
姚顺雨首秀为何与市场预期错位?
出品|虎嗅黄青春频道
作者|商业消费主笔 黄青春
题图|视觉中国
姚顺雨执掌腾讯混元后的首秀,最终被 DeepSeek-V4 的讨论淹没了。
4 月 23 日,腾讯正式发布并开源混元 Hy3 preview 语言模型——这是姚顺雨主导混元技术体系全面重建后,交出的首份落地成果。
在此之前,市场对姚顺雨的期待值早已拉满:清华姚班出身、OpenAI 前核心研究员、AI 领域顶尖专家,入职即获得集团层面双线汇报的最高权限,一手推动腾讯混元大模型研发架构重构,还打破盘桓多年的部门墙,让成立十年的 AI Lab 打散重组。
有鉴于此,外界翘首以盼腾讯拿出一款颠覆性的新模型,但 Hy3 preview 最终的市场声量与讨论度并不及预期。这很大程度上源于,同期 GPT-5.5、小米 Mimo、Kimi K2.6 等新模型密集发布,次日 DeepSeek-V4 也强势登场。
这让混元有限的声量彻底在这轮大模型更新浪潮中“失声”,业内因此有人揶揄腾讯,“不如关停混元,高价收购 DeepSeek”。
对此,腾讯内部人士向虎嗅透露,与外界期待姚顺雨“单骑救主”的英雄主义叙事不同,团队对这一版本并未设定过高目标,因为 Hy3 preview 并非对 Hy2.0 的迭代,而是腾讯混元技术体系的一次推倒重建。
“Hy3 预览版与 DeepSeek-V4 的核心差异在于,后者暂不考虑商业化,专注于突破技术上限;而混元从研发之初就以适配腾讯业务生态为核心,强调与场景的深度绑定。如今 AI 行业已进入下半场,模型能力、生态资源与工程化实力将形成协同效应——毕竟腾讯从来不是一家单纯的模型公司。”该内部人士表示。


腾讯终究“差了一口气”?

从官宣预热到最终发布,Hy3 preview 的表现与市场拉满的期待存在明显落差。
自高调宣布姚顺雨加盟以来,腾讯便对其展现了超乎寻常的重视:一人身兼“CEO/总裁办公室”首席 AI 科学家、AI Infra 部与大语言模型部负责人两大职务,同时向腾讯总裁刘炽平、技术工程事业群总裁卢山双线汇报。
这种人事安排在腾讯发展史上颇为罕见,等于从集团层面确立了大模型的战略核心地位,也向市场传递出腾讯 All in AI 的决心。
3 月 18 日的财报电话会上,刘炽平的表态更将市场期待推至顶峰:他明确透露混元全新技术体系下的旗舰模型 Hy3.0 正处于内部业务测试阶段,计划于 4 月对外推出,且相较于 Hy2.0 的能力提升幅度,将超过混元历史上任何一次版本迭代。
叠加 2026 年二季度全球大模型赛道进入新一轮密集发布期:Anthropic 发布 Claude Opus 4.7、阿里推出 Qwen3.6-Max-Preview、Kimi 开源 K2.6、小米官宣 Mimo 全系列新模型,GPT-5.5 与 DeepSeek V4 前后脚上桌——如此“神仙打架”的贴身肉搏,市场自然期待腾讯能拿出一款足以改写国内大模型格局的旗舰产品。
然而,与拉满的市场预期形成鲜明对比的是,Hy3 preview 虽踩点交付,但技术突破有限,在各个维度均未给市场带来预期中的惊喜。
首先,腾讯高管承诺 4 月推出核心版本,4 月底却只发布了 Hy3 预览版,勉强踩中时间节点,未体现出腾讯作为行业巨头应有的执行力与爆发力。
对此,腾讯内部人士向虎嗅表示,实际上 Hy3 预览版是技术重建的起点,正式版及更高级别的版本还在同步研发测试中。“Hy3 基本完成了对原有技术架构的全面重构,这个版本的核心目标是验证全新技术路线、磨合重组后的团队并跑通完整研发流程,且仅用不到三个月就完成交付,而行业同类技术重构通常需要 6-12 个月。”
