用更少的卡跑出更强的智力”的终极对决。
五、最大的新闻:开源时代结束了
从2023年开始,Llama系列是硅谷“开源AI”的精神图腾。开发者靠Llama做了无数应用,学术界用它做研究,初创公司用它起家,甚至竞争对手也拿它作为参照系。Meta在这件事上赚到的品牌资产,是其AI业务最重要的护城河之一。
Muse Spark放弃了这个护城河。
官方说法很温和:“我们希望未来版本能够开源。”但没有时间表,没有承诺,没有框架。当下这个版本,只能通过MetaAI应用、meta.ai网站使用,部分合作伙伴可以申请API私测资格。架构和权重不公开。
这是彻底的闭源。
从商业逻辑上不难理解。Meta今年AI基础设施支出上限1350亿美元,这个数字需要收入来支撑,单靠开源的生态声望显然不够用。当竞争对手的每一代模型都在拉开能力差距时,把最先进的架构创新保持私密,是避免自己的研发成果直接养肥对手的理性选择。
但从开发者社区的视角,这是一次背叛。Llama之所以有价值,恰恰因为它可以被下载、被修改、被本地部署。Muse Spark做不到这些。开发者失去的不只是一个可用的模型,而是一整套建立在Meta开放性信誉上的工作流。
汪韬在X上说得很直白:“这是第一步,更大的模型已经在开发中。”言下之意,Muse Spark只是Muse系列的起点,后面的Muse才是真正的重头戏。这个表述在技术上可能是真的,但对那些已经依赖Llama生态的开发者来说,这个“未来的承诺”能不能兑现不好说。
六、扎克伯格真正在下的那盘棋
把Muse Spark放在产品层面看,它有点像今天的字节。
个人超级智能,这是扎克伯格在Facebook帖子里用的词。Muse Spark将直接驱动Facebook、Instagram、WhatsApp、Messenger上的MetaAI助手,以及Ray-BanMetaAI眼镜。超过35亿人的触点,这是OpenAI和Anthropic没有的分发优势。
购物模式最能说明问题。MetaAI识别用户在Instagram上看到的穿搭或家具,结合用户的兴趣数据和行为信号,直接推荐商品并完成购买。这不只是个好用的功能,这是Meta的社交图谱和用户数据,第一次被系统性地接入AI推理链条。
健康场景的布局同样值得注意。与1000名医生合作定制训练数据,这是Meta试图在医疗健康信息领域占据位置的明确信号。这个场景的黏性高、用户需求真实,但同时也意味着隐私风险极高——用户需要用Facebook或Instagram账号登录才能使用Muse Spark,而Meta的隐私政策对于如何使用这些健康查询数据,措辞相当模糊。
从竞争格局来看,Muse Spark的发布时机很有意思。就在前一天,Anthropic刚刚公布了ClaudeMythos,初始仅向少数企业客户开放,重点指向网络安全防御。中国的Z.AI本周也在代码基准SWE-BenchPro上刷了新高。前沿AI的战线越来越宽,入局的玩家越来越多。
在这个背景下,Muse Spark想做的事,是把Meta重新钉回顶层牌桌——不一定是最强,但得够格参与对话。
七、Llama4的幽灵还在
最后还有一个问题,没有人能假装忘掉Llama4的基准造假。
那次事件之后,Meta对所有自己公布的测试数据都欠下了一笔信誉债。Muse Spark发布时附上了大量基准数字,ArtificialAnalysis也拿到了早期测试资格并独立评测。
但这个问题始终存在,你怎么知道这次是真实的?
Muse Spark的Contemplating模式,是所有用户都能用到的那个,还是又是一个专为基准测试微调的特供版本?
Meta说Contemplating模式会“逐步推出”,这个措辞留了太多解释空间。
结语
Muse Spark是一张入场券,不是终点。
它证明汪韬主导的九个月重建是有产出的,证明”思维压缩”这个新技术能跑出比Llama4Maverick高得多的效率,也证明Meta在多模态和健康领域找到了真实的差异化空间。
但它同时也是一个信号:Meta放弃了它在AI领域最独特的定位。Llama时代,Meta是那个把尖端模型免费开放给所有人的硅谷巨头,这件事让它在开发者心中的地位跟OpenAI和Anthropic完全不同。现在这个定位没了。
接下来Muse系列会涌出更强大的模型。更大的基建,更多的工程师,更高的算力密度。扎克伯格说得很清楚,这场赌局还在中场。
但有一件事已经确定:开源的Meta,结束了。