我每次翻《天龙八部》,翻到少林寺藏经阁那一段,都要停下来。
萧远山、萧峰父子对上慕容博、慕容复父子,鸠摩智再从旁搅局,三十年的血海深恨搅在一处,眼看就要分出生死。就在这当口,一个枯瘦的扫地僧走了出来。
萧峰的降龙十八掌打在他身上,他虽受内伤吐血,却以浑厚内力生生受之;他举手投足间让慕容博陷入“假死”复又救活,这种生死由心的境界,令在场一众顶尖高手莫不震慑失语。

这一刻,谁强谁弱,答案不言而喻。
AI 圈最近几年,流行把 DeepSeek(深度求索)比作这位老僧。在所有人眼里,AI 赛道的格局早已注定,海外有御三家,国内有大厂和彼时风头正盛的 AI 六小虎,轮不到旁人来置喙。
结果一家做量化交易出身的中国公司,悄没声儿地走出来,用一套从天而降的招法,在各项核心评测上与这帮人正面交手,打得有来有回。
只是,扫地僧出场,是《天龙八部》行将收尾的时刻。他的使命是终结纷争、化解戾气,然后全书走向尾声。可大模型的故事,没有尾声,也没有终章,只有下一回,还有下下一回。
把 DeepSeek 比作扫地僧,是对它过去的最高赞誉,但如果这三个字正在慢慢变成困住它的枷锁,我倒觉得,赞誉和催命符,有时候只在一念之间。
扫地僧是怎么练成的
金庸写扫地僧,从来不正面写他的功夫。他写的是别人的反应,萧峰愣了,慕容复愣了,旁观的人也愣了。高手的境界,要从旁人失语的瞬间才能传递出来。
DeepSeek 的故事,也暗合这个逻辑。
作为杭州的一家对冲基金,外人提到幻方量化,第一反应是期货、是算法交易、是数学天才们盯着屏幕上跳动的数字。这和 AI 大模型,八竿子打不着,却悄悄把一批工程师和研究员聚在一起做大模型。

2023 年 11 月,他们发布首个开源代码大模型 DeepSeek Coder,后续拿出了一个 67B 的语言模型。在官方给出的多项评测中,67B 超过了 LLaMA2 70B,67B Chat 在部分中文和开放式评测中优于 GPT 3.5。只是,圈内少数几个消息灵通的人注意到了,大多数人没注意到。扫地僧还在扫地,少林寺的人都在忙着练少林长拳。
让其开始崭露头角,是 2024 年 5 月 7 日发布的 V2。V2 用的是 MoE(混合专家)架构,总参数 2360 亿,但每次推理实际激活的只有 210 亿。与此同时,V2 首次采用了 MLA(多头潜在注意力)机制,大幅压缩了推理时的显存占用。
两相叠加,让模型在同等效果下,跑得更快,花得更少。用金庸的话来说,这叫以柔克刚,以精妙的内功路数,弥补了真气总量上的不足。

但砸出最大水花的,是定价。V2 的 API 定价,每百万 token 输入 1 元,输出 2 元。GPT-4 Turbo 当时是它的七十倍,Meta 的 Llama3 70B 是它的七倍。一块钱,一百万个 token,大约相当于一本《三国演义》的字数。
这个价格摆出来,让整个国内大模型市场为之色变。当月,字节、阿里、百度、腾讯、讯飞、智谱,一家接一家跳出来宣布降价,最高降幅 97%,部分轻量级模型直接免费开放。
一场持续了大半年的价格战,就这么被 DeepSeek 的一句定价点燃了。那时候,业内给 DeepSeek 送了个外号,价格屠夫。
美国的半导体咨询公司 SemiAnalysis 在那段时间写了一篇分析,说这家公司有可能成为 OpenAI 的对手,也有可能碾压其他开源大模型。当时读到这句话的人,大概有一半觉得是危言耸听。一年多以后回头看,没有人再觉得是危言耸听了。

2024 年末的 V3 和 2025 年初的 R1,则是连续出手的两招,把对手打得目瞪口呆。DeepSeek 用极低的投入,打出了旗鼓相当的效果。
更让人震惊的是参与人数,139 名工程师和研究人员完成了这个项目,而 OpenAI 同期有 1200 名研究人员,Anthropic 有 500 名。Meta 超级智能实验室负责人亚历山大·王后来说了一句被广泛流传的话,当美国人休息时,他们在工作,而且以更便宜、更快、更强的产品追上我们。
紧接着便是是 R1,主打深度推理,数学、代码、逻辑,在相当多的测试维度上与 OpenAI o1 不落下风,训练方法用的是 GRPO 强化学习,靠让模型自己想清楚来提升推理能力。