其次,在行业动辄以 1T 参数炸场的当下,Hy3 preview 总参数 295B、激活参数 21B 的规格无法给市场带来冲击力,被业内人士吐槽不够顶尖、不够震撼。
从实测与行业评测结果来看,Hy3 preview 的综合能力虽达到国内一线水平,但极限推理能力仍逊于 GLM-5、Gemini 3.1 等顶级模型;代码与智能体能力仅相当于 GLM-4.7——也就是智谱 AI 四个月前的技术水平,既没有实现市场期待的代差级突破,更谈不上对标全球顶级模型。
可如果抛开市场的高预期滤镜,回归模型本身的技术与落地能力,Hy3 preview 已然是腾讯混元历史上进步幅度最大、实用性最强的版本。
推理效率层面,得益于模型架构与推理框架的深度协同,Hy3 preview 整体推理效率提升 40%,首 token 延迟降低 54%,端到端时长降低 47%,成本较上一代模型大幅下降——等于说,决定用户体验与商业化可行性的核心指标均被大幅优化。
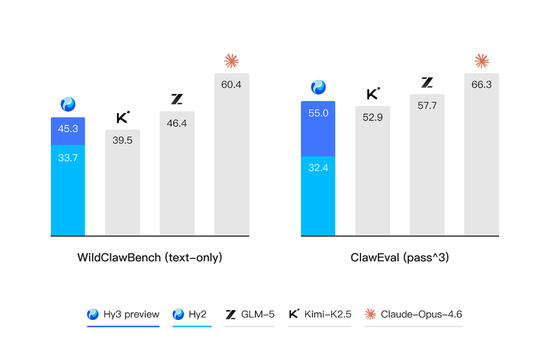
复杂推理能力层面,Hy3 preview 在 FrontierScience-Olympiad 拿下 70.0 分、IMO Answer Bench 达到 84.3 分,整体表现超过 GLM-5、Kimi-K2.5,接近 Gemini 3.1 Pro 与 GPT-5.4。
代码与智能体能力是 Hy3 preview 提升最显著的方向。在 SWE-Bench Verified 基准测试中达到 74.4% 的通过率,逼近 GLM-5 与 Kimi-K2.5;在 Terminal-Bench 2.0 测试中取得 54.4% 的得分,超过 GLM-4.7 等模型,挤进行业第一梯队;在涵盖 16 项基准的 Agent 综合评测中,平均得分从 Hy2 的 35 分跃升至 56 分,接近 GLM-5 与 Kimi-K2.5 所在的旗舰区间。
这些能力跃升背后,是 Hy3 preview 从研发之初就确立了与产品深度协同设计(Co-Design)的研发路线。
虎嗅获悉,Hy3 preview 发布之时,已率先接入腾讯云、元宝、IMA、CodeBuddy、WorkBuddy、QQ 等十余条核心产品线,且在每一个落地场景中都拿到了可量化的业务成果。
在办公场景,腾讯文档 AI PPT 功能接入后,生成成功率提升 20%,评测得分提升 10%,生成耗时缩短 20%,在模板选择、内容生成、视觉匹配等环节幻觉显著减少,契合度大幅提升;WorkBuddy 产品接入后,与国内同尺寸模型的用户盲评胜率达到 56%,能稳定覆盖文档处理、数据分析、知识检索、工具链编排等复杂办公场景。
在社交与内容场景,元宝 APP 已与模型完成深度协同优化,提升了意图理解、文本创作、深度搜索的核心能力,能为用户带来更具“活人感”的交互体验;公众号 AI 分身场景中,模型在用户意图理解、复杂上下文承接、知识信息组织方面的能力显著提升。
在游戏场景,《和平精英》已全面接入 AI NPC 玩法,局外人设扮演场景中,模型能精准理解角色设定,输出高关联、高增量的交互内容;局内复杂对战场景中,回复节奏贴近真实玩家,展现了极强的稳定性与拟人化能力,累计体验用户已突破 1.1 亿。
除此之外,QQ 浏览器、腾讯新闻、腾讯客服等数十款腾讯核心产品,均在接入过程中,Hy3 preview 已真正融入腾讯业务生态,而非一款孤立的实验室模型。


务实主义的路线错位?

“Hy3 preview 是混元大模型重建的第一步。”在 Hy3 preview 发布的官方推文中,姚顺雨如是写道。
即便首秀没能刷出与腾讯影响力匹配的声量,并不意味着 Hy3 preview 是一款失败的模型。虎嗅认为,某种程度上,姚顺雨为混元制定的核心路线,与当下行业的狂欢逻辑、市场的期待方向,存在明显的偏移与错位。
腾讯混元团队向虎嗅表示,外界多是围观视角,难以体会此次技术重建之难——不仅要搭建全新的基础设施,还要更换整套训练范式,几乎等同于从零开始重做一个大模型。
“比如数据审核就是姚顺雨亲自抓的,在三个多月内主导完成了对过往繁杂、冗余 SFT 数据的全面去重与精细化管控。目前,模型效果已经取得阶段性进步,但仍存在一些已知问题,比如工具调用中的错误恢复能力不足,以及对推理超参数较为敏感。希望通过这次开源和发布,获得来自开源社区和用户的真实反馈,助力 Hy3 正式版进一步提升实用性。”上述人士说道。
事实上,姚顺雨入职腾讯后,对混元团队推行的第一项核心变革,就是否定“唯榜单论”的研发逻辑。他在内部会议上指出,过去混元模型过度追逐榜单成绩,甚至直接将打榜专用语料混入训练集,导致数据被严重污染,影响模型在真实场景中的表现。有鉴于此,姚顺雨为团队划出一条清晰的路径:不迷信打榜,更不用盯着榜单做事。
虎嗅独家获悉,今年 2 月,姚顺雨主导重建了预训练和强化学习的基础设施,并确立了模型研发追求实用性的三大核心原则:
-
能力体系化:不推崇偏科,即便是代码智能体这类单一应用场景,也涉及推理、长文、指令、对话、代码、工具等多种能力的深度协同。
-
评测真实性:主动跳出易被刷榜的公开榜单,通过自建题目、最新考试、人工评测、产品众测等方式评估和改进模型的真实战斗力。
-
性价比追求:实用性离不开商业合理性,通过深度协同模型架构与推理框架设计,大幅降低任务成本,让智能用得起、用得好。
与此同时,混元团队在继续扩大预训练和强化学习的规模,提升模型的智能上限,并通过与腾讯更多产品场景的深入协同设计,进一步探索基于产品场景的特色能力。
基于这一理念,Hy3 preview 跳出行业通用的公开评测体系,腾讯混元团队自建了 50 余个基准测试集,通过自建题目、最新考试、人工评测、产品众测等多种方式,综合评估模型的真实战斗力。
据虎嗅了解,腾讯专门打造了 CL-bench、CL-bench-Life、Hy-Backend、Hy-SWE Max 等一系列贴合真实业务场景的评测体系,核心目标只有一个:验证模型在真实场景中的可用性,而非实验室里的纸面跑分。
要知道,当下大模型赛道,公开榜单的分数是最直观、最易传播的能力证明,更是模型出圈、获得市场认可的保证——如果不打榜、不拿出碾压同行的榜单数据,市场就会默认你不具备对应的能力,普通用户更不会感知到你的技术进步。
拿 Hy3 preview 受争议的 295B 参数规格来说,这恰恰是姚顺雨“实用优先、放弃炸场”路线的体现。在行业普遍通过“堆参数、规模扩容(Scale Up)”实现能力提升的当下,姚顺雨选择反其道而行之:Hy3 preview 总参数甚至小于前一版本,核心资源并未投入到参数规模扩张上,而聚焦于数据质量的提升,近乎完成了对 Hy2 模型底座的重构。