最要紧的一步是开源。
R1 的开源,被广泛解读为一种慷慨。模型权重、技术论文、训练细节全部公开,全球开发者共享成果。这套叙事里,DeepSeek 是那个敞开藏经阁大门的人,路不拾遗,人人可进。
武功秘籍直接摆桌上,谁想学谁来拿的这一手,也打破了少数几家巨头对前沿模型的垄断,让全球数以万计的中小开发者有了和顶尖模型掰手腕的资格。
金庸写扫地僧,主要抓住几样东西,出身边缘、多年隐匿、一鸣惊人、技法精绝、胸怀坦荡。DeepSeek V2 的价格屠刀、V3 的成本奇迹、R1 的开源普惠,也让人们在 DeepSeek 身上,真真切切地看见了那个老僧的影子。
枷锁,以及枷锁之后
但武侠小说是会结束的,AI 赛道不会。
每次我写 DeepSeek 的文章,底下的评论区都像藏经阁又打了一场架。有人说它安安静静做产品,不收费、不立人设,能用就用,这才是正道。有人说它连国产其他巨头都未必打得过,已经无法搅局。

有人替它抱不平,有人觉得它早就该被淘汰。更有人说,“我们一直以来都没把 DeepSeek 当作优等生,而是当作扫地僧,真心希望它能如我们所愿”,这句话说得又期待,又带着一丝说不清楚的悲凉。

意见如此撕裂,本身就说明了一件事。DeepSeek 所受到的关注,早已超出了一家普通 AI 公司应有的体量。捧它的人把它捧上神坛,骂它的人把它踩进泥里,没有几家公司能在舆论场里同时承受这两种极端。
这篇文章大概也逃不过同样的命运,有人会说这是黑稿,有人会说这是 PR 稿,落个两头不讨好。但这无所谓,舆论从来都是这样,藏经阁里打架,不管谁赢,总有人不服。

说回正题,扫地僧出场那一幕,是《天龙八部》收尾的信号。他出手,纷争平息,故事逐渐走向终章。这个叙事结构,似乎天然就带着一种大结局的气息,英雄横空出世,一招定乾坤,从此江湖太平。
根据《创智记》援引知情人士消息称,按照创始人梁文锋在内部透露的时间,DeepSeek V4 将于四月下旬正式发布。
爽文里的主角,每一章都要有突破,读者翻到下一页,期待的永远是更大的惊喜。
V3 和 R1 用四两拨千斤的逻辑征服了世界,大众于是开始把它当成 DeepSeek 的固定输出,每一次出手都必须让硅谷巨头血溅千里,都必须让英伟达的股价抖一抖。V4 也应当如此。

可在这等待一年多的时间里,外界等得有些躁动,各路声音都出来了,说一拖再拖,是不是黔驴技穷了,扫地僧要不行了?说这话的人认为 DeepSeek 理应每次出手都是奇迹,一旦慢了半拍,便是江郎才尽。
慢,自然有慢的原因。
3 月 29 日,DeepSeek 的服务器崩了将近十三个小时,创下网页端和 App 平台上线以来最长中断纪录。连续的服务事故暴露了 DeepSeek 在运维监控、应急预案和灾备机制上的明显短板,也给整个 AI 行业敲响警钟。

当然,综合各家报道来看,V4 一再推迟的原因,还藏在芯片层面。
V3 和 R1 的成功,一定程度上建立在成熟的英伟达 CUDA 生态上,DeepSeek 的工程师们在工具完备、文档详尽、社区活跃的环境里,把算法效率一点一点榨到了极限,每一步都踩得踏实。
V4 要做的事,是把这套功夫移植到国产 AI 芯片上。工具链还在快速迭代,底层接口和 CUDA 差异巨大,分布式训练框架几乎需要从头重构。
DeepSeek 交出的答卷,如果是在受限条件下做出来的,这让它的每一分成绩,都带着额外的含金量。哪怕梁文锋愿意为这件事多拖几个月,也是一笔非常划算的决策。
至于 V4 本身,《创智记》报道称,技术重心据悉落在了 LTM(长期记忆)能力的突破上,同时将原生多模态从底层融入架构,文字和视觉在预训练阶段就融合在一起。
另一个值得关注的变化,是梁文锋本人的注意力在悄悄转移。尽管在过去的一年里,包括 R1 的核心作者郭达雅在内的部分 DeepSeek 核心骨干陆续离职,不过根据《晚点 LatePost》的观察,DeepSeek 的人才基本盘依然稳固,并未出现大规模的人才流失现象。
进入 2025 年下半年,梁文锋也愈发看重技术的商业落地与产品化进程,积极招募负责 Agent 领域的策略产品经理。与此同时,他正在为公司启动估值,给员工的期权一个明确的锚点,让团队对未来有更清晰的预期。
综合上述种种动向不难得出一个结论:曾经心无旁骛盯着 AGI 的 DeepSeek 也得开始面对一家成熟科技公司必须面对的那些现实:商业闭环、生态建设、可持续的收入来源。
扫地僧可以几十年不问江湖俗事,守着藏经阁一扫到底,一家公司,没有这个选项。
《笑傲江湖》里的令狐冲凭着独孤九剑可以破尽天下武功,但当他真正坐镇恒山派,每天迎来送往,护佑门人,一招鲜远远不够,他需要的是内政、是人心、是香火代代相传的根基。奇招,解决不了日常的柴米油盐。

因此,我们应该主动帮 DeepSeek 卸下“扫地僧”这个名号。这三个字是对过去的最高褒奖,却是对未来的过重负担。即便 V4 发布时没有断崖式的领先,只是一款 LTM 扎实、多模态原生融合、各项指标均衡的水桶机。
从产业的角度看,这依然是巨大的成功,成功在于它或许将证明 DeepSeek 有能力从一个创造奇迹的挑战者,变成一个稳定交付的基础设施提供者。
有意思的是,这件事或许本来就是双向的。《晚点 LatePost》此前的报道里,DeepSeek 对外的沟通姿态明显比以往克制,既没有大张旗鼓地预热,也没有放出足以吊足胃口的技术信号。
这种低调,很难说是无意为之。
他们比任何人都清楚,扫地僧这三个字背后悬着什么。每一次出手若不能再掀翻整张牌桌,舆论的落差就会被无限放大。这是一种预期管理,也是一种自我解绑——他们同样不想再背着这个包袱走下去。
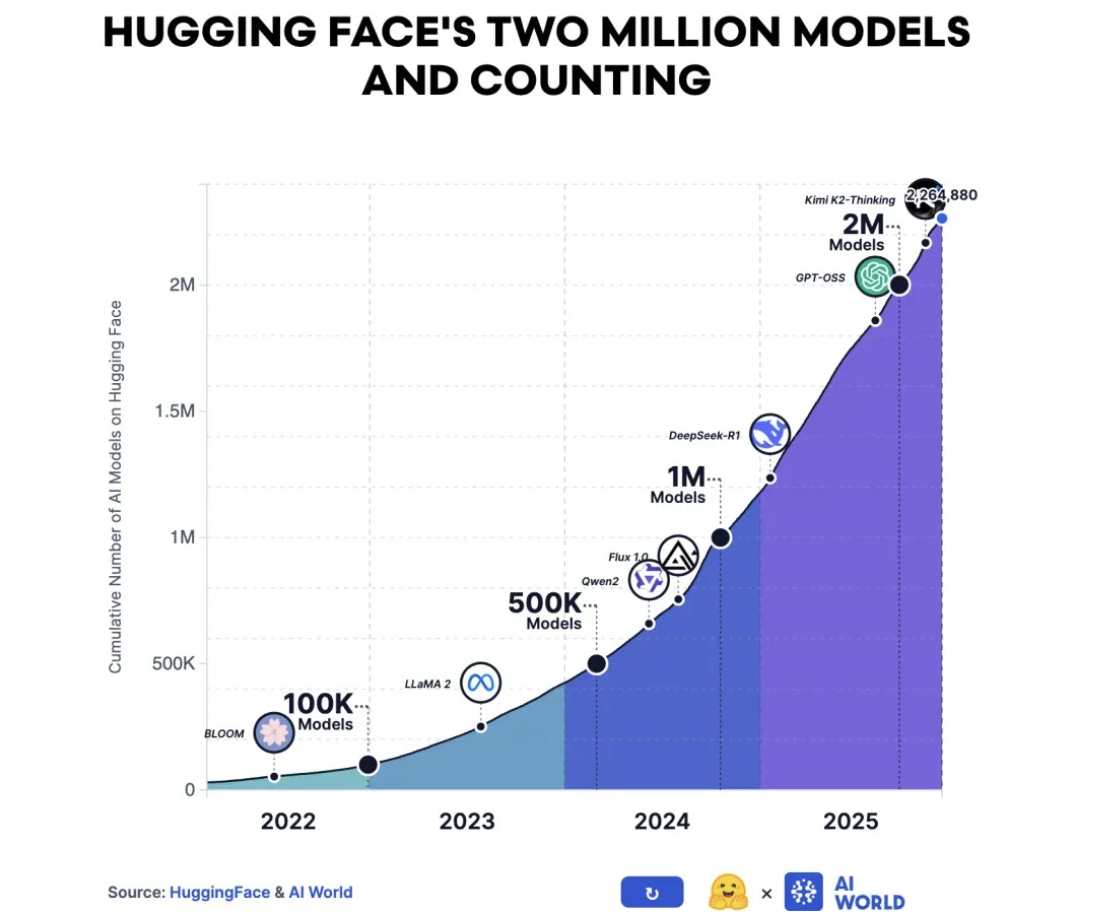
▲AI 模型的世界,已经从少数几家机构的专属游戏,变成了全球开发者共同参与的基础设施建设,而且这个趋势还在加速。
而话说回来,当舆论都在一窝蜂盯着 DeepSeek,却少有人往旁边多看一眼。

这片江湖里,国内每一家 AI 都在苦修内功,押注多模态、Agent 生态、算力布局,也都在各自的赛道上走出了自己的路数。
DeepSeek 固然是那个最让人心跳加速的名字,但把眼光只锁死在它一家身上,未免看窄了这个时代。真正让天龙八部成为天龙八部的,是那一整代人各有来路,各有绝学,彼此激荡,才撑起了那个波澜壮阔的时代。
扫地僧的传说,止于藏经阁那一战,藏经阁外,才是真的江湖。