这一反行业常规的演进路线,源于腾讯混元对技术实用性的判断:
-
能力边界:复杂推理、长上下文理解、指令遵循等核心实用能力,在 300B 参数量级已能充分释放,盲目扩大参数带来的能力边际收益已大幅递减。
-
成本控制:300B 级混合专家模型(MoE)经量化后可实现单机部署,而 1T 级模型必须跨节点运行,多机通信会导致延迟、吞吐和运维复杂度显著上升,推理成本更是相差数倍。
-
落地可行性:绝大多数商业场景可通过检索增强生成(RAG)、智能体(Agent)等工程手段弥补与顶级模型的能力差距,而 300B 级模型的低推理成本和低微调门槛,让私有化部署与行业定制化成为可能。
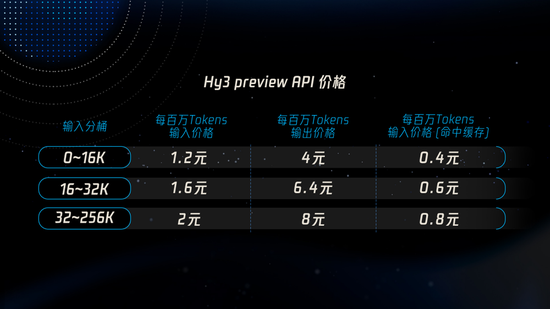
顺着上述判断,Hy3 preview 要将价格打下来:腾讯云公开的 API 定价,在 0-16K 上下文范围内,输入最低 1.2 元 / 百万 tokens,命中缓存后低至 0.4 元 / 百万 tokens,输出最低 4 元 / 百万 tokens;与此同时,推出的个人版套餐最低 28 元 / 月,在同级别旗舰开源 MoE 模型赛道中,处于最低价梯队。
然而,市场期待的是腾讯向上突破、拿出一款“碾压同行、对标 GPT”的顶级旗舰,期待看到巨头拿出炸场的参数、震撼的行业跑分,而非精打细算的性价比、面向落地的工程化产品。
这种市场期待与腾讯实际战略选择之间的错位,正是市场产生心理落差的核心原因。

当然,腾讯在 AI 赛道最大的底牌是其无可替代的生态体系与工程化能力,这也是市场始终对腾讯混元抱有逆袭期待的核心原因。
在生态层面,腾讯“两肋生风”:手握微信 14.18 亿月活的国民级流量入口,还有 QQ、游戏、办公、内容、金融等全场景应用矩阵,是国内拥有最多真实应用场景的互联网巨头——而真实场景的用户反馈、海量的业务数据,是模型迭代最核心的“燃料”。
在商业化层面,AI 正扛着腾讯业务跑:
-
2025 年腾讯广告收入同比增长 19% 至 1449.73 亿元,核心驱动力就是 AI 改写了广告业务的底层逻辑;
-
游戏业务收入同比增长 22% 达 2416 亿元,超 40 款腾讯游戏落地 AI 应用,覆盖研发、玩法、运营全链路,人效与收入均实现大幅提升;
-
腾讯云更是首次实现规模化盈利,大模型相关产品收入近两年增长 50 倍。
从最终结果来看,姚顺雨仅用三个月时间完成技术重建,并实现全业务场景快速落地,让此前掉队的腾讯混元重新跻身国内大模型第一梯队。他为腾讯混元制定的“不偏科、不刷榜、重性价比、深度贴合业务场景”研发路线,正契合 AI 行业从参数狂欢向落地实用回归的长期大趋势。
正如姚顺雨年初回应虎嗅的那样,大模型上半场竞争的核心是模型训练与参数突破,下半场的竞争重心将转向任务定义、系统构建与真实问题解决能力——从这个角度看,腾讯的生态优势、工程化能力、商业化体系,在 AI 下半场拥有巨大的想象空间